Zaawansowany SQL – funkcje okna

Czym tak właściwie są funkcje okna w SQL? Dlaczego nie powinieneś się ich bać? Co zyskasz, nabywając wiedzę o nich? Jak pomoże Ci to w codziennej pracy jako developer? Na te oraz kilka innych pytań będziesz w stanie odpowiedzieć po przeczytaniu poniższego artykułu. Do każdej z omawianych funkcji dołączone są przykłady.
Jeśli chcesz, możesz wykonywać kwerendy samodzielnie, modyfikować je i eksperymentować. Baza danych użyta we wszystkich przykładach – PostgreSQL posiada standardową implementację funkcji okna. Nawet jeśli nie używasz Postgresa, podobną składnię możesz później wykorzystać w innych technologiach bazodanowych – MySQL, SQL Server, MariaDB i wielu innych.
Czym są funkcje okna?
Jest to grupa funkcji operujących na rekordach w ramach okna. Przypominają one funkcje agregujące, posiadają jednak kilka przydatnych właściwości, dzięki którym oferują znacznie więcej niż agregaty. Główną różnicą pomiędzy funkcjami okna a agregatami, jest to, że w przypadku zastosowania tych pierwszych, nie będziesz musiał używać klauzuli GROUP BY, co nie ograniczy liczby rekordów, które otrzymasz jako odpowiedź na swoją kwerendę. Przydatna rzecz.
Czym jest okno (window) w SQL?
Skojarzenie ze światem budownictwa jest w tym przypadku jak najbardziej poprawne. Okno w SQL to pewien podzbiór rekordów. Poprzez podzielenie całego zbioru danych możesz przekazać dla danej funkcji jedynie interesujące Ciebie rekordy. Dzięki funkcjom okna możesz wykonać kalkulacje dostępne wcześniej jedynie przy użyciu skomplikowanych zabiegów. Wprowadzenie funkcji okna do Twojego warsztatu developera ułatwi, przyspieszy i uprzyjemni Ci pracę z SQL.
Czym jest ramka (window frame) w SQL?
Ramka to kolejny poziom rozdrobnienia zbioru danych. Dzięki wprowadzeniu ramek możesz wykonywać funkcje na podzbiorze podzbioru, czyli na części okna, które samo w sobie jest częścią zbioru.
W przypadku gdy nie zdefiniujesz żadnej ramki, domyślnie Twoje okno będzie potraktowane jako pojedyncza ramka, a funkcje będą wykonywane na całej partycji.
Składnia

