Szybki i łatwy GraphQL dla Django

GraphQL to język zapytań, który powstał w 2015 roku. Został napisany przez programistów Facebooka, szukających sposobu na zwiększenie wydajności ich aplikacji mobilnej. Język szybko stał się popularny we frameworkach frontendowych. Programiści JS po prostu lubią budować swoje zapytania omijając różne ograniczenia, m.in. te wynikające z RESTful API.
Z poziomu backendu, zapotrzebowanie na budowanie przyjaznego API można realizować na wiele sposobów. Często wykorzystuje się w tym celu Hasurę, swego rodzaju nakładkę na bazę danych, oferującą zarówno endpoint GraphQL, jak i interfejs do zarządzania. Niedawno trafiłem na podobne połączenia Hasury z Flaskiem. Pomyślałem więc, że równie dobrze mogę użyć Django. Rozwiązanie to przetestowałem i tak powstał ten artykuł. Postaram się w nim opisać, jakie są zalety i wady takiego podejścia. Zapraszam zatem do lektury.
Krótko o samych elementach
Skoro ustaliliśmy już, że projekt ma wykorzystywać GraphQL, to możemy się skupić na tym, do czego zostaną użyte opisane tutaj narzędzia i w jaki sposób usprawniają one funkcjonowanie aplikacji. Warto przetestować samemu taką konfigurację – zwłaszcza, że dosyć szybko uzyskujemy projekt POC lub nawet MVP. Mam nadzieję, że wnioski z tego artykułu pozwolą nam odpowiedzieć na pytanie, czy jest to rozwiązanie tylko na początkową fazę projektu, czy wręcz przeciwnie – można je wykorzystywać na dużą skalę. Na początek omówię więc wykorzystane technologie, w dalszej części sposób ich połączenia, a na koniec mocne i słabe strony takiego podejścia.
Kilka słów o zastosowanych technologiach
A. PostgreSQL – SQL-owa baza danych, jedna z najpopularniejszych na rynku.
B. Django – framework napisany w Pythonie, działający w połączeniu z bazą danych oferuje pełne funkcjonalności aplikacji webowej. Może działać z zewnętrznym frontendem, a komunikacja przechodzi wtedy przez API. Użycie Django – uprzedzając pytania – należy traktować jako przykład, równie dobrze możemy tu użyć np. Flaska lub Falcona z SQLAlchemy.
C. Hasura – aplikacja współpracująca z PostgreSQL, oferująca zarówno interfejs – API, jak i system zarządzania – dashboard. Umożliwia korzystanie przez frontend z zapytań GraphQL i korzystanie z modelu komunikacji Pub/Sub. Dodatkowo oferuje komunikację z innymi usługami.
Jak to działa?
Widać niemal od razu, że w naszym przypadku będziemy budować rozwiązanie backendowe, a do pełnej funkcjonalności zabraknie części frontendowej. W wielu projektach jest to działanie celowe. Uniezależniamy się w ten sposób od warstwy prezentacji. W naszym przypadku komunikacja odbywa się poprzez zapytania GraphQL do Hasury.
Dlaczego GraphQL? Dzięki temu językowi komunikacji z bazą danych zyskujemy kilka niewątpliwych zalet:
- Ograniczenie przesyłanych danych;
- Sprawne przedstawianie zależności między obiektami;
- Zapytania batchowe (grupowe);
Dodatkowo, w przedstawionym rozwiązaniu otrzymujemy od razu model subskrypcji zapytań (pub/sub) – czyli dostęp do rekordów bazy “na żywo”. Warto jeszcze wspomnieć, że Hasura przebudowuje zapytania na SQL bardzo efektywnie, dzięki czemu nie wymaga to od programistów frontendu szczegółowej znajomości baz danych.
Jak w naszym przypadku wygląda model komunikacji?
