Wszystko, co musisz wiedzieć o ActiveRecord - część 1

Jedną z najbardziej podstawowych funkcji w większości aplikacji webowych jest komunikacja z bazą danych. Jako developerzy Ruby on Rails z ActiveRecordem mamy do czynienia praktycznie codziennie, a mimo to - przewijając się przez wiele różnych projektów - bardzo często widzę problemy w tym aspekcie. Myślę, że po części odpowiada za to sama filozofia frameworku, która dyktuje, że ma on zastępować pracę programisty tak bardzo jak to możliwe. Oczywiście jest to w dużej mierze zaleta - można zacząć tworzyć aplikacje korzystające z bazy danych bez jakiejkolwiek wiedzy o ich działaniu i o pisaniu zapytań SQL.
Na dłuższą metę to podejście przesłania jednak pewne rzeczy, które programiście wypada wiedzieć. Widać to zwłaszcza w długoterminowych projektach, zaczynanych lata wcześniej przez początkujących programistów.
W tej serii artykułów zamierzam pokazać jak “pod maską” działa ActiveRecord, stworzyć przewodnik po wszystkich jego funkcjach i trikach, które można zastosować, a także wyjaśnić co-nieco SQL-a. W dalszych częściach zbudujemy pełnoprawny system wyszukiwania fulltextowego w PostgreSQL używając tylko i wyłącznie funkcji wbudowanych w Ruby on Rails.
W ramach części pierwszej zbudujemy podstawowy system filtrowania i sortowania danych używając tylko natywnych możliwości ActiveRecorda. W następnych częściach będziemy go rozbudowywać i refaktoryzować.
Jak przystało na programistów Ruby on Rails - naszą przykładową aplikacją będzie blog. Na początek mamy posty z tytułem, hookiem, body, booleanem określającym czy dany post jest draftem i datą publikacji. Post ma też wiele głosów (votes). Dla utrudnienia votes jest relacją polimorficzną, żebyśmy mogli dodać podobny system również do komentarzy, które zaimplementujemy w przyszłości.
CREATE TABLE public.posts (
id bigint NOT NULL,
title character varying,
hook character varying,
body text,
tags text[] DEFAULT '{}'::text[],
published_at timestamp without time zone,
draft boolean,
created_at timestamp(6) without time zone NOT NULL,
updated_at timestamp(6) without time zone NOT NULL
);CREATE TABLE public.votes (
id bigint NOT NULL,
weight smallint,
voteable_type character varying NOT NULL,
voteable_id bigint NOT NULL,
user_id bigint NOT NULL,
created_at timestamp(6) without time zone NOT NULL,
updated_at timestamp(6) without time zone NOT NULL
);
Zbudujmy więc scope, który przyjmie parametry z naszego formularza (widocznego poniżej) i zamieni je na pełnowartościowe zapytanie.
Kod widoku:
<p id="notice"><%= notice %></p>
<%= form_with scope: :search, url: search_posts_path, method: :get, local: true do |f| %>
Query: <%= f.search_field :query, value: params.dig(:search, :query) %>
<p>
Date range:
<%= f.date_field :date_from, value: params.dig(:search, :date_from) %> -
<%= f.date_field :date_to, value: params.dig(:search, :date_to) %>
<br/></p>
Categories: <%= f.select :category, Category.pluck(:name, :id),
{include_blank: true, selected: params.dig(:search, :category)},
{multiple: true} %>
<%= f.submit 'Search', data: {disable_with: 'Searching'} %>
<% end %>
<div id='search-results'>
<% @posts.each do |post| %>
<h2><%= post.title %></h2>
<b><%= post.hook %></b>
<p>Reputation: <%= post.votes.sum(:weight) %></p>
<span>Published <%= post.published_at %></span>
<% end %>
</div>
<br>
<%= link_to 'New Post', new_post_path %>
Bazując na doświadczeniu - dostając aplikację o podobnej specyfikacji spodziewałbym się czegoś takiego:
def self.search(prms)
query = where(draft: false)
query = query.where('title ilike ?', prms[:query]) if prms[:query].present?
unless prms[:date_from].blank? || prms[:date_to].blank?
query = query.where('published at between ? and ?', prms[:date_from], prms[:date_to])
end
if prms[:category]&.reject!(&:blank?)&.any?
query = query.joins(:categories).where(categories: { id: prms[:category] })
end
query
end
Pierwszym dobrym pomysłem jest tutaj wyszczególnienie listy atrybutów, które potrzebujemy z bazy. Zapytanie można przyspieszyć pomijając na przykład duży blok tekstu jakim będzie prawdopodobnie body. Przy okazji unikniemy pobierania atrybutów, które mogą zostać dodane w przyszłości. Nasze wyniki wyszukiwania będą pokazywały tytuł będący jednocześnie linkiem (title i id), zajawkę (hook), datę publikacji i ilość głosów. System głosowania jest bardziej wyrafinowany, ale na początek wyświetlimy tylko count.