Na pierwszy rzut oka wygląda na skomplikowane, prawda? Jednak gdy rozłożysz to na części, okaże się to super łatwe i przyjemne w użytkowaniu. Linijka po linijce:
Klauzula partycjonowania PARTITION BY
- kauzula ta dzieli rekordy na partycje, na których wykonywana jest funkcja okna. Pomimo tego, że jest to opcjonalna klauzula, zachęcam do niepomijania jej. Jeśli zostanie pominięta, funkcje będą traktowały cały zbiór danych jako pojedynczą partycję.
Klauzula sortowania ORDER BY
- klauzula ta określa kolejność w jakiej posortowane zostaną rekordy w danej partycji,
- klauzula sortowania używa opcji NULLS FIRST / NULLS LAST, żeby określić, czy wartości puste znajdą się na na początku, czy na końcu partycji.
Klauzula ramki
- klauzula ta definiuje podzbiór rekordów w partycji, dla których funkcja okna jest wykonywana. Taki podzbiór nazywamy ramką.
- klauzula ramki używa opcji ROWS / RANGE / GROUPS, żeby określić zakres rekordów. Przykładowo użycie: RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW określi ramkę jako obecny rekord, oraz wszystkie poprzedzające go. W poniższych przykładach użyto domyślnej ramki: RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING – jednym słowem pełnego zakresu rekordów.
Składnia za Tobą – najwyższa pora przejść do praktyki. Na potrzeby tego artykułu utworzyłem maksymalnie uproszczoną tabelę i przesypałem do niej trochę rekordów. Wszystkie kwerendy potrzebne do utworzenia takiego samego środowiska znajdziesz poniżej.
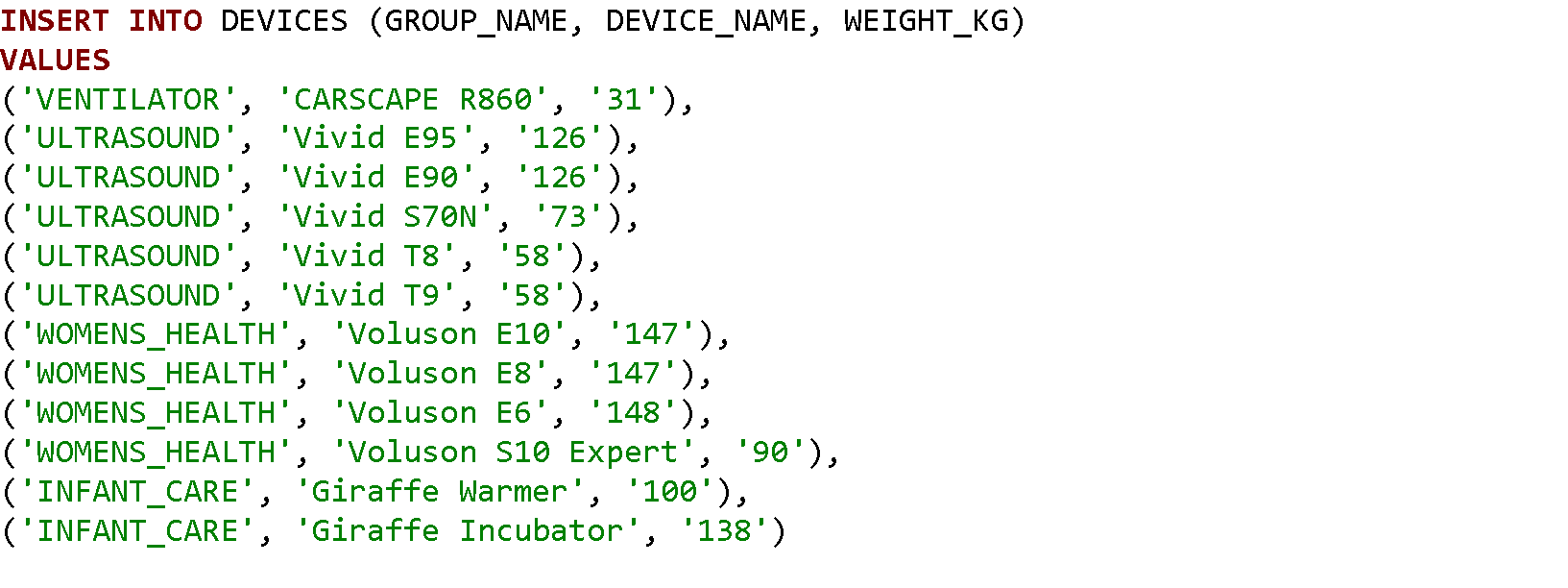
Najpierw utworzymy tabelę Devices zawierającą cztery kolumny: ID urządzenia, nazwę grupy, nazwę urządzenia oraz wagę:

Następnie wstawimy do niej kilkanaście rekordów, w tym przypadku będą to urządzenia medyczne.
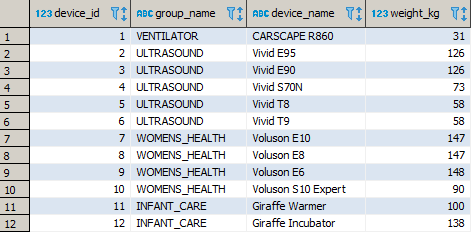
Po wykonaniu powyższych kwerend tabela Devices będzie zawierać następujące dane:
Testowa baza postawiona, czas na przykłady najbardziej przydatnych funkcji.
FUNKCJE OKNA: ROW_NUMBER()
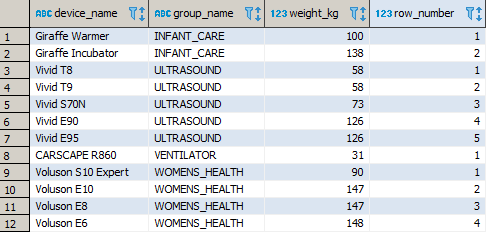
Funkcja ROW_NUMBER() to najprostsza w wykorzystaniu funkcja okna. Poznanie jej umożliwi Tobie lepsze zrozumienie kolejnych, bardziej zaawansowanych funkcji. Przydziela ona sekwencyjnie liczby całkowite do każdego z rekordów w zadanym oknie.
W poniższym przykładzie zbiór danych partycjonowany jest po nazwie grupy, a sortowany według masy oraz nazwy urządzenia. Bardzo podobnego okna będziesz używać we wszystkich przykładach.
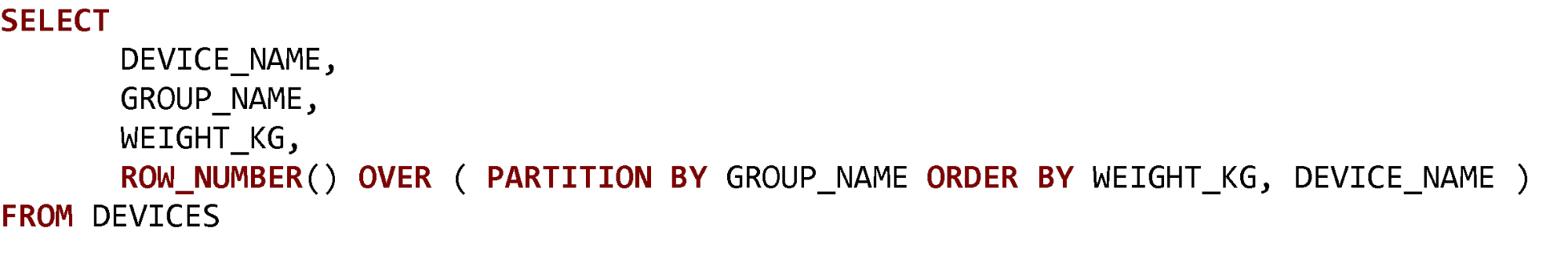
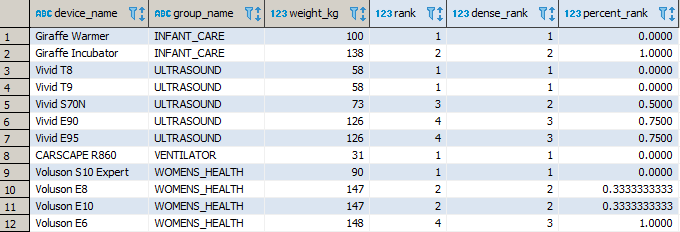
FUNKCJE OKNA: RANK() I POKREWNE
Grupa funkcji szeregujących rekordy. Nic więcej i nic mniej.
RANK() – przydziela sekwencyjnie ranking, a w przypadku remisów pomiędzy dwoma wartościami, wprowadza przerwę w numerowaniu.
DENSE_RANK() – przydziela ranking podobnie jak w przypadku funkcji RANK(), przy czym nie wprowadza przerwy w numerowaniu.
PERCENT_RANK – podobny mechanizm, tylko że w jego przypadku otrzymamy liczbę względną, odnoszącą się do innych rekordów okna, według wzoru (obecny ranking - 1) / (liczba rekordów w partycji – 1).