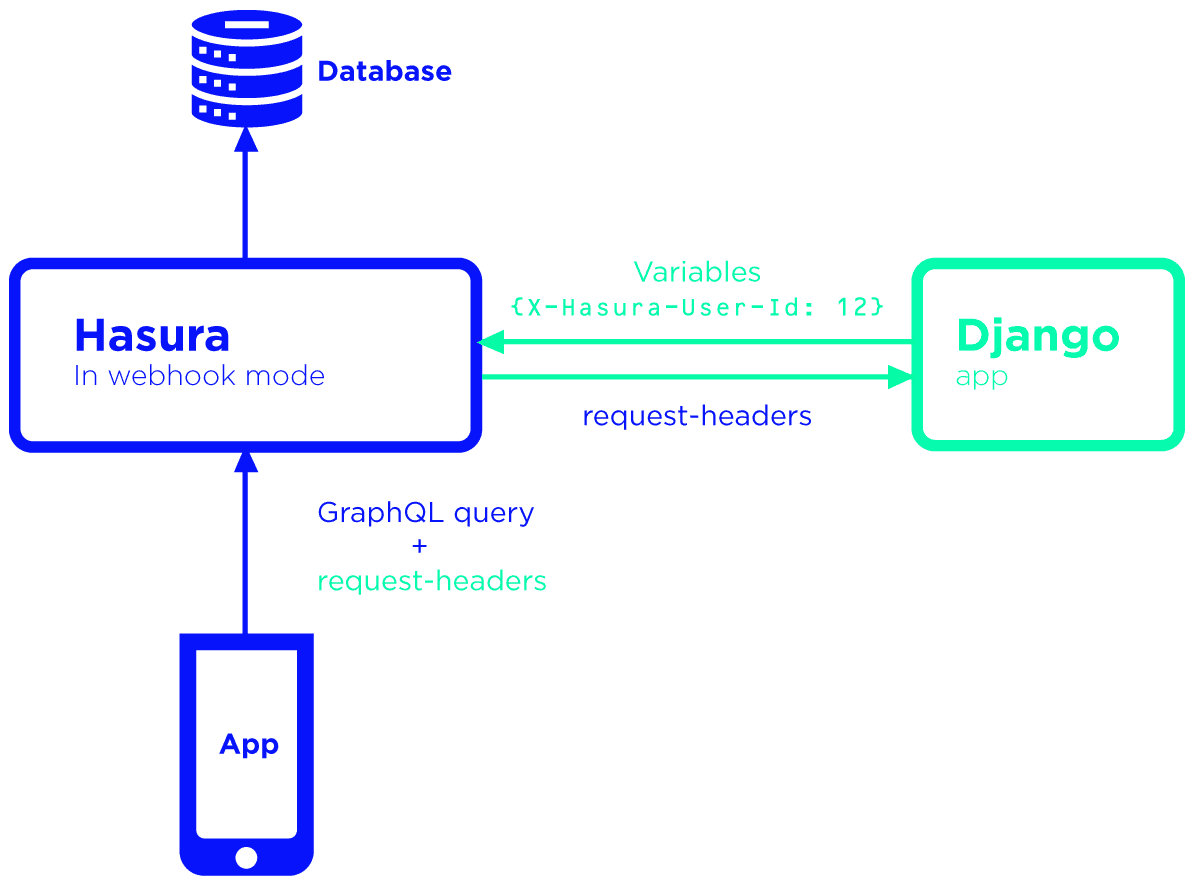
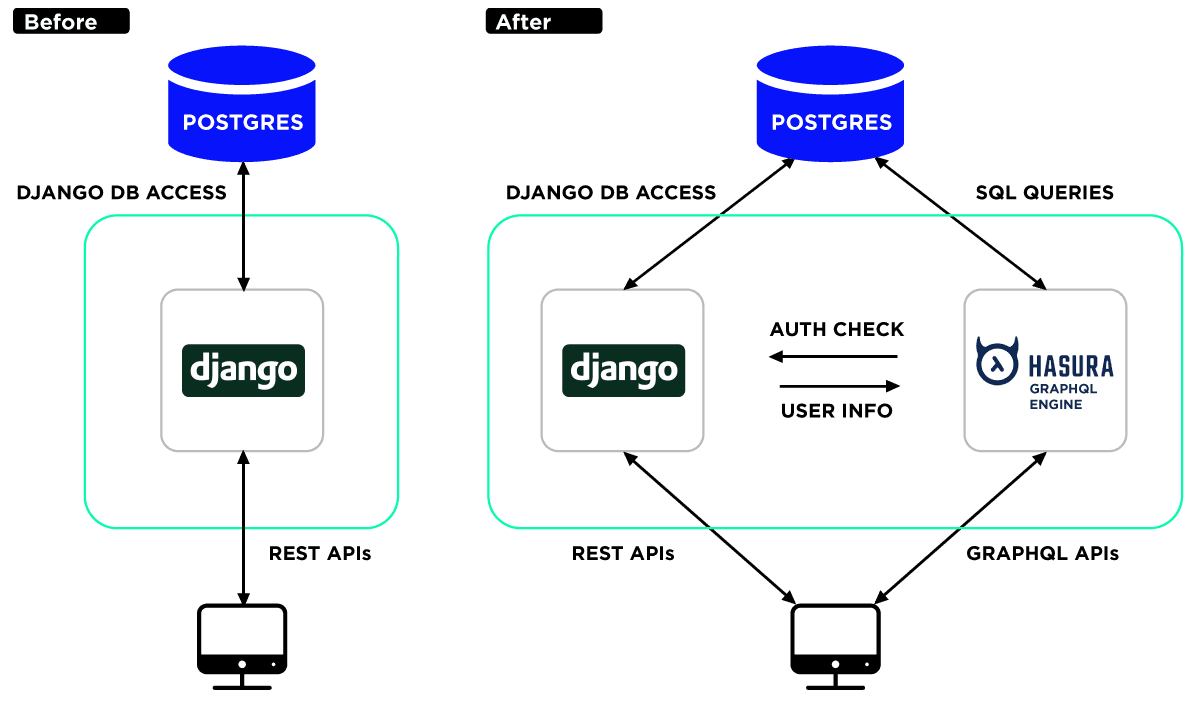
Z bazy danych korzysta zarówno Hasura, jak i Django, natomiast frontend korzysta z API wystawionego przez Hasurę. Do zarządzania wszystkimi modelami z punktu widzenia superużytkownika można z kolei wystawić dashboard przez Django.
