Wykorzystanie Open API 3 dla szybszego procesu rozwoju oprogramowania

Jestem entuzjastycznie nastawiony do świata open source. Istnieje tak wiele wspaniałych, darmowych, otwartych narzędzi, takich jak Linux, Kubernetes, Docker, Node.js i Golang. I ten ekosystem nadal się rozwija, przynosząc nowe technologie i rozwiązania dla lepszego świata (przynajmniej świata IT).
Dzisiaj omówimy kilka przydatnych projektów typu open-source. Jeśli kiedykolwiek przeczytałeś mój artykuł o praktyce rozwoju opartego na API, którą stosujemy w Kurio, znajdziesz w nim pojęcia takie jak Open API 3, mock server i generator SDK. Ale w tamtym artykule nie wyjaśniłem jak korzystać z Open API 3, tworzyć mock server, czy generować SDK.
W tym artykule omówię jak stworzyć serwer typu mock, wygenerować SDK darmowymi narzędziami (a.k.a projektami open-source) i zahostować to w klastrze Kubernetes(K8s). W tym przypadku wykorzystam własny klaster.
Wszystkie poniższe kroki wykorzystają klaster K8, a ja będę pracował przy założeniu, że posiadasz już przygotowany do produkcji klaster K8.
Podczas moich poszukiwań przygotowałem już przykład specyfikacji Open API 3 i wykorzystam ją w tym artykule. Specyfikację można znaleźć w moim repozytorium na Github.
Tworzenie wykonywalnej dokumentacji API
Potrzebne narzędzia:
- Swagger UI
- Kompletna/gotowa do użycia instalacja Open API
- Produkcyjny klaster K8 (lub, w fazie początkowej, przynajmniej działający)
Najprostszym elementem jest tworzenie żywej dokumentacji API. Mam nadzieję, że dzięki niej każdy programista będzie w stanie ją przeczytać i zrozumieć nasze API: jak ono działa, jakie udostępnia żądania i co odpowie. Istnieje wiele narzędzi, które możemy wykorzystać, ale w tym artykule wykorzystam domyślne narzędzie, dostarczone przez Swagger - Swagger UI.
Swagger zapewnia publiczny dockerowy obraz, który możemy wykorzystać. Jeśli masz klaster K8s, po prostu dodaj deployment dla tego obrazu. Łatwizna.
Krok pierwszy: Stworzenie obrazu dockera dla Swagger UI
Musimy stworzyć obraz Dockera, który zostanie użyty i wgrany do naszego klastra K8. Nie zapomnij użyć Swagger UI jako bazowego obrazu dockera.
Oto przykład mojego pliku Dockerfile:
FROM swaggerapi/swagger-ui:v3.23.1
ADD tweetor.yaml /usr/share/nginx/html/tweetor.yaml
# Add another spec heretweetor.yamljest moją specyfikacją Open API. Po prostu dodaj ją do folderu obrazu bazowego. Kompletny plik można znaleźć tutaj.- Ponieważ obraz bazowy
swaggerapi/swagger-ui:v3.23.1wykorzystuje nginx, muszę dodać swójSpecdo folderu nginx, który jestw/usr/share/nginx/html/.
A potem możemy zbudować i przenieść go do prywatnego rejestru kontenerów (ja używam do tego celu GCR):
$ docker build -t asia.gcr.io/kube-xmas/tweetor-docs:latest .
//docker build process will happen here...
$ docker push asia.gcr.io/kube-xmas/tweetor-docs:latest
//docker push process will happen here...
Krok drugi: Utwórz konfigurację deploymentu Kubernetes dla Swagger UI
Utwórz deployment component K8s.
