O przyspieszeniu SQL, czyli jak wykorzystać Trino i Cassandrę

Jeśli informatyka (ang. computer science, niem. Informatik) to nauka zajmująca się przetwarzaniem informacji to te dane musimy najpierw skądś pozyskać i często trwale zapisać. Dawno temu (przy czym w naszej branży jedni za dawno uważają dwa lata a frontendowcy jakieś trzy miesiące), ale “dawno” czyli w czasach kiedy nasi najstarsi koledzy “na zaliczenie” używali jeszcze kart perforowanych, świat przetwarzania danych powszechnie używał “baz nosqlowych”.
Wstęp, czyli znowu tam gdzie kiedyś?
Oczywiście nikt tego tak nie mógł nazywać, choćby z powodu że nie istniał jeszcze SQL. Aż wreszcie pojawił się deklaratywny Structured Query Language, z chyba najbardziej przełomowym standardem SQL-92, który na lata (dziesięciolecia!) bezsprzecznie zapanował nad myśleniem o przechowywaniu i przetwarzaniu danych. Określenia “relacyjna” i “sqlowa” baza danych stały się synonimami.
Załącznikiem do wpisu jest repozytorium git, które zawiera kompletne środowisko.
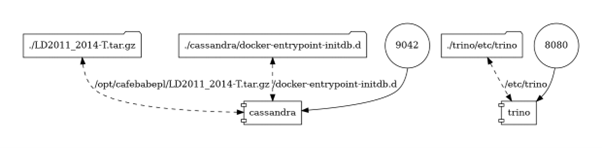
Do uruchomienia potrzebujemy “jedynie” Dockera.
git clone github.com/cafebabepl/blog-bez-sqla-sie-nie-da-spojrzenie-w-strone-trino.git
cd blog-bez-sqla-sie-nie-da-spojrzenie-w-strone-trino
git checkout czesc-1
docker-compose -p blog up -dPrzygotowanie danych
Spróbujemy oprzeć nasze rozważania o jeden ze zbiorów danych dostępnych na Smart Meter Data Portal, konkretnie ElectricityLoadDiagrams20112014 Data Set. Przykładowy dataset zawiera informacje o zużyciu energii elektrycznej dla 370 punktów poboru/klientów w Portugalii, w okresie 2011-2014, mierzone w interwałach 15 minutowych.
Dane udostępnione są w postaci pliku tekstowego, gdzie każdy wiersz zawiera czas końca 15 minutowego interwału a następnie wartość mocy dla każdego klienta (kolumna per klient), np.
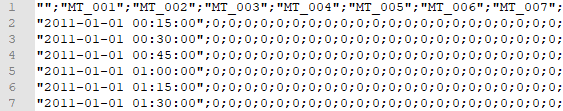

Na potrzeby załadowania i późniejszego przetwarzania danych “wypada” dokonać transpozycji tych danych. Operacja zaimplementowana jest w skrypcie import2.sh. W skrócie to pętla w pętli i kilka instrukcji do właściwego formatowania danych i pliku wyjściowego. Wynikiem wykonania skryptu jest plik LD2011_2014-T.csv
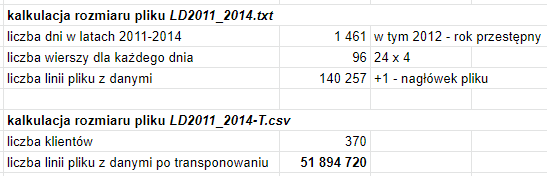
Poniższy rysunek zawiera kalkulacje liczby wierszy dla plików wejściowych.
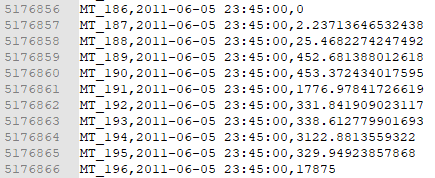
Po wykonaniu skryptu możemy, z grubsza, zweryfikować poprawność naszego pliku:
![]()
Przygotowanie pliku wejściowego z danymi jest tylko elementem naszego story. Podczas lektury nie ma potrzeby wykonania skryptu. Gotowy skompresowany plik LD2011_2014-T.tar.gz jest elementem naszego repozytorium.