Framework ten, za pomocą Graphene, udostępnia API do operacji niebazodanowych – np. do płatności czy obliczeń. Jeżeli zaistniałaby taka potrzeba, możemy umożliwić dostęp dla frontendu do całości lub części Django API – wystarczy skonfigurować dowolny endpoint z Django w Hasurze. Django może, ale nie musi wystawiać dodatkowo REST API na potrzeby komunikacji z innymi serwisami i/lub webhookami z Hasury.
Wady i zalety
Wady
A. Redundancja API
Gdy w Django endpointy wystawione są z użyciem Graphene, (GraphQL), tak naprawdę można by się zastanowić, czy Hasura jest w ogóle potrzebna. Należy jednak pamiętać, że w przypadku jej niezastosowania, zabraknie możliwości odczytu w trybie pub/sub. Oczywiście istnieje biblioteka, która umożliwia wprowadzenie wtedy dodatkowego rozwiązania w tym celu, ale warto rozważyć tutaj nakład nadprogramowej pracy. Dodatkowo, do komunikacji z innymi usługami, Django może potrzebować RESTful API – a skoro w takim przypadku narzędzie to będzie już zaimplementowane, powstaje pytanie, czy można obyć się bez GraphQL.
B. Redundancja panelu zarządzania
Ustawienia modeli i zależności, tworzenie, modyfikowanie i kasowanie obiektów – to wszystko jest możliwe zarówno poprzez panel Hasury, jak i Admin panel Django. Tutaj uważam za zasadne wybranie jednego z paneli i wyłączenie lub zablokowanie dostępu do drugiego.
C. Występowanie sytuacji, w których Django jest zbędne
- Ciężar aplikacji skupiony na frontendzie. Jeśli aplikacja może obsługiwać logikę biznesową w przeglądarce, a działania po stronie serwera skupiają się na bazie danych – lepiej użyć dedykowanego rozwiązania z samą Hasurą;
- Brak dodatkowych usług;
- Wszystkie aplikacje klienckie korzystające wyłącznie z GraphQL, niepotrzebujące wsparcia z REST API (np. do autoryzacji).
D. Występowanie sytuacji, w których Hasura jest zbędna
- Czas i zasoby na rozwinięcie Graphene + Graphene-subscriptions;
- Rezygnacja z GraphQL API.
E. Deployment i zarządzanie
- Niezbędnym będzie podjęcie kilku decyzji odnośnie tego, jaki panel używać, w jakim zakresie i z jakimi ograniczeniami (np. w podsieci);
- Brak konsekwencji w stosowaniu jednego podejścia, może skutkować niespójnością bazy danych.
Zalety
A. Szybki czas MVP
W naszym projekcie możemy zacząć pracę już na etapie posiadania bazy danych ze wstępnymi modelami. Oczywiście, należy tu zwrócić uwagę na bezpieczeństwo – zwłaszcza modeli, do których dostęp powinien być regulowany. Niemniej, dla narzędzi wewnętrznych, wyszukiwarek czy prostych aplikacji CRUD, większość funkcji dostajemy po zaimplementowaniu modeli i włączeniu ich w Hasurze.
B. Wysoka efektywność w przypadku podziału zadań
Nasze rozwiązanie działa dobrze przy odpowiednim rozdzieleniu zadań pomiędzy dostęp do danych a dostęp do usług. Hasura po prostu świetnie sprawdza się przy budowaniu szybkich dostępów typu CRUD oraz filtrowaniu czy wyszukiwaniu przy dostępie do danych. Natomiast nieintuicyjne wydaje się użycie zapytań w GraphQL, np. by wywołać obliczenia lub inne zadania asynchroniczne.