apiVersion: v1
kind: Namespace
metadata:
name: tweetor-docs
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: tweetor-docs
namespace: tweetor-docs
spec:
selector:
matchLabels:
app: tweetor-docs
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
template:
metadata:
annotations:
checksum/deployment: TMP_DEP_CHECKSUM
labels:
app: tweetor-docs
spec:
containers:
- name: tweetor-docs
image: asia.gcr.io/kube-xmas/tweetor-docs:latest
imagePullPolicy: Always
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 10
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 10
resources:
limits:
cpu: 20m
memory: 30M
requests:
cpu: 10m
memory: 20M
---
kind: Service
apiVersion: v1
metadata:
name: tweetor-docs
namespace: tweetor-docs
spec:
type: NodePort
selector:
app: tweetor-docs
ports:
- protocol: TCP
port: 80
targetPort: 8080
Odpal komendę i uruchom wgrywanie na Kubernetes:
$ kubectl apply -f swagger_ui_deployment.yaml
$ kubectl get pods --namespace=tweetor-docs
NAME READY STATUS RESTARTS AGE
tweetor-docs-786d889d67-65h45 1/1 Running 0 14m
W powyższym przykładzie, użyłem tylko trzech komponentów: Namespace, Deployment i Service (Node Port). Ostatnim krokiem jest dodanie komponentu Ingress do serwisu, dzięki czemu każdy inżynier będzie mógł zobaczyć dokumentację.
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: tweetor-docs
namespace: tweetor-docs
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: docs.tweetor.xyz
http:
paths:
- path: /
backend:
serviceName: tweetor-docs
servicePort: 80
$ kubectl apply -f ingress_swagger_docs.yaml
Teraz dokumenty będą dostępne dla każdego inżyniera.
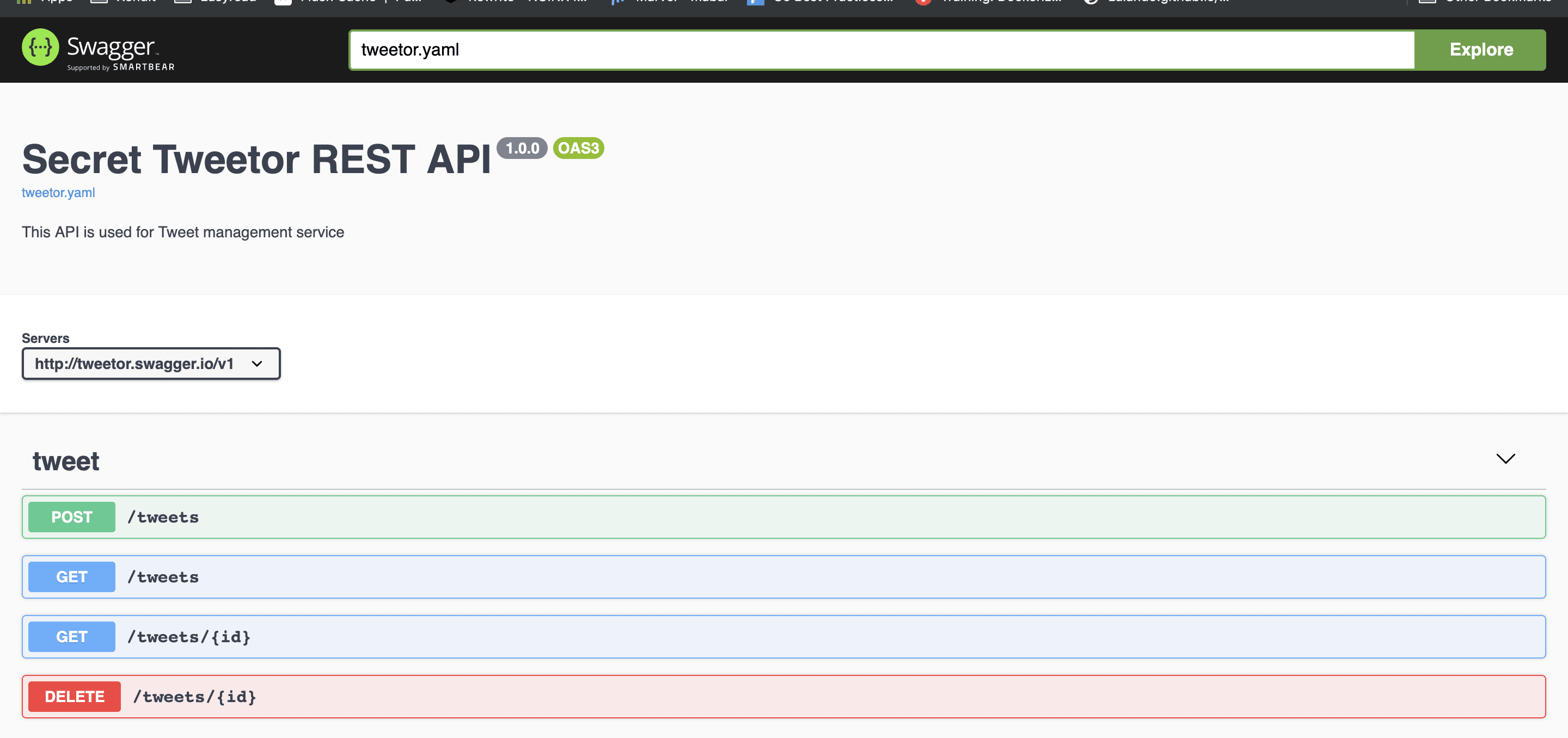
*Uwaga: Jeśli podczas odwiedzania API-Docs, napotkałeś Petstore swagger, wpisz nazwę swagger yaml, którą stworzyłeś w pliku dokującym. W moim przypadku używam tweetor.yaml, jak widać na pasku wyszukiwania/eksploracji. Wszystkie Twoje docsy mogą być hostowane w jednym kontenerze dokującym. Jeśli masz czas, spróbuj zmienić domyślny plik swagera na stronie indeksu.