FUNKCJE OKNA: LAG(), LEAD()
Para funkcji, które pozwalają w bajecznie prosty sposób odnieść się do sąsiednich rekordów względem obecnie rozpatrywanego. Dzięki funkcji LAG() możesz odnieść się do rekordu na pozycji wcześniejszej niż obecna, a w przypadku funkcji LEAD() możesz odnieść się do rekordu na pozycji rozpatrywanej później. W przypadku niewystępowania rekordu o takiej pozycji otrzymasz domyślnie wartość NULL.

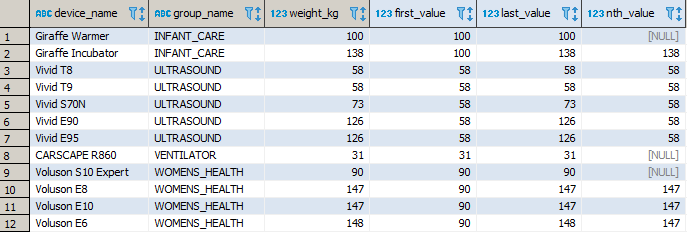
FUNKCJE OKNA: FIRST_VALUE(), LAST_VALUE(), NTH_VALUE()
Grupa funkcji, dzięki której możesz odnieść się do pierwszej wartości występującej w oknie, wartości ostatniej oraz wartości na zadanej przez Ciebie pozycji. Czym dokładnie różnią się te funkcje? FIRST_VALUE() oraz LAST_VALUE() zwrócą odpowiednio pierwszą oraz ostatnią wartość dla zadanego okna. Funkcja NTH_VALUE() zwróci natomiast rekord z zadanego przez Ciebie miejsca.

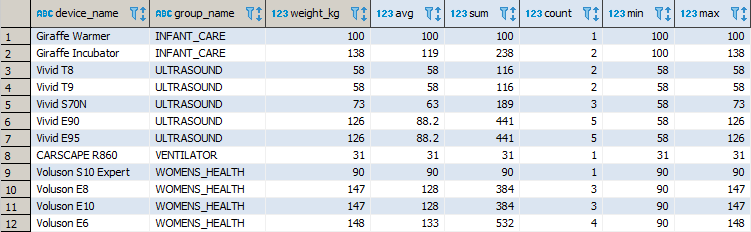
FUNKCJE OKNA: agregaty - avg(), sum(), count(), min(), max()
Grupa kilku przydatnych agregat użytych jako funkcje okna. Dzięki takiemu użyciu funkcji możesz połączyć benefity wynikające ze stosowania zarówno agregat oraz funkcji okna.

Dzięki za Twój czas, mam nadzieję że dowiedziałeś/aś się przydatnych informacji o funkcjach okna w SQL.