Automatyzacja w obszarze Machine Learning dzięki MLOps

Podobno informatycy, czy programiści to mistrzowie automatyzacji. Spędzą 8 godzin na tworzeniu skryptu, który zaoszczędzi im 10 minut pracy. Jednorazowo. Czasem idzie to dalej i z takich skryptów robionych na kolanie ulepią cały pipeline, który robi wszystko od A do Z. Do czasu, aż któryś z kroków takiego workflow dostanie ciut inne dane na wejście i spadnie z rowerka.
Nie inaczej temat wygląda w przypadku wdrażania rozwiązań opartych o Uczenie Maszynowe. W pewnym momencie trwania projektu trzeba przejść z fazy eksperymentowania do fazy wdrożenia. Czy takie przejście wykonywane jest tylko raz? Czy możemy częściowo lub całkowicie automatyzować wdrażanie rozwiązania ML, od danych do końcowego produktu (wdrożonego rozwiązania)? Czym jest MLOps i jak może nam pomóc automatyzować mądrze?
Tło
Spójrzmy sobie na pryzmat przechodzenia od danych do produktu z perspektywy Michała. Michał to dżentelmen w średnim wieku, który działał w branży Machinę Learning. Na co dzień pracował w firmie Sample-POL Sp. z o.o. jako inżynier uczenia maszynowego.
Do firmy Michała niedawno trafił nowy projekt. Był to projekt zlecony przez rząd Nowej Zelandii. Michał miał stworzyć model ML do wykrywania oposów na obrazach z kamer. Podobno grasują w tej Zelandii i niszczą uprawy, przegryzają kable w samochodach itd. Co ciekawe, od klienta dostał przygotowane, oznaczone dane, bo tak mieli dość tych oposów, że się skrzyknęli i komitywą rąk ochotników oznaczyli te wredne oposy na zebranych z kamer zdjęciach.
Michał ma dane, także można powiedzieć, że teraz miał już z górki! Od razu zabrał się do pracy. Wziął jakiś gotowy model, który znalazł w internecie. Przetrenował model na otrzymanych danych, trochę pobawił się z tuningowaniem hiperparametrów. Po pewnym czasie i pewnej ilości zużytych zasobów GPU udało mu się wytrenować model, który spełnia założenia pierwszej fazy projektu.
Opakował model w API w FastAPI (Framework pythonowy, często używany do budowania aplikacji internetowych). Zapakował to wszytko przez FTP na serwer i się udało. Ma pierwsze, działające rozwiązanie.
Czas płynął. W dalekiej Nowej Zelandii oposy zaczęły zakładać bawełniane czapki a do tego trapery i model przestał je rozpoznawać. Michał niestety nie miał żadnych monitoringów swojego modelu, więc dowiedział się o błędach modelu od Ministra Zwierząt Nowej Zelandii, który przesłał mu zdjęcie oposów w czapkach przegryzających kable od akumulatora w jego Dacii Sandero.
Biedny Michał siadł przed komputerem i nie wiedział, co dalej począć. Niby dostał nowe dane, nawet oznaczone, ale znowu musiał wytrenować model, wrzucić go na serwer, podmienić ścieżki. I tak kilkanaście razy, bo gdy tylko wprowadzał nowy model, to za jakiś czas oposy stosowały rozmaite sztuczki, żeby oszukać kamery. Michał był zmęczony. I wtedy koleżanka z biurka obok wspomniała mu, że może warto by było zbudować jakiś mechanizm, który by część lub całość tego procesu pomagał przeprowadzać. Wspomniała, że może warto pogadać z zespołem DevOps, który tworzy takie automatyzacje dla różnych aplikacji, które do tej pory firma produkowała.
Michał niczym łania do paśnika popędził do biurka i rozpoczął ostre googlowanie. Jest! Trafił na coś, co się nazywa MLOps.
- Wygląda jak DevOps dla Machine Learningu, czy to jest to, czego szukam? - zastanawiał się Michał.
Czym jest MLOps
Michał drążył dalej. Na początku sprawdźmy, czego dowiedział się o MLOps po sesji intensywnego googlowania.