Tworzenie lekkiego i super szybkiego serwera typu Mock
Lista rzeczy, których potrzebujesz:
- API Sprout
- Kompletna/gotowa do użycia instalacja Open API.
- Produkcyjny klaster K8 (lub, w fazie początkowej, przynajmniej działający)
Kolejną sztuczką, która może być przydatna przy tworzeniu oprogramowania, jest stworzenie serwera typu mock-server. Reprezentuje on prawdziwy serwer, ale zazwyczaj nie posiada żadnej specyficznej logiki. Może zaakceptować każde żądanie, ale odpowiedź zazwyczaj jest statyczna.
Po co nam mock server?
Najprostszym przykładem, jaki przychodzi mi do głowy, jest sytuacja, gdy pracujemy pomiędzy dwoma zespołami: jednym na backendzie, a drugim na frontendzie. Oba zespoły biorą udział w tym samym sprincie. Normalnie, zespół front-end będzie potrzebował API, by być gotowym jako pierwszy, więc mogą pracować, ale podczas pracy na tym samym sprincie, będzie on zablokowany, ponieważ backend nadal ma nie zaimplementowane API. Wtedy mock server są użyteczne.
Jak więc z łatwością stworzyć serwer typu mock?
Krok pierwszy: Tworzenie Dockerfile
Mam już klaster Kubernetes i gotową do użycia kopię specyfikacji Open API 3.
Do tego, co chcemy osiągnąć, jest dobre narzędzie/biblioteka. Jest to prosty generator serwerów typu mock, oparty na specyfikacji Open API 3. Kod jest naprawdę prosty i napisany w Golangu. Gdybym tylko wpadł na taki pomysł wcześniej, to sam mógłbym stworzyć to narzędzie. Nie szkodzi. Zamiast wymyślać koło od nowa, użyję go do własnych celów.
To, co muszę zrobić, to stworzyć z niego obraz Dockera i dodać moją specyfikację Open API do tego obrazu.
To jest mój Dockerfile:
FROM swaggerapi/swagger-ui:v3.23.1
ADD tweetor.yaml /usr/share/nginx/html/tweetor.yaml
# Add another spec here
Utwórz obraz Dockera i przenieś go do rejestru Dockera:
$ docker build -t asia.gcr.io/kube-xmas/tweetor-mock:latest .
//docker build process will happen here...
$ docker push asia.gcr.io/kube-xmas/tweetor-mock:latest
//docker push process will happen here...
Musimy już tylko dodać plik do deploymentu na Kubernetes.