Pierwszy problem jaki rzuca się tutaj w oczy to n+1, czyli seria dodatkowych zapytań związanych z liczeniem głosów - po jednym dodatkowym zapytaniu na każdy rekord. Najprostszym (chociaż na pewno nie najlepszym) rozwiązaniem jest tutaj dodanie .includes(:votes). Na razie tak to zostawmy - w przyszłej części przerobimy to tak, żeby głosy były liczone wewnątrz samego zapytania.
def self.search(prms)
query = select(:id, :title, :hook, :published_at).where(draft: false).order(:title).includes(:votes)
query = query.where('title ilike ?', "%#{prms[:query]}%") if prms[:query].present?
unless prms[:date_from].blank? || prms[:date_to].blank?
query = query.where('published at between ? and ?', prms[:date_from], prms[:date_to])
end
if prms[:category]&.reject!(&:blank?)&.any?
query = query.joins(:categories).where(categories: { id: prms[:category] })
end
query
end
Wyrzućmy sobie filtrowanie po dacie do osobnego scope’a:
scope :by_date, -> (from, to) { where(‘published_at BETWEEN ? AND ?’, from, to) }
Osobiście nie przepadam za literalami, ale zapewne znacie składnię ze znakami zapytania pod które jest podstawiany dalszy array parametrów. Robi się to w ten sposób, żeby zapewnić prawidłowe escapowanie parametrów. Gdybyśmy po prostu interpolowali string - wartości mogłyby nie być bezpieczne.

Rzadziej widuje się użycie hasha:
scope :by_date, -> (from, to) { where(‘published_at BETWEEN :from AND :to’, from: from, to: to }
W tym przypadku składnia dłuższa i raczej zbędna, ale przydatna gdy jeden parametr wklejamy wiele razy (również po to, żeby uniknąć wielu calli do tej samej metody), albo parametrów jest dużo i chcemy zwiększyć czytelność.
Zwykle takie implementacje widzi się w kodzie pisanym przez programistów innych języków, którzy po prostu są przyzwyczajeni do pisania literali, albo w implementacjach wymagających dodatkowego sprawdzenia, czy podane wartości są prawidłowe... The Rails (6.0+) way:
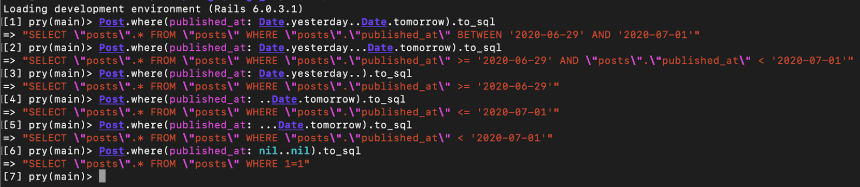
scope :by_date, -> (from, to) { where(published_at: from..to) }
UWAGA: Z tą składnią nie powinno być problemów w Ruby 2.7+ i Rails 6.0.3+, które obsługują endless (od ruby-2.6) i beginless (od ruby-2.7) range. We wcześniejszych wersjach Ruby pojawi się problem jeśli from, albo to będą miały wartość nil - ArgumentError: bad value for range, a we wcześniejszych wersjach Rails działających na Ruby 2.6+ zostanie wygenerowane nieprawidłowe zapytanie - BETWEEN ‘2020-06-06’ AND NULL co nie zwróci nam ANI JEDNEGO rekordu. Podane wersje Ruby i Rails obsłużą wszystko prawidłowo nawet jeśli obie zmienne będą miały wartość nil.
Przykład z datami jest specyficzny, ale tej samej składni można użyć również przy integerach.
NOTE: Użycie zamkniętego range’a (dwukropkowego) skutkuje użyciem operatora BETWEEN, gdybyśmy jednak użyli otwartego (trzykropkowego) range’a, który nie zawiera ostatniej wartości - ActiveRecord wygeneruje zapytanie WHERE "posts"."published_at" >= $1 AND "posts"."published_at" < $2
Drugim scopem, jaki sobie stworzymy, będzie filtrowanie draftów:
scope :published, -> { where(draft: false) }
Mogłoby się wydawać, że to wszystko i nie ma tu nic więcej do zrobienia, ale jest jeden potencjalny problem. Ruby on Rails podczas generowania migracji domyślnie nie daje polom typu boolean klauzuli NOT NULL.