87%
Michał natknął się na pewien raport. Raport ten stwierdzał, że 87% modeli ML nie dotrze na produkcję. Co prawda raport był trochę stary, bo z 2019, i trochę słabo udokumentowany, ale zasiał jakieś ziarenko niepewności w głowie Michała. Bo jak się dowiedział, samo trafienie na produkcję, to jedno, ale ważnym elementem jest też operacjonalizacja (trudne słowo).
Zoperacjonalizować produkt to dostarczyć go na produkcję, co oznacza deploy, monitorowanie i utrzymywanie rozwiązania.
DevOps dla Machine Learning
Michał wiedział, że w sumie w przypadku „tradycyjnego wytwarzania oprogramowania” mamy takie pojęcie jak DevOps, które pozwala nam bardzo ładnie obsłużyć ten cykliczny proces wytwarzania oprogramowania. Tworzymy kod, budujemy, testujemy, wdrażamy, monitorujemy, ulepszamy itd.
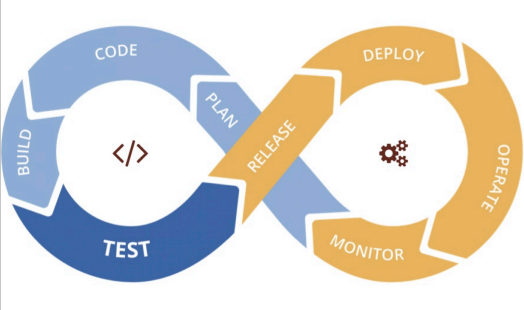
I jeżeli popatrzymy na cykl życia projektu opartego o uczenie maszynowe, to możemy zauważyć też pewne cykle i pętle, które pasowałoby w podobny sposób, jak w przypadku oprogramowania, obsłużyć.

I tak też termin MLOps definiuje się jako „rozszerzenie” metodologi DevOps w taki sposób, żeby proces oraz artefakty badania danych i uczenia maszynowego były, powiedzmy, pasażerami pierwszej klasy w devopsowym ekosystemie. MLOps, podobnie jak DevOps, jest wynikiem zrozumienia, że oddzielenie rozwoju modelu ML od procesu, który go dostarcza — operacji ML — obniża jakość, przejrzystość i zwinność całego inteligentnego oprogramowania.
MLOps to zestaw narzędzi i najlepszych praktyk do wprowadzania uczenia maszynowego do produkcji. A jakie założenia przyświecają MLOps?
Dążymy do tego, żeby mieć niezależny od języka czy frameworka jednolity cykl wydawniczy, gdzie artefakty są odpowiednie przetestowane i grają pierwsze skrzypce w systemie ciągłej integracji i dostarczania. Dzięki temu możemy zwinniej wdrażać takie oprogramowanie, zmniejszając przy tym dług techniczny.
Założenia są fajne, ale dlaczego się tym przejmować i dokładać sobie pracy?
Jaki procent czasu jako Data Scientist spędzasz na deployowaniu modeli ML?
Otóż oprócz wspomnianych wcześniej tematów jak testowalność, automatyzacja czy dług technologiczny, ważnym aspektem jest też czas. W jednym z badań (badanie Algorithmia.com) zadano pytanie: Jaki procent czasu jako Data Scientist spędzasz na deployowaniu modeli ML?
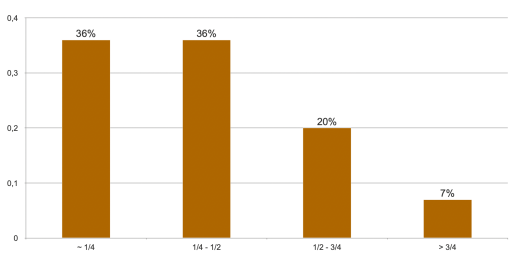
Możemy założyć, że każde usprawnienie w tej kwestii może uratować bardzo dużo jakże cennego czasu (no bo czas to pieniądz). Jak głosi przepiękne przysłowie:
„Modele są tymczasowe, potoki są wieczne”.
Jak wygląda proces MLOps?
Wiemy mniej więcej czym jest MLOps i w czy może nam pomóc. Jak wygląda taki proces?