W ramach dygresji spróbujmy wyobrazić sobie skalę danych o podobnym charakterze dla polskiego rynku energii elektrycznej (docelowo). Nie chodzi o precyzyjne oszacowanie, z dokładnością do petabajta (sic!), ale określenie rzędu wielkości. Przyjęte wartości są zgrubne (dla uproszczenia) i mogą się różnić w zależności od realizacji (konkretne wdrożenie, konfiguracja, optymalizacja) ale pokażą nam pewną skalę.
Zamiast 370 klientów przyjmujemy prawie 18 mln odbiorców (za: URE) za okres 5 lat. Zakładamy, że liczniki inteligentne (tzw. AMI) mierzą więcej niż jeden składnik (dla kalkulacji przyjęto 5). Przy takich założeniach otrzymujemy > 15*1012 “porcji” danych - być może wierszy w jakiejś tabeli. A jeśli ta tabela będzie w bazie danych Cassandra i przyjmiemy “metodą ekspercką” pewne współczynniki (wsp. redundancji - pewne dane zapisujemy wiele razy ze względu na “filozofię” C*, rozmiar wiersza itd.) wynikiem naszej kalkulacji jest > 13 PiB…

(Przykładowa kalkulacja wielkości danych dla polskiego rynku energii elektrycznej)
Co to jest Cassandra?
Apache Cassandra to rozproszona baza danych NoSQL (to ważne!) typu open source, której zaufały tysiące firm (to nie wiem czy ważne)... Skalowalność liniowa i sprawdzona odporność na awarie (...) sprawiają, że jest to idealna platforma dla danych o znaczeniu krytycznym (za: cassandra.apache.org)
NoSQL pierwotnie odnosiło się do “nie SQL”. Potem, przynajmniej przez niektórych, zaczęło być rozwijane jako “Not only SQL”. Chyba nadmiernie romantycznie i… optymistycznie.
Gdyby połączyć skalowalność, odporność na awarie, SQL i do tego dodać “coś jeszcze” powstałoby narzędzie idealne, “do wszystkiego”. Nikt nie potrzebowałby już inżynierów i architektów którzy potrafiliby odpowiednio dobrać narzędzie do potrzeb, nasza nieodzowność by spadła. To byłby koniec legend o wysokościach zarobków w branży IT.
Baza NoSQL, w szczególności Cassandra, by design nie jest zamiennikiem relacyjnej bazy danych. W przypadku C* nieco zamieszania wprowadza tutaj CQL (Cassandra Query Language), który na pierwszy rzut oka, łudząco przypomina SQL. Oferuje polecenia DDL i DML. Dane zorganizowane są w tabele, wiersze i kolumny… Nie wspiera jednak operacji JOIN, wprowadza reguły użycia kluczy (partition key, clustering key) w klauzulach WHERE itd.
Najważniejsza w moim odczuciu różnica, niejako mentalna, to jednak sposób modelowania danych. Jest to świetnie opisane w publikacji Artem Chebotko, Andrey Kashlev, Shiyong Lu, “A Big Data Modeling Methodology for Apache Cassandra”, 2015 z której pochodzi poniższy rysunek.
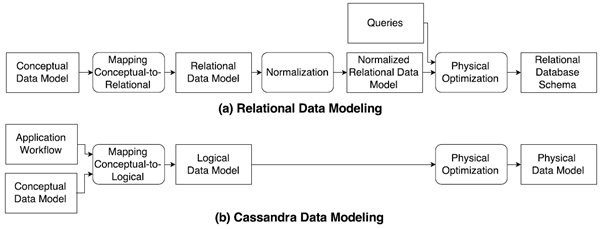
W skrócie, nasza baza przestaje być “schema oriented” (zapiszmy dane w n-postaci normalnej a potem ułożymy zapytanie w zależności od naszych potrzeb, których być może jeszcze nie znamy) a staje się “query oriented” (zapiszmy dane w takiej postaci żebyśmy potrafili odpowiedzieć na pytania które chcemy zadać i już wiemy o co będziemy pytać).
Struktura naszej bazy składa się z keyspace eld, który zawiera jedną tabelę value_by_client_id_time. Kluczem partycjonującym jest kolumna client_id.