To oznacza, że w wielu aplikacjach nasze booleany mają trzy potencjalne wartości zamiast dwóch - TRUE, FALSE i NULL. To może się stać pułapką, dlatego że w SQL FALSE i NULL to nie to samo. Filtrując where(draft: false) rekordy gdzie draft ma wartość NULL są pomijane. Tak samo przy filtrowaniu where(draft: true). Dlatego polecam do booleanów w swoich migracjach dodawać klauzulę null: false, albo wartość domyślną, chyba że celowo zamierzacie korzystać z logiki trójwartościowej :)
Kuszące może się wydawać rozwiązanie tego problemu przy pomocy .not:
Miałem identyczny problem w pewnej aplikacji. Po sprawdzeniu rekordów z draft = NULL stwierdziliśmy, że oryginalni twórcy zakładali, że NULL = FALSE. Moglibyśmy po prostu UPDATE-ować wszystkie wartości NULL na FALSE, ale nie mieliśmy pewności, czy wadliwe dane nie przychodzą z zewnątrz (więcej aplikacji łączyło się z tą samą bazą danych). Koniec końców problem rozwiązaliśmy:
scope :published, -> { where(draft: [nil, false] }
W ActiveRecordzie nil reprezentuje NULL, więc takie zapytanie przynosi rezultaty, których się spodziewamy. Co ciekawe, zwykle przekazanie array'a jako wartości w ten sposób skutkuje użyciem operatora IN, ale jeśli jedna z wartości w arrayu to nil - wtedy ActiveRecord wygeneruje zapytanie WHERE ("posts"."draft" = $1 OR "posts"."draft" IS NULL). Jeśli wartości jest więcej - zostanie użyty operator IN, ale NULL-e zawsze będą sprawdzane przez IS NULL (lub IS NOT NULL). Dzieje się tak dlatego, że NULL jest specjalną wartością, która posiada własny swego rodzaju indeks w bazie danych i sprawdzenie tej wartości osobno jest dużo szybsze. Ignorujecie NULL na własną odpowiedzialność.

Jak mogliście zauważyć - ActiveRecord wygenerował nam zapytanie używające operatora OR i robił tak już dużo wcześniej, ale warto przypomnieć, że możliwość własnoręcznego tworzenia scopów z użyciem OR (bez literali) dostaliśmy dopiero w Rails 5, więc moglibyśmy napisać to tak:
scope :published, -> { where(draft: false).or(where(draft: nil)) }
Array jest krótszy, ale warto pamiętać, że mamy możliwość użyć OR.
def self.search(prms)
query = select(:id, :title, :hook, :published_at).published
query = query.where('title ilike ?', "%#{prms[:query]}%") if prms[:query].present?
query = query.by_date(prms[:from], prms[:to]) if prms.slice(:date_from, :date_to).any?
if prms[:category]&.reject!(&:blank?)&.any?
query = query.joins(:categories).where(categories: { id: prms[:category] })
end
query.order(:title).includes(:votes)
end
NOTE: W tym konkretnym przypadku, pisząc czysty SQL, moglibyśmy użyć operatora IS NOT TRUE, który zadziałałby tak, jak chcemy - zwracając również rekordy, gdzie draft = NULL, ale ActiveRecord nie daje nam możliwości użycia tego operatora przez standardową składnię. Wcześniej również mogliście zauważyć, że AR nie ma problemu z generowaniem zapytań z użyciem operatorów >= i <, do których również nie mamy bezpośredniego dostępu (za wyjątkiem najnowszych wersji Ruby i Rails, gdzie możemy je uzyskać stosując endless i beginless range).
O tym, jak możemy użyć tych (i wielu innych) operatorów, nie porzucając komfortu programowania w Ruby on Rails - już w następnym odcinku, w którym zajmiemy się funkcjami agregującymi i rozprawimy się ze zliczaniem głosów dla naszych postów!
O autorze
Pracuję w Polcode jako senior Ruby on Rails developer, mam w sumie ~10 lat doświadczenia w branży. Pracowałem przy przeróżnych projektach, ale koniec końców najbardziej lubię pracę na backendzie i przy bazach danych. Można mnie spotkać na eventach takich jak KRUG, czy Rails Girls. Poza pracą lubię dobrą muzykę i dobre jedzenie, jestem też wielkim nerdem w kwestiach zdrowia i odżywiania.