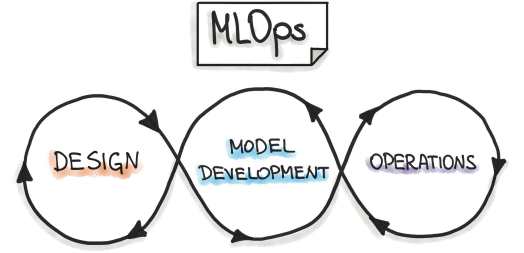
Obraz z ml-ops.org przez "INNOQ"
Obszary
Otóż jak już sobie opowiedzieliśmy wcześniej, w przypadku MLOps mamy do czynienia z 3 zazębiającymi się obszarami: Design, Model Development, Operations.
Design
Pierwsza faza — projektowania — poświęcona jest zrozumieniu biznesu, zrozumieniu danych i zaprojektowaniu oprogramowania wykorzystującego uczenie maszynowe. Na tym etapie identyfikujemy naszego potencjalnego użytkownika, projektujemy rozwiązanie tak, aby rozwiązać jego problem, oraz oceniamy dalszy rozwój projektu.
Definiujemy przypadki użycia ML i nadajemy im priorytety. Oczywiście sprawdzamy też dostępność danych, które będą potrzebne do trenowania naszego modelu oraz określenie funkcjonalnych i niefunkcjonalnych wymagań naszego modelu ML. Powinniśmy wykorzystać te wymagania do zaprojektowania architektury aplikacji ML, ustalenia strategii serwowania i stworzenia zestawu testów dla przyszłego modelu ML.
Model development
Kolejna faza „Eksperymentowanie i rozwój ML” jest poświęcona weryfikacji możliwości zastosowania ML do naszego problemu poprzez implementację Proof-of-Concept dla modelu ML.
Tutaj, iteracyjnie wykonujemy różne kroki, takie jak identyfikacja lub dopracowanie odpowiedniego algorytmu ML dla naszego problemu, inżynieria danych i inżynieria modelu. Głównym celem w tej fazie jest dostarczenie stabilnej jakości modelu ML, który będziemy mogli uruchomić w produkcji.
Operations
No i faza „ML Operations”, gdzie celem jest dostarczenie wcześniej opracowanego modelu ML na produkcję przy użyciu ustalonych praktyk DevOps, takich jak testowanie, wersjonowanie, ciągłe dostarczanie i monitorowanie.
Wszystkie trzy fazy są ze sobą powiązane i wzajemnie na siebie wpływają. Na przykład, decyzja projektowa podczas fazy projektowania będzie propagować do fazy eksperymentów i ostatecznie wpłynie na opcje wdrożenia podczas końcowej fazy operacji.
Proces od danych do produktu
Popatrzmy sobie teraz na ogólny zarys typowego przepływu pracy przy tworzeniu oprogramowania opartego na uczeniu maszynowym.
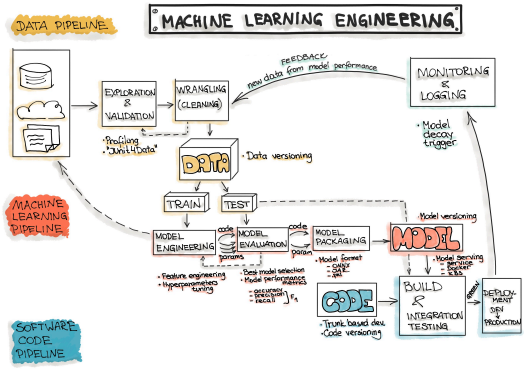
Obraz z ml-ops.org przez "INNOQ"
Celem projektu opartego na uczeniu maszynowym jest zbudowanie pewnego modelu poprzez wykorzystanie zebranych danych i zastosowanie do nich algorytmów uczenia maszynowego. Dlatego każde oprogramowanie oparte na uczeniu maszynowym zawiera trzy główne artefakty: Dane, Model ML oraz Kod. Patrząc na te artefakty, typowy proces uczenia maszynowego możemy podzielić na trzy główne fazy:
- Inżynieria danych:pozyskiwanie i przygotowanie danych,
- Inżynieria Modelu ML:szkolenie i obsługa modelu ML,
- Inżynieria kodu:integracja modelu ML w produkt końcowy.