Jak podłączyć się do naszej Cassandry?
Cassandra uruchomiona jest na porcie 9042. Aby się do niej podłączyć możemy wykorzystać dowolnego klienta, który wspiera C* lub uruchomić klienta cqlsh na “jednym z naszych nodów”, np.

Co to jest Trino?
Trino to szybki, rozproszony silnik zapytań SQL do analizy dużych zbiorów danych (za: trino.io). Trino “rozumie” SQL ale nie oznacza to, że jest zamiennikiem dla klasycznych relacyjnych baz danych. Trino jest narzędziem typu OLAP (Online Analytical Processing) zaprojektowanym do obsługi różnych źródeł danych: od baz relacyjnych (np. PostgreSQL, Oracle), przez NoSQL (np. Cassandra, MongoDB) czy choćby Kafka i Prometheus.
Trino dostarcza tzw. konektory do obsługi każdego źródła danych. Konektor jest odpowiednikiem sterownika, za pomocą którego łączymy się z jakąś bazą danych. Wprowadza 3-warstwową strukturę obiektów: tabelę, schemat i katalog.
Tabela (table) to zbiór wierszy zorganizowanych w kolumny. Nie ma tu żadnych podtekstów, jest to dość oczywiste i intuicyjne, całkowicie analogicznie jak w jakiejkolwiek relacyjnej bazie danych. Mapowanie na tabelę będzie zależeć jednak od rodzaju źródła danych i zdefiniowane jest w konektorze. W relacyjnych bazach danych tabelą będzie… tabela, jeśli źródłem będzie MongoDB tabelą będzie kolekcja (collection), dla Kafki topic, index dla Elasticsearch czy w końcu… table dla Cassandry.
Schemat (schema) to sposób organizacji tabel. I znów w zależności od źródła danych będzie to schema, database czy dla Cassandry keyspace.
Katalog (catalog) zawiera schematy i definiuje źródło danych poprzez konektor (connector).
Katalog definiujemy w pliku .properties - nazwa pliku będzie nazwą katalogu. W pliku określamy przede wszystkim typ konektora connector.name oraz dodatkowe właściwości w zależności od użytego konektora, np. Cassandra connector
Jak podłączyć się do naszego Trino?
Trino uruchomione jest na porcie 8080. Aby się podłączyć do “klastra” można użyć dowolnego klienta, który wspiera Trino, wykorzystać dostarczanego CLI, np.

albo uruchomić klienta na naszym koordynatorze, np.

SELECT cośtam FROM cośtam
Mamy środowisko to teraz musimy wygenerować jakiś problem (“nie ma problemów, tylko wyzwania”), który postaramy się rozwiązać a to z kolei być może uzasadni wykorzystanie wybranych narzędzi.
Zapytanie 1.
Zlicz ile jest wierszy w tabeli value_by_client_id_time?
Repozytorium zawiera skrypt, który automatycznie ładuje dane w momencie uruchamiania bazy danych z wykorzystaniem instrukcji COPY
![]()
Gdybyśmy jednak polecenie uruchomili ręcznie z linii poleceń, po wykonaniu otrzymamy podsumowanie, które pozwoli nam także zweryfikować liczbę przetworzonych wierszy:
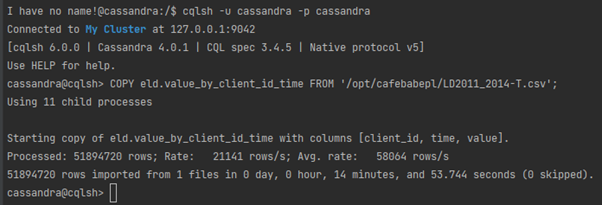
Problem nie jest wielce wyuzdany (ani potrzebny?) ale spróbujmy zweryfikować na początku czy nasza baza zawiera dane, których oczekujemy.