C. Możliwość wykorzystania Hasury do zapytań do bazy danych
To może okazać się bardzo dużym plusem przy testach wydajnościowych. Hasura tłumaczy zapytania na SQL, przy okazji je optymalizując. Pomijamy całą nadmiarowość modeli ORMowych.
D. Możliwość zarządzania backendem poprzez panel administratora Django
Jest to rozwiązanie sprawdzone, pozwalające dodatkowo na oprogramowanie sposobu i ograniczeń tworzonych i/lub modyfikowanych obiektów. Cechuje je:
- Prostota – w zaledwie paru linijkach dodajemy obsługę modeli w panelu;
- Bezpieczeństwo – możemy implementować swoją weryfikację wprowadzanych danych i zagwarantować ich spójność, a nawet ograniczać dostęp do modeli i operacji na obiektach.
E. Zarządzanie migracjami
Można je wykonywać na dwa sposoby, dlatego też jest to kolejne miejsce, na które trzeba uważać. Najprostszym rozwiązaniem będzie wyłączenie migracji w Hasurze i utrzymanie wszystkich zmian w Django – zapewnia to zarówno spójność, jak i historię zmian.
F. System webhooków
Jedna z najciekawszych funkcjonalności Hasury – dowolna operacja może aktywować wywołanie skonfigurowanego zapytania. Jest to też podstawa do rozwiązań, w których chcielibyśmy zrezygnować z Django. Duża możliwość parametryzacji zapytań pozwala na obsługę nawet bardziej skomplikowanych poleceń, np. autoryzacji.
G. Połączenia z innymi usługami poprzez wykorzystanie Pythona (Django), np. z:
- Autoryzacjami;
- Płatnościami;
- Usługami chmurowymi;
- Zadaniami asynchronicznymi.
H. Możliwość wpięcia dowolnego GraphQL-owego API z innej usługi, czyli np. wykorzystanie innych serwisów i/lub zapytań poprzez Django
I. Import i eksport konfiguracji
Hasura ma dedykowane opcje do importu i eksportu konfiguracji, działające zarówno z poziomu strony, jak również z poziomu linii komend. Czyni to wszystkie zmiany banalnymi do automatyzacji przy procesach CI/CD.
Podsumowanie
Gdy po raz pierwszy spotkałem się z taką architekturą, był to projekt w którym zamiast Django wykorzystywaliśmy Flask. Na pierwszy rzut oka wydawało się to wtedy nadmiarowe i zbędne. Zalety widać dopiero po chwili, zwłaszcza w przypadku serwisów, które obsługują dużo zapytań i aplikacji zewnętrznych, np. frontend potrzebuje szybko (i szybkiego) dostępu do danych. Po ustaleniu struktury bazy danych, następowała konfiguracja przytoczonego rozwiązania. Dla frontendu dostęp był gotowy praktycznie od razu, backend działał z kolei nad autoryzacją i spinaniem innych usług.
Tak czy inaczej - oba zespoły (frontendowy i backendowy) mogły już spokojnie skupić się na swoje pracy, gdy w innych przypadkach wymagane były dalsze ustalenia odnośnie szczegółów protokołu i komunikacji. Wybór aplikacji backendowej jest kwestią wielu wypadkowych. Ja chciałem sprawdzić, jak Hasura współpracuje z Django, dlatego w artykule testowałem właśnie takie rozwiązanie. Wziąłem pod uwagę problemy wynikające z redundancji dostępu do bazy danych i zalety szybkiego budowania aplikacji. Po drodze pojawiły się opisane wnioski. Sam schemat takiego systemu jest dosyć prosty. Wymaga jednak trochę wkładu pracy na etapie wstępnej konfiguracji. Polecam użycie dockera do poszczególnych usług. Nie ukrywam, że największą zaletą wydają mi się tutaj możliwości administrowania i rozszerzania zarówno dostępu do danych, jak i dodatkowych operacji.
Jak widać, wiele czynników może mieć wpływ na użyteczność łączenia Django i Hasury. Mimo zalet, nie jest ono pozbawione wad. Jestem ciekawy, jak sprawdzi się ono w perspektywie długoterminowej. A ze swojej strony na pewno będę nad nim jeszcze pracował.
O autorze
Łukasz Prasoł, Senior Software Engineer z ponad 10-letnim doświadczeniem. Studiował na Politechnice Wrocławskiej. W trakcie swojej edukacji interesował się programowaniem, zwłaszcza z zakresu algorytmów i optymalizacji. Obecnie skupia się na tworzeniu stron internetowych i systemów sieciowych. Zaczynał w PHP, od kilku lat programuje w Pythonie. Ciągle się uczy, a jego głównym celem jest budowanie wysoce dostępnej i niezawodnej architektury.