Inżynieria danych
Pozyskiwanie danych — zbieranie danych przy użyciu różnych frameworków i formatów, takich jak Spark, HDFS, CSV itp. Ten krok może również obejmować generowanie danych syntetycznych lub wzbogacanie danych.
Eksploracja i walidacja — obejmuje profilowanie danych w celu uzyskania informacji o zawartości i strukturze danych. Wynikiem tego kroku jest zestaw metadanych, takich jak maksymalne, minimalne czy średnie wartości. Operacje walidacji danych są zdefiniowanymi przez użytkownika funkcjami wykrywania błędów, które skanują zbiór danych w celu wykrycia błędów.
Czyszczenie danych (ang. Data Wrangling) - proces przeformatowania poszczególnych atrybutów oraz korekty błędów w danych, np. imputacja brakujących wartości
Etykietowanie danych — operacja w potoku Inżynierii Danych, w której każdy punkt danych przypisywany jest do określonej kategorii.
Podział danych — podział danych na zbiory treningowe, walidacyjne i testowe, które będą wykorzystywane podczas zasadniczych etapów uczenia maszynowego w celu wytworzenia modelu ML.
ML Model Engineering
Trening modelu — proces zastosowania algorytmu uczenia maszynowego na danych treningowych w celu wytrenowania modelu ML. Obejmuje również inżynierię cech i dostrajanie hiperparametrów dla działań szkoleniowych modelu.
Ocena modelu — walidacja wytrenowanego modelu w celu zapewnienia, że spełnia on pierwotnie skodyfikowane cele przed przekazaniem modelu ML w produkcji użytkownikowi końcowemu.
Testowanie modelu — Przeprowadzenie ostatecznego „Testu akceptacji modelu” z wykorzystaniem zbioru danych z backtestu.
Pakowanie modelu — proces eksportowania ostatecznego modelu ML do określonego formatu (np. PMML, PFA lub ONNX), który opisuje model, w celu wykorzystania go przez aplikację biznesową.
Code Engineering
Integracja modelu ML w produkt końcowy.
Serwowanie modelu — proces zaadresowania artefaktu modelu ML w środowisku produkcyjnym.
Monitorowanie wydajności modelu — proces obserwowania wydajności modelu ML na podstawie bieżących i wcześniej niewidzianych danych, takich jak predykcja czy rekomendacja. W szczególności interesują nas sygnały specyficzne dla ML, takie jak odchylenia predykcji od poprzedniej wydajności modelu. Sygnały te mogą być użyte jako wyzwalacze do ponownego szkolenia modelu. Rejestrowanie wydajności modelu — każde żądanie wnioskowania skutkuje zapisem w dzienniku.
Najbardziej oklepany wykres...
Prawdopodobnie gdzieś już ten diagram obił Ci się o oczy.
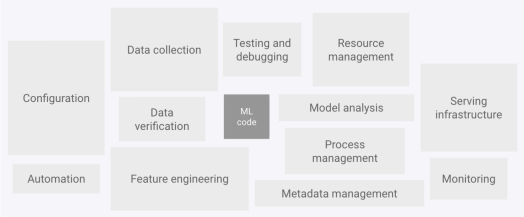
Elementy systemu ML z artykułu o MLOps od Google
Jak sobie popatrzymy na te wszystkie klocki, które widzimy tutaj w formie krótkich haseł, to potwierdza nam się teza, że tylko niewielka część systemu ML w świecie rzeczywistym składa się z kodu ML.
Do czego dążymy?
MLOps to kultura inżynierii ML, która w docelowej fazie opiera się o następujące praktyki:
- Continuous Integration (CI) rozszerza testowanie i walidację kodu i komponentów o testowanie i walidację danych i modeli.
- Continuous Delivery (CD) dotyczy dostarczania potoku szkoleniowego ML, który automatycznie wdraża kolejną usługę predykcji modelu ML.