Krok drugi: Tworzenie procesu wgrania mock servera na Kubernetesa
Należy dodać deployment K8. Oto moja konfiguracja usunąć:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mock-tweetor
namespace: staging
spec:
selector:
matchLabels:
app: mock-tweetor
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
template:
metadata:
labels:
app: mock-tweetor
annotations:
checksum/deployment: TMP_DEP_CHECKSUM
spec:
containers:
- name: mock-tweetor
image: asia.gcr.io/kube-xmas/tweetor-mock:latest
imagePullPolicy: Always
args: ["/data/tweetor.yaml"]
resources:
limits:
cpu: 50m
memory: 32M
requests:
cpu: 25m
memory: 16M
---
kind: Service
apiVersion: v1
metadata:
name: mock-tweetor
namespace: staging
spec:
type: NodePort
selector:
app: mock-tweetor
ports:
- protocol: TCP
port: 8000
targetPort: 8000
name: mock-tweetor
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: mock-tweetor
namespace: staging
annotations:
kubernetes.io/ingress.class: nginx
spec:
rules:
- host: mock.tweetor.xyz
http:
paths:
- path: /
backend:
serviceName: mock-tweetor
servicePort: 8000
$ kubectl apply -f mock_tweetor_deployment.yaml
Po dodaniu Ingress do konfiguracji DNS można uzyskać dostęp do serwera:
$ curl mock.tweetor.xyz/tweets
[
{
"createdTime": "2018-12-24T09:21:41.827Z",
"id": "abc-f45def-5sdaf-5636f",
"text": "Merry Christmast Everyone!!!"
},
{
"createdTime": "2018-12-23T09:21:41.827Z",
"id": "abc-f45def-5sdaf-5636f",
"text": "I believe santa will give me a great present"
},
{
"createdTime": "2018-12-22T09:21:41.827Z",
"id": "abc-f45def-5sdaf-5636f",
"text": "Hello my secret santa. Thank you!!!"
}
]
Teraz nasz zespół frontendowy będzie w stanie rozwijać frontend przy użyciu zmockowanego API.
Generowanie klientów HTTP SDK
Potrzebujesz:
- Generator Open API
- CI/CD (do bardziej zaawansowanego przypadku użycia, tu nie będę go używać).
Ostatnią rzeczą, którą musimy omówić jest to, jak wykorzystać specyfikację Open API do wygenerowania klienckiego SDK HTTP. SDK oznacza grupę bibliotek lub innych rzeczy, które mogą nam pomóc w integracji lub korzystaniu z niektórych usług lub narzędzi.
W świecie mikrousług istnieje wiele usług obsługujących różne zadania. Każda z nich ma swój punkt końcowy, który może się różnić od innych, ale w jego ramach nadal mają ten sam wzór (mówię o mikrousługach RESTfull). Używają czasowników HTTP (GET, POST, PUT, DELETE) oraz kodów statusu (200,201,202,400,401,403,404,500,itd.).
Każda usługa może zależeć od więcej niż jednej usługi i przy podłączaniu każdej usługi do innej, zwykle programiści budują swoją funkcję do wykonywania żądań HTTP.
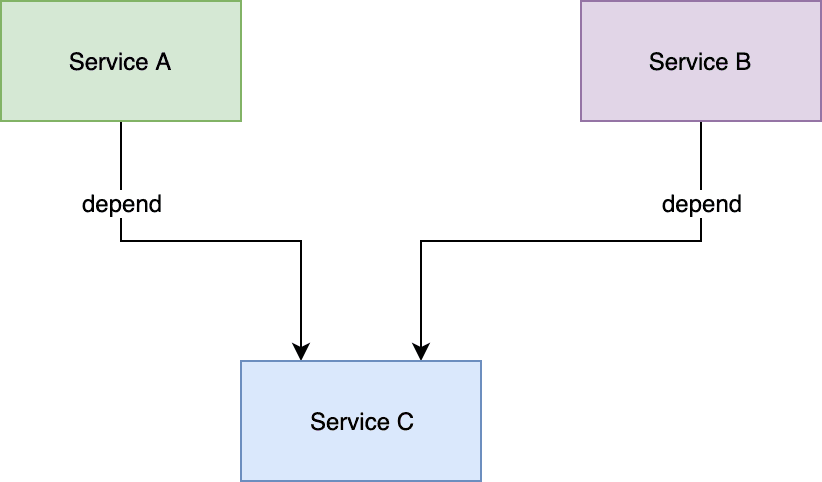
usługa A i B zależna od C
Na przykład z powyższego zdjęcia:
Powiedzmy, że Service A i Service B są podłączone do Service C. Teraz wyobraźmy sobie, że programista sam zbudował kod łączący usługi A i C (REST HTTP Client). Ten programista napisał podobny kod łączący C z Service B. I wyobraźmy sobie, że istnieją również liczne usługi, które będą podłączone do Service C i wszystkie połączenia zostały zakodowane ręcznie.