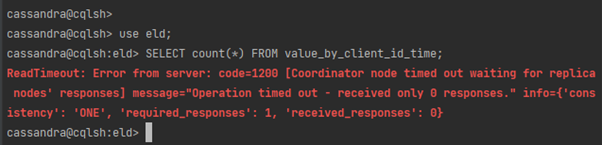
Zaczęło się może niezbyt obiecująco, ale na usprawiedliwienie możemy przyjąć, że nie do tego została stworzona Cassandra. Ma odpowiadać szybko na konkretne zapytania a nie zliczać wiersze rozsiane “po różnych nodach” więc, domyślnie po 10 sek. dostajemy timeout. Możemy próbować zmienić, najpierw na poziomie serwera właściwy parametr _timeout_, ale rozwiązanie “ma krótkie nogi”:
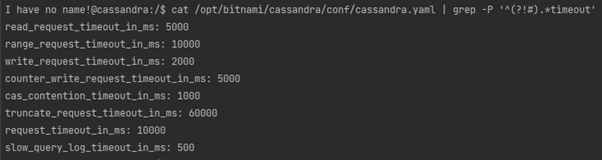
Aaaa dobra. Komu tam jest potrzebny count? Jeśli jednak już przywlekliśmy ze sobą to Trino to może…
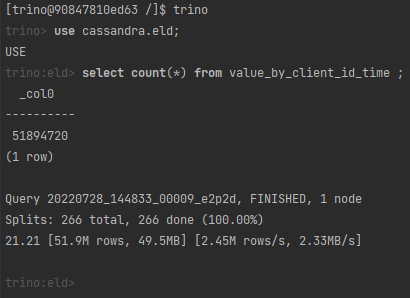
Jupi! Zgadza się. Spokojnie możemy “pytać dalej”.
Zapytanie 2.
Zwróć szczegółowe informacje o zużyciu energii elektrycznej dla klienta MT_017 w dniu 28 lipca 2012 r.
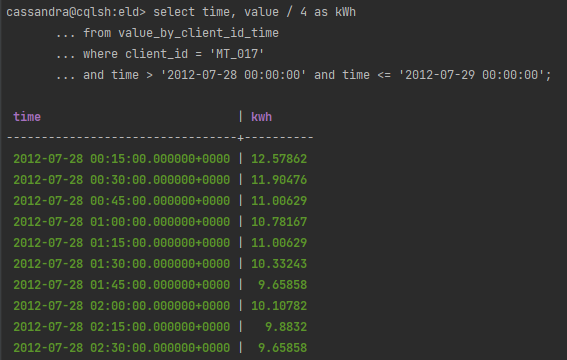
Wygląda nieźle. W odpowiedzi dostajemy 96 wierszy. Zapytanie właściwie wykorzystuje zarówno partition key jak i clustering key. Zaprojektowana struktura tabeli pozwala na efektywne wykonanie zapytania tego rodzaju. Nie ma potrzeby wychodzić poza CQL.
Prezentowane rozwiązanie nie jest gotowe do wdrożenia na produkcję. Ze względu na uproszczenie naszego rozumowania całkowicie została pominięta prawidłowa obsługa stref czasowych. A to już temat na zupełnie inny artykuł…
Zapytanie 3.
Zwróć sumaryczne zużycie energii elektrycznej dla klienta MT_270 w podziale na lata kalendarzowe.
Wyjdźmy tym razem “od końca”, myśląc w SQL. Zapytanie nie wydaje się zbyt skomplikowane. Zasadniczo to prosta suma z warunkiem w klauzuli WHERE na identyfikator klienta i GROUP BY rok wyciągnięty z daty. Brnąc w szczegóły, żeby zapytanie zwróciło poprawne wyniki rok musimy wyciągnąć nie z końca ale z początku okresu mierzonego zużycia (bo np. odczyt z 2012-01-01 00:00:00.000 powinien zostać zaliczony do roku 2011).
W Trino zatem możemy zadać np. zapytanie:
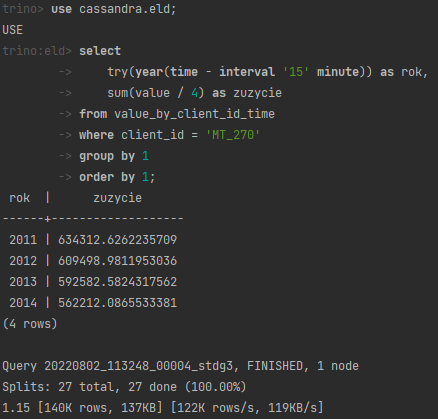
Wróćmy do Cassandry. CQL oferuje operację GROUP BY więc może dałoby się wykorzystać? Brakuje nam funkcji do obsługi dat, ale jeśli jest taka potrzeba możemy dopisać własną UDF (User Defined Function), np.
