Współbieżność i współdziałanie Lambdy i SQS

AWS zapewnia możliwość uruchomienia funkcji lambda przy pomocy zdarzeń w kolejce SQS. Lambda sprawdza, czy są wiadomości w kolejce i wywołuje funkcję synchronicznie. Pobiera wiadomości w paczkach i przekazuje je jako dane wejściowe do funkcji. Kiedy funkcja skończy przetwarzanie paczki wiadomości, to usuwa zdarzenia z kolejki. Jeśli podczas przetwarzania pojawi się błąd, to wiadomości pojawią się w kolejce po raz kolejny po visibility timeout i może finalnie wylądować w kolejce dead-letter, jeśli błąd będzie dalej występował.
To w czym problem?
Kiedy ustawiony zostanie wyzwalacz SQS, Lambda zacznie long polling z pomocą 5 równoległych połączeń. Każde połączenie pobiera paczkę wiadomości z kolejki SQS i przekazuje je do funkcji Lambda. Jeśli w kolejce nadal znajdują się wiadomości, Lambda stworzy nowe procesy do przeprowadzania pollingu, nawet 60 instancji w każdej minucie.
Maksymalnie możemy mieć 1000 instancji.
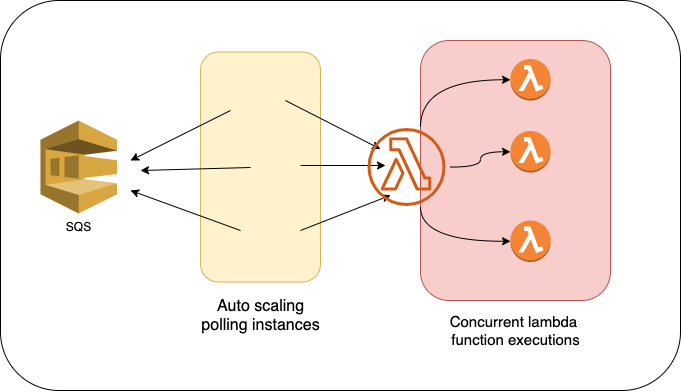
Zdjęcie zrobione przy pomocy http://draw.io/
Problemem jest tutaj to, że skalowanie instancji przeprowadzających polling nie jest bezpośrednio połączone ze współbieżnością funkcji lambda. Jeśli Twoja funkcja osiągnie limit współbieżności, podnosząc liczbę instancję przeprowadzających polling, i nie może obsłużyć nowych żądań, to zdławi konsumpcję wiadomości.
Odrzucone w ten sposób wiadomości powrócą do kolejki po wystąpieniu visibility timeout i mogą się finalnie znaleźć w kolejce dead-letter. Problem ten może wystąpić, kiedy współbieżność Lambdy zostaje ustawiona na niską wartość (np. od 1 do 30).
Reprodukcja problemu
Dla lepszego zrozumienia stworzyłam POC, w którym zbudowałam funkcję lambda ze współbieżnością ustawioną na 5. Zadaniem mojej funkcji lambda było wzięcie danych wejściowych i przejście w stan spoczynku na 5 sekund. Oto kod dla funkcji lambda.
import json
import time
def lambda_handler(event, context):
print("Sleeping")
time.sleep(5)
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
Zezwoliłam na mapowanie źródła zdarzenia w Lambdzie dzięki SQS, ustawiając rozmiar przetwarzanej paczki na jeden i re-drive limit na 3. Jeśli wiadomości zostanie odrzucona więcej niż 3 razy, to ląduje ona w DLQ. Obserwowałam działanie przy zwiększaniu ruchu do około 2000 wiadomości w SQS. W kolejce dead-letter było około 52 wiadomości.

Zdjęcie z konsoli AWS
Co należy zrobić?
Niestety nie istnieje dla tego bezpośrednia konfiguracja. Następujące rekomendacje AWS mogą jednak pomóc, aby zmniejszyć prawdopodobieństwo takiego scenariusza.
- Ustaw visibility timeout SQS na przynajmniej 6 razy wyższy niż czas wykonania Twojej funkcji lambda. Pozostały czas pozwala Lambdzie na ponowne uruchomienie wykonania funkcji, jeśli została ona odrzucona podczas przetwarzania poprzedniej grupy wiadomości.
- Ustaw maxReceiveCount w polityce re-drive w kolejce na przynajmniej 5. Da to wiadomościom większą szansę na przetworzenie ich przed wysłaniem do kolejki dead-letter.
- Skonfiguruj kolejkę dead-letter, aby nie kasowała wiadomości, tak, żeby móc je powtórzyć ponownie później.
Oryginał tekstu w języku angielskim przeczytasz tutaj.