Wprowadzenie do podstaw SQL-a

Podczas nauki data science w Metisie, jedną z rzeczy, których musieliśmy się nauczyć, był Structured Query Language (SQL). SQL był dla mnie czymś nowym, więc poświęciłem trochę czasu, aby go poznać i zrozumieć, jak działa.
Postanowiłem stworzyć przewodnik, który będzie zawierał wszystkie podstawy języka SQL, abym mógł do niego wracać w trakcie mojej nauki o danych. Mam nadzieję, że Tobie również pomoże. Kod źródłowy do tutorialu znajdziesz na moim GitHubie.
W tym artykule przejdziemy przez następujące zagadnienia:
- Podstawowe zapytania.
- Filtrowanie (klauzula where).
- Wiele warunków
- Sortowanie wartości.
- Unikalne wartości.
- Funkcje agregacji.
- Grupowanie według.
Dane
Do tych przykładów użyję bazy danych Chinook z samouczka SQLite.
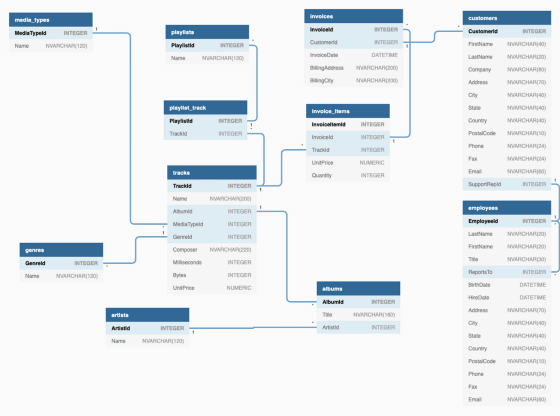 Baza danych Chinook w całej okazałości
Baza danych Chinook w całej okazałości
Patrząc na bazę danych Chinook, nazwy na górze każdej tabeli są wyświetlane na ciemnoniebieskim tle (media_types, playlists, employees itp.).
W każdej tabeli znajdują się kolumny, takie jak ArtistId, Name, Title, InvoiceDate itd. Aby uzyskać dostęp do informacji w każdej z tych tabel, wykorzystujemy SQL.
Podstawowe zapytania
Zacznijmy od prostych rzeczy. Aby pobrać wszystkie kolumny i wiersze z tabeli (użyjmy tabeli utworów), użyjemy:
SELECT *
FROM tracks;
To zwróci 3503 wierszy danych z 9 kolumnami.
Normalnie nie chcielibyśmy widzieć wszystkich danych w tabeli w ten sposób i moglibyśmy użyć tego do szybkiego sprawdzenia kilku wierszy, upewniając się, że nic dziwnego się nie dzieje:
SELECT *
FROM tracks
LIMIT 10;
To zapytanie działa tak samo, jak to powyżej, ale tym razem ogranicza wyniki do pierwszych 10 wierszy/wyników.
Filtrowanie (klauzula where)
Możemy wejść nieco głębiej w nasze zapytania za pomocą filtrowania.
Korzystając z tej samej tabeli, wyobraź sobie, że chcieliśmy sprawdzić, jaka jest 222. piosenka na liście.
Aby to zrobić, użylibyśmy klauzuli WHERE:
SELECT name, composer
FROM tracks
WHERE trackid = 222;
Spowoduje to wyświetlenie Vida Boa od Fausto Nilo-Armandinho.
Idąc o krok dalej, możemy użyć wielu operatorów w klauzuli WHERE, aby znaleźć wiersze danych pasujące do tego, co chcemy otrzymać:
SELECT *
FROM tracks
WHERE milliseconds>300000
AND bytes<5000000;
Spowoduje to wyświetlenie trzech utworów, które pasują do obu filtrów. Dzięki klauzuli WHERE możemy znaleźć konkretne dane, które są zgodne dokładnie z tym, czego potrzebujemy do naszej analizy.AND/OR są powszechnie używane w zapytaniach SQL.
Sortowanie wartości
Jeśli dodasz ORDER BY z nazwą kolumny, zwróci to informacje z tabeli uporządkowanej według tej kolumny, w porządku rosnącym (domyślnie jest sortowanie rosnące).
SELECT *
FROM tracks
ORDER BY name;
Zwraca to wszystkie wiersze w tabeli utworów, uporządkowane według tytułu piosenek (zaczynając od „40” i kończąc na Último Pau-De-Arara).
Aby to zmienić i uzyskać informacje w kolejności malejącej:
SELECT *
FROM tracks
ORDER BY name DESC;
Zwróci to tę samą listę, ale w odwróconej kolejności.
Unikalne wartości
Czasami będziemy pracować z bazami danych, które będą zawierać mnóstwo zduplikowanych informacji. Aby temu sprostać, wykorzystamy klauzulę DISTINCT:
SELECT DISTINCT(composer)
FROM tracks;
To zapytanie usuwa zduplikowane wartości w kolumnach autorów i zwraca rzeczywistą ilość autorów. Ilość wierszy ograniczy się z ilości 3503 do 853.
Funkcje agregacji
W SQL-u jest 5 najważniejszych funkcji agregacyjnych:
COUNT()SUM()AVG()MIN()MAX()
Dzięki tym funkcjom możemy zacząć manipulować danymi jeszcze dokładniej, aby uzyskać bardziej wnikliwe wyniki.
Oto kilka przykładów zapytań:
SELECT COUNT(*)
FROM tracks
WHERE name LIKE 'a%';
Funkcja działa w tabeli utworów, wyszukuje i zlicza wszystkie nazwy utworów, które zaczynają się na literę A. Ten kod generuje 199 utworów zaczynających się na literę A.
SELECT MAX(unitprice)
FROM invoice_items;
Zwraca to 1,99, maksymalną cenę dowolnego przedmiotu w tabeli invoice_items.
Grupowanie według
Klauzula GROUP BY zwykle używana jest w połączeniu z funkcją agregującą. Grupuje wiersze według danej wartości kolumny, a następnie oblicza agregat dla każdej grupy.
SELECT composer, SUM(milliseconds)
FROM tracks
GROUP BY composer;
Zwraca całkowitą ilość czasu (w milisekundach) dla każdego kompozytora w tabeli.
SELECT composer, COUNT(trackid)
FROM tracks
GROUP BY composer;
To zapytanie zlicza liczbę ID ścieżek na kompozytora.
Podsumowanie
Mam nadzieję, że jest to coś, co pomoże Ci lepiej zacząć naukę trudniejszych zagadnień SQL-a. Przyjemnego kodowania i zgłębiania wiedzy dalej samodzielnie!
Oryginał tekstu w języku angielskim przeczytasz tutaj.