W powyższym przykładzie widzimy zbędną pracę. Co, jeśli kod łączący usługi został wydzielony i zaimportowany do naszego projektu jako biblioteka? A co, jeśli zamiast pisać ten kod ręcznie, możemy wygenerować go automatycznie?
W ten sposób będzie tu wykorzystywane Open API. Wcześniej, w Swagger 2, poprzedniej wersji Open API 3, powszechne było generowanie klientów HTTP. Ale w Open API 3 to nadal nowość.
Na szczęście, istnieje wspaniałe narzędzie, które zostało zbudowane przez społeczność. Znajdziesz je tutaj. Jest to darmowe oprogramowanie open-source, bardzo łatwe w użyciu. Szczególnie dlatego, że już obsługuje CLI i obrazy Dockera.
Generuj SDK z Dockerem
Wolę używać Dockera, ponieważ może być używany w CI/CD, zwłaszcza jeśli CI/CD obsługuje konteneryzację, jak np. Buddy. Dzięki Dockerowi nie musimy instalować Java SDK, ponieważ jeśli chcemy zainstalować za pomocą CLI, musimy zainstalować Java SDK. Właśnie dlatego użyję metody wykorzystujacej Dockera.
$ docker run --rm -v ${PWD}:/local openapitools/openapi-generator-cli generate \
-i ./local/tweetor.yaml \
-g go \
-o ./local/sdk- Zmień
./tweetor.yamlna swoją specyfikację Open API. -g: podaj język programowania wygenerowanego SDK. Obsługiwany język programowania można zobaczyć tutaj. W powyższym przykładzie, chcę wygenerować zestaw SDK klienta HTTP dla Golanga.-o: określ folder docelowy wygenerowanego SDK.
Poniżej znajduje się podgląd wygenerowanego klienta HTTP. Jest to przykładowa struktura folderów po wygenerowaniu klienta w Go.
.
├── README.md
├── api
│ └── openapi.yaml
├── api_tweet.go
├── client.go
├── configuration.go
├── docs
│ ├── Tweet.md
│ └── TweetApi.md
├── git_push.sh
├── go.mod
├── go.sum
├── model_tweet.go
└── response.go
Nie wiem dokładnie, jak kod został wygenerowany, ale możesz spróbować to zrobić samodzielnie i obejrzeć wygenerowany SDK. Jest to naprawdę pomocne i pomaga nam szybciej rozwijać projekty, jeśli pracujemy nad wieloma mikrousługami.
Ale w przyszłości może pojawić się problem z tak wygenerowanym SDK:
- Utrzymanie wersji docelowego API. Ponieważ jest to klient wygenerowany automatycznie, to może być ciężko obsłużyć wersjonowanie. Tak więc optymalnym rozwiązaniem jest aby po wygenerowaniu SDK, wrzucić je do repozytorium Git i dodać tag "git" do każdego wygenerowanego SDK (właściwie w wygenerowanym katalogu znajduje się skrypt, który to robi, więc problem rozwiązany. :D).
Co dalej?
Istnieje wiele narzędzi związanych z Open API lub Swagger, które mogą nam się przydać. Każde z wymienionych narzędzi można znaleźć tutaj: https://openapi.tools.
Następnym krokiem jest automatyzacja procesu za pomocą (wybranego przez Ciebie) CI/CD, więc gdy ktoś zaktualizuje specyfikację Open API, to automatycznie zostaną zaktualizowane wszystkie komponenty: dokumentacja API, mock server i wygenerowane SDK.
Zautomatyzowałem cały proces, który opisałem powyżej, ale nadal szukam odpowiedniego momentu, by to opisać ??
Oryginał tekstu w języku angielskim przeczytasz tutaj.