What does the role of Data Scientist mean in practice?

I don't know how often I've heard that 'data science' is the sexist job of the 21st century. Also, if I've gotten a cent for each time that I've seen Conway's famous Venn diagram, I'd be somewhat richer. But after my ten years in the industry, I still have no clue why most companies use the generic term data scientist instead of a more specialized job description.
For software engineers, there is a distinction between frontend / backend / fullstack developer. And to be even more specific, the programming language is part of the job description.
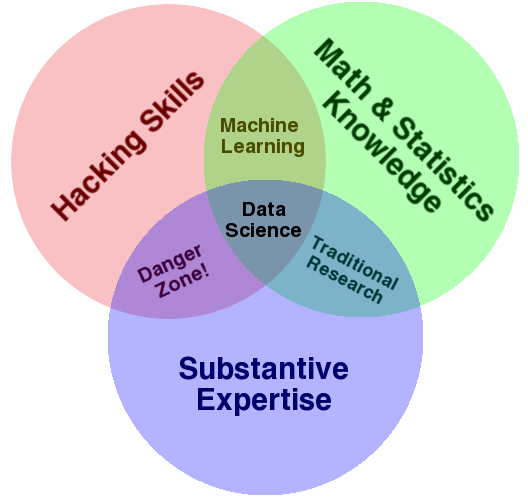
Let's break down different types of data science roles and find unique names for each of them.
- The unicorn:Can do everything from building data pipelines to putting machine learning models in production.
- The researcher:Toys around with the latest model and tries to optimize metrics to the 4th digit.
- Machine Learning engineer:Optimizes the current code and potentially the data flow.
- Business Analyst:Evaluate if a data science solution is needed and feasible from the business perspective.
What are the core skills for each role?
- The unicorn:I've never seen one!
- The researcher:Mathematical / Statistical background (often with a Ph.D.) and proficiency with Python and R.
- Machine Learning engineer:Solid understanding of (non) SQL databases and programming languages.
- Business Analyst:Can get information from various sources and determine if a data science solution is needed at all.
Organization models
This is roughly the setting for most companies that get started with their data science departments. Now in an organization where models are going into production, there are two options.
Option 1: Hand over the PoC Code to the engineering department and hope for the best.
Option 2: Let the researchers do the implementation together with machine learning and software engineers.
While Option 1 might look great at first sight there are severe drawbacks. My personal experience is to avoid this like the plague.
- Hard to implement Data Science solutions in other (i.e., non Python) languages. What might be simple in Python is very hard in Java.
- Different behaviors of the same function. I spent some time debugging the code to understand that the quantile function has a different default
- No ownership of the model: What happens if the model needs to be changed?
Option 2 might take longer and require a cultural change. This also changes how data scientists interact with other parts of the company.
Let's call data scientists that can focus on the production readiness of their models from now on productive data scientists.
New role ML OPS
The next stage, once the model is in production, is to transition into a maintained mode and slowly fade out the productive data scientists out of the project. This is where the new role of ML OPS analyst comes into play. This goal is:
- Monitor the quality of input and output.
- First level support for issues and categorize them according to severity.
- Explain the model and the results to stakeholders.
For the last couple of years, GfK has put over 600 Machine Learning models into production that are in use. We are currently building up a practice of MLOPS analytics. If you want to be part of this journey reach out to …