- Continuous Training (CT) jest unikalne dla systemów ML, które automatycznie przekwalifikowują modele ML do ponownego wdrożenia.
- Continuous Monitoring (CM) dotyczy monitorowania danych produkcyjnych oraz metryk wydajności modeli, które są powiązane z metrykami biznesowymi.
Jakie są narzędzia?
Michał dowiedział się, czym jest MLOps i jak taki proces mniej więcej wygląda. I wszystko to wydawało się proste i logiczne. Kolejnym krokiem na jego liście, było rozejrzenie się w sprawie narzędzi, jakie są dostępne na rynku. Znalazł taką fajną stronę, na której są wylistowane narzędzia w obszarze ML oraz MLOps.
Całkiem sporo narzędzi...
Screenshot z The LF AI & Data landscape
Zobaczył, że, no tak kilka tych narzędzie się znajdzie. W każdym z obszarów.
- Sporo tego... - pomyślał Michał.
Wróćmy do naszego procesu. Na obrazku powyżej widzimy narzędzia pogrupowane w pewne kategorie. Jeżeli naniesiemy sobie te kategorie na schemat procesu, to otrzymamy coś, co można nazwać szablonem stacku MLOps.
Szablon stacku technologicznego MLOps
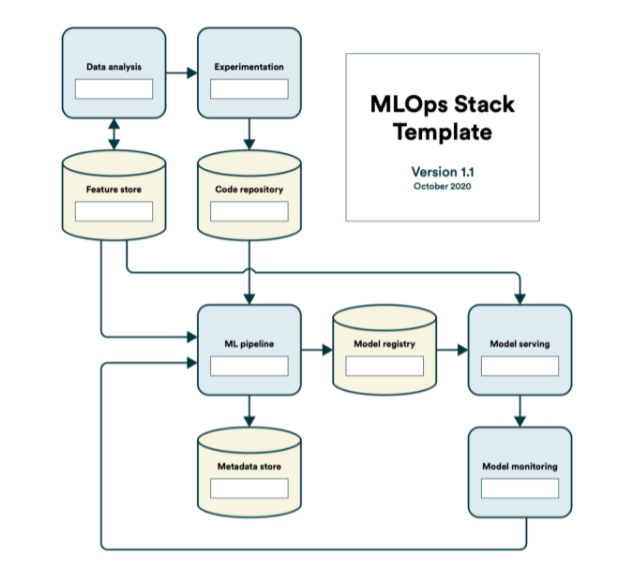
Obraz autorstwa Henrik Skogström (Valohai)
Teraz z tych wszystkich narzędzi, które gdzieś tam wcześniej widzieliśmy, powinniśmy sobie wybrać te, które wdrożymy w naszym projekcie. Możemy z korzystać z listy z pierwszego obrazka w tej sekcji, możemy też przejrzeć różne repozytoria na githubie, które również takie narzędzie grupują, jak np. Awesome Production Machine Learning.
Jak zastosować narzędzia do problemu?
Powiedzmy, że przeglądając ten szeroki ocean narzędzi, Michałowi udało się wybrać te, które chciałby zastosować. Co ma teraz zrobić? Spróbować wszystkie te narzędzia wdrożyć na raz? Etapami? A może w ogóle dać sobie spokój? Otóż nie Michał jest uparty, więc swoją pracę podzielił na pewne etapy.
MLOps — levele do wbicia
Niczym w grze komputerowej dążenie do MLOpsowej Nirvany (a docelowo skutecznego zneutralizowania oposów — nie zapominajmy o tym), Michał podzielił na pewne etapy.
MLOps Level 0 - Proces manualny.
Typowy proces data science, który wykonywany jest na początku wdrażania ML. Poziom ten ma charakter eksperymentalny i iteracyjny. Każdy krok w każdym potoku, taki jak przygotowanie i walidacja danych, szkolenie i testowanie modelu, jest wykonywany ręcznie. Powszechnym sposobem przetwarzania jest wykorzystanie narzędzi Rapid Application Development (RAD), takich jak Jupyter Notebooks.