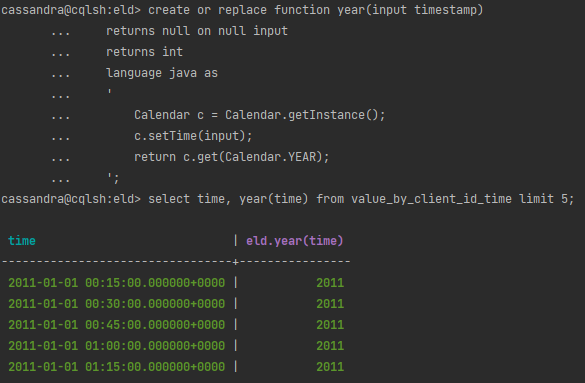
Aby była możliwość definiowania UDF w pliku konfiguracyjnym cassandra.yaml flaga enable_user_defined_functions musi być ustawiona na true. W przypadku naszego projektu demonstracyjnego ustawienie flagi jest wymuszone przez zmienną środowiskową CASSANDRA_ENABLE_USER_DEFINED_FUNCTIONS.
Składając to wszystko być może uda nam się stworzyć analogiczne zapytanie w CQL. Pytanie jednak czy chcemy i czy warto? Jeśliby zapytanie nanieść na oś to na jednym krańcu będą zapytania “transakcyjne” (OLTP), na drugim “analityczne” (OLAP). Nasze ostatnie zapytanie wyraźnie dąży do tych drugich, a Cassandra została stworzona i “lubi” te pierwsze.
Bez zmiany struktury i definiowania własnych UDF może warto zadać serię zapytań. np.
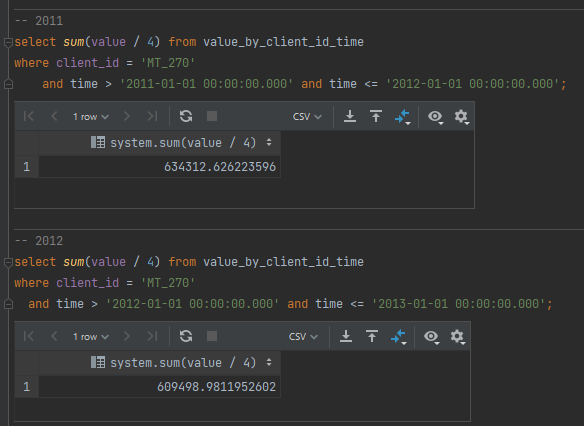
A może warto pomyśleć o nowej strukturze, która będzie przechowywać wyliczone sumy dla klienta i roku, z odpowiednio dobranym kluczem, który umożliwi nam “transakcyjne” odpowiedzi na takie pytania?
Zapytanie 4.
Zwróć sumaryczne zużycie energii elektrycznej dla wszystkich klientów w podziale na lata.
To zadanie z *. Zamiast “rozwiązania” chwila zastanowienia i refleksji (to chyba coś z tych “miękkich” kompetencji). Modyfikacja Zapytania 3. w Trino/SQL jest wręcz trywialna. To czysta analityka! A jak często będziemy zadawać takie zapytanie? Potrzebujemy je do jakiegoś raportu, BI albo serwisowej weryfikacji czy jest to informacja, którą prezentujemy i aktualizujemy na bieżąco? A jak często zmieniają się dane odczytowe sprzed kilku lat?
Odpowiednie narzędzie do danego problemu (psss! wyzwania)...
Co dalej?
Postukaliśmy, podumaliśmy i być może widać już jakieś obszary zastosowania.
W kolejnej części skupimy się na operacjach typu join. W relacyjnych bazach to podstawowa operacja - w końcu dane są “w relacji” po to żeby je ze sobą łączyć. Ponieważ w Trino ostatecznie wszystko jest tabelą więc spróbujemy połączyć dane z naszej bazy z odczytami (Cassandra) z bazą danych klientów (może PostgreSQL a może MongoDB?) i z bazą danych zdarzeń urządzeń (Apache Kafka).