MLOps Level 1 - Automatyzacja potoku ML
Automatyzacja potoku czy też rurociągu a po hiszpańsku (la tuberiiijía) uczenia maszynowego. Kolejny poziom obejmuje wykonanie treningu modelu w sposób automatyczny. Wprowadzamy tutaj ciągłe szkolenie modelu. Gdy tylko dostępne są nowe dane, uruchamiany jest proces ponownego szkolenia modelu. Ten poziom automatyzacji obejmuje również etapy walidacji danych i modelu.
MLOps Level 2 - Automatyzacja ciągłej integracji i dostarczania.
W ostatnim etapie wprowadzamy system CI/CD do szybkiego i niezawodnego wdrażania modeli ML na produkcję. Zasadnicza różnica w stosunku do poprzedniego etapu polega na tym, że teraz automatycznie budujemy, testujemy i wdrażamy dane, model ML oraz komponenty potoku treningowego ML.
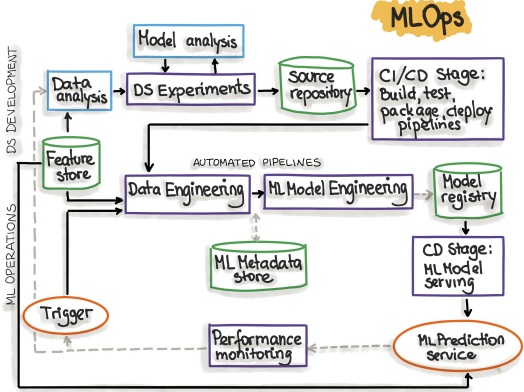
Obraz z ml-ops.org przez "INNOQ"
Przypomnijmy, na Levelu 3 chcemy mieć automatyczny pipeline jak na schemacie, gdzie kolejne kroki wyzwalane są ciągle i automatycznie.
Fazy
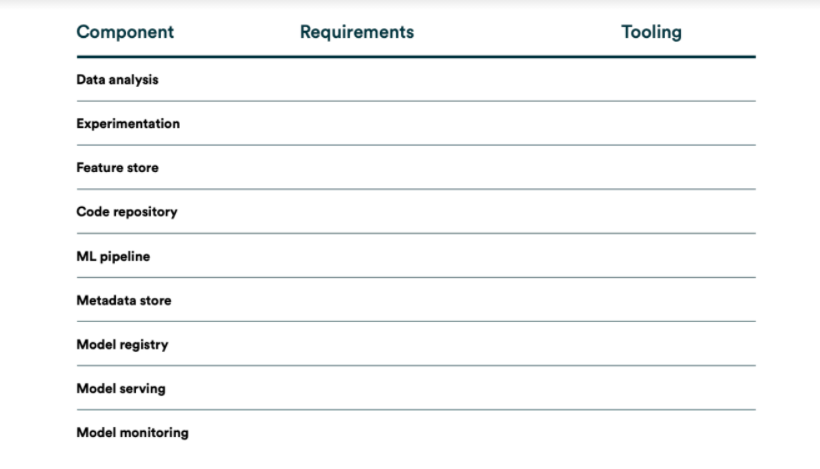
Poniższa tabela przedstawia zgrabne podsumowanie etapów MLOps, które odzwierciedlają proces automatyzacji rurociągu uczenia maszynowego oraz to, jakie chcielibyśmy mieć elementy po wdrożeniu tego etapu.
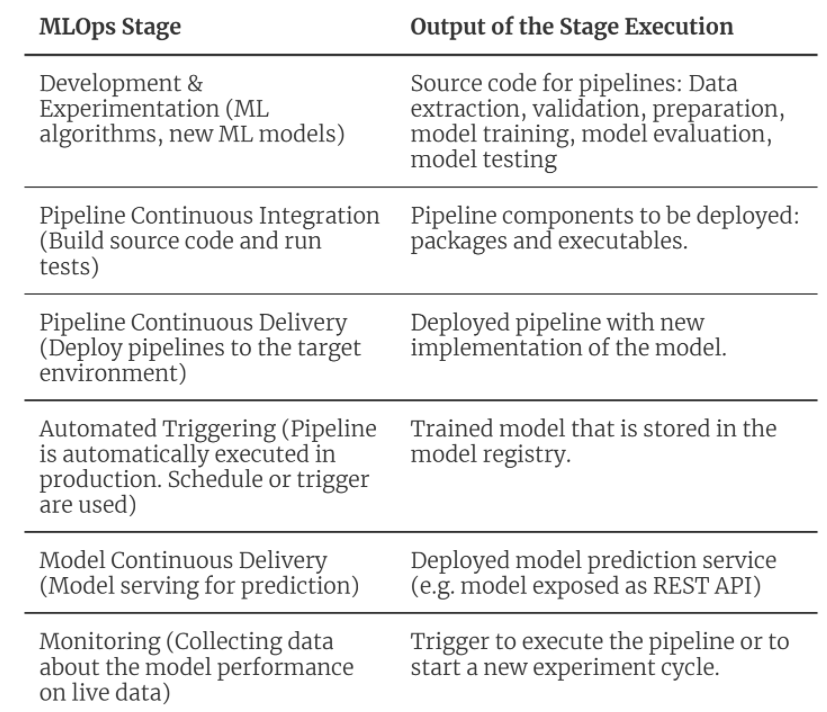
Co potrzeba?
Po przeanalizowaniu etapów MLOps możemy zauważyć, że konfiguracja MLOps wymaga zainstalowania lub przygotowania kilku komponentów. Potrzebujemy:
- Source Control— wersjonowanie kodu, danych i artefaktów modeli ML
- Test & Build Services— narzędzia CI do zapewniania jakości dla artefaktów ML oraz budowania pewnych paczek dla pipeline'u.
- Deployment Services— narzędzia CD do rozlokowania paczek na docelowym środowisku
- Model Registry— rejestr, który będzie przechowywał wytrenowane modele ML.
- Feature Store— przeprocesowane wstępnie dane wejściowe przechowywane w formie pewnych cech, które możemy wykorzystać w rurociągach uczenia modeli lub serwowania predykcji modeli.
- ML Metadata Store— rejestr metadanych treningów, takich jak nazwa modelu, parametry użyte do treningu, dane, jakie zostały wykorzystane do treningu, metryki modelu itp.
- ML Pipeline Orchestrator— orkiestrator, który pozwoli nam automatyzować poszczególne kroki naszego eksperymentu i wdrożenia.
Zgrywa nam się to z naszą templatką stacku MLOps, którą widzieliśmy wcześniej. I w sumie sporo z tych elementów jest podobna do tego, co mamy w „tradycyjnym” DevOps.
DevOps kontra MLOps — ostateczne starcie
Kompletny rurociąg rozwoju ML obejmuje trzy poziomy, na których mogą zachodzić zmiany: Dane, Model ML i Kod. Oznacza to, że w systemach opartych na uczeniu maszynowym, wyzwalaczem do budowy może być kombinacja zmiany kodu, zmiany danych lub zmiany modelu.
To, co odróżnia MLOps od DevOps to to, że na każdym poziomów automatyzacji musimy pamiętać, że mamy nie tylko kod, ale też dane i modele ML, które musimy uwzględnić w projektowanych automatyzacjach.
Posłowie
I na tym kończy się historia Michała, który implementując rurociąg automatyzacji MLOps dzielnie rozwiązał problem oposów w Nowej Zelandii, a dodatkowo zdobył cenne doświadczenie w automatyzacji wdrażania rozwiązań ML. Powtórzmy sobie pokrótce rzeczy, które warto zapamiętać z tej krótkiej historii:
- MLOps — rozszerzenie DevOps gdzie artefakty DS i ML są pasażerami pierwszej klasy .
- Oddzielenie rozwoju modelu ML od procesu, który go dostarcza -> obniża jakość, przejrzystość i zwinność całego inteligentnego oprogramowania.
- MLOps to zestaw narzędzi i dobrych praktyk do wprowadzania uczenia maszynowego do produkcji.
- Zjedz słonia po kawałku - 3 Levele
- Proces manualny
- Automatyzacja rurociągu ML
- Automatyzacja potoku CI/CD
Dobierz narzędzia do możliwości zespołu, środowiska wdrożenia, budżetu.