Spark dla .NET developerów na przykładzie .NET Core

Zajmiemy się dziś sposobem na łatwą konfigurację Sparka do działania z .NET Core oraz napiszemy pierwszy prosty program dla tej platformy w języku C#.
Konfiguracja środowiska .NET for Apache Spark
Do konfiguracji środowiska developerskiego dla .NET for Apache Spark użyjemy narzędzia Docker. Systemem operacyjnym, w którym będzie wykonywać naszą pracę Linux, jest to także możliwe przy użyciu odpowiedniej wersji Dockera dla Windowsa. W przypadku systemu Windows jest jednak kilka różnic. W szczególności to brak automatycznego ujawniania portów z kontenera i trzeba to mapowanie wykonywać jawnie. W celu przygotowania środowiska ściągamy odpowiednie repozytorium z GitHuba.
Po ściągnięciu tego repozytorium za pomocą komendy build.shbudujemy odpowiednie obrazy dla Dockera. Autor tego repozytorium przygotował także zbudowane gotowe obrazy dla Dockera, które możemy odszukać w głównym repozytorium dla Dockera pod tym linkiem.
Następnie należy je ściągnąć dla naszego systemu. Przygotowane są także obrazy dla systemu Windows. Po wykonaniu tych operacji mamy wstępnie przygotowane nasze środowisko developerskie.
Pierwszy program dla .NET for Apache Spark
Naszym pierwszym programem, który napiszemy będzie, podobnie jak w przypadku Apache Hadoop, program określający najpopularniejszą nazwę ulicy w Polsce. Przypomnijmy teraz jak wygląda nasz plik źródłowy z nazwami ulic. Źródłem jest plik w formacie csv, którego strukturę widzimy na poniższym rysunku.
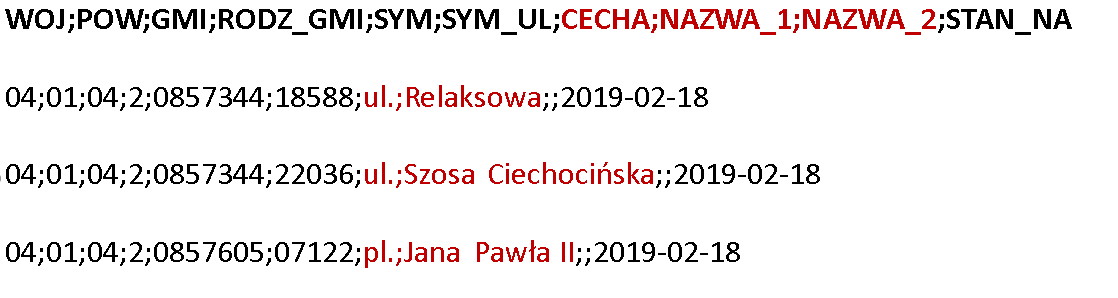
W procesie przetwarzania interesują nas tylko trzy wyróżnione kolumny CECHA, NAZWA_1, NAZWA_2.
W celu napisania programu musimy dodać odpowiedni pakiet nugeta do naszych źródeł jest nim Microsoft.Spark.Sql. W chwili pisania artykułu znajdował się on w wersji 0.12.1. Poniżej widzimy zawartość pliku csproj.
<?xml version="1.0" encoding="UTF-8"?>
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp3.1</TargetFramework>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.Spark" Version="0.12.1" />
</ItemGroup>
<ItemGroup>
<None Update="streets.csv">
<CopyToOutputDirectory>Always</CopyToOutputDirectory>
</None>
</ItemGroup>
</Project>
Do źródeł dodaliśmy również nasz plik streets.csv z nazwami ulic i określiliśmy, że będzie on kopiowany do skompilowanych źródeł. Wykonaliśmy to, by uruchomiony program na platformie Apache Spark potrafił czytać plik i był dla niej widoczny. Dodatkowo nasz program powinien być programem uruchamialnym z metodą Main..
Spójrzmy teraz na źródła naszego programu, które umieściliśmy poniżej.
using System;
using Microsoft.Spark.Sql;
namespace Microsoft.Spark.CSharp.Example.StreetCounter
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Start SparkSession");
SparkSession sparkSession = SparkSession.Builder().AppName("Street Counter").GetOrCreate();
DataFrame dfCsv =
sparkSession
.Read()
.Option("delimiter", ";")
.Schema("WOJ string ,POW string ,GMI string ,RODZ_GMI string , " +
"SYM string , SYM_UL string , " +
"CECHA string , NAZWA_1 string ,NAZWA_2 string , " +
"STAN_NA string")
.Csv("streets.csv");
DataFrame dataIn = dfCsv
.WithColumn("STREET", Functions.ConcatWs(" ", dfCsv["CECHA"], dfCsv["NAZWA_1"], dfCsv["NAZWA_2"]));
DataFrame dataGroup = dataIn
.Select("STREET")
.GroupBy("STREET")
.Count()
.WithColumnRenamed("count","COUNT");
DataFrame dataOut = dataGroup
.OrderBy(dataGroup["COUNT"]
.Desc()
);
dataOut
.Coalesce(1)
.Write()
.Option("delimiter",";")
.Csv("result");
sparkSession.Stop();
Console.WriteLine("Stop SparkSession");
}
}
}
Każdy program rozpoczynamy od dostępu do obiektu SparkSession. Zawiera on kluczowe metody dostępu do Api Apache Spark. Następne linie programu zawierają metodę odczytu naszego pliku csv i przedstawienie go w formie DataFrame. Zauważmy, że do odczytu dodano dodatkowe opcje, w tym wypadku określające inny symbol separatora niż przecinek, a jest nim średnik. Ponadto informujemy Apache Spark poprzez metodę Schema jak wygląda struktura wczytywanego pliku. Określamy nazwę kolumn pod jaką będą przechowywane dane w strukturze DataFrame oraz ich typ. W naszym programie w celu uproszczenia przyjęliśmy, że nazwami kolumn DataFrame będą nazwy z nagłówka pliku CSV oraz typ wszystkich kolumn będzie typem łańcuchowym string.
W następnej linii programu tworzymy nowy DataFrame powstały z poprzedniego i konkatenujemy w nim interesujące nas kolumny CECHA, NAZWA_1, NAZWA_2, gdzie separatorem staje się spacja. Nowo powstała kolumna przyjmuję nazwę STREET.
Kolejna linia programu stanowi wybranie poprzednio utworzonej kolumny STREET z pełną nazwą ulic oraz wykonanie odpowiedniego grupowania po tej kolumnie oraz policzenie wystąpienia danej nazwy. Ostatnie polecenie w tej linii to zmiana nazwy nowo utworzonej automatycznie kolumny count ze zliczeniem wystąpień na nazwę, która nas interesuje, czyli Count.
Dla łatwiejszej analizy danych, dokonujemy sortowania od największej liczby wystąpień do najmniejszej. Operacje tą wykonujemy metodą OrderBy i określamy w niej odpowiedni porządek sortowania od największej liczby wystąpień do najmniejszej.
Ostatnia linia programu stanowi zapis naszego wyniku do pliku csv. Jako że jest to system rozproszony, to dane musimy ze sobą złożyć. W tym celu wykonujemy operację Coalesce i określamy, że interesuje nas jeden spójny plik (w jednej partycji). Następnie określamy opcję zapisu pliku csv. W tym wypadku zmieniamy znowu separator z przecinka na średnik i na końcu określamy, do jakiego katalogu ma Apache Spark zapisać wynik, czyli w tym wypadku result.
Program powinien kończyć się zamknięciem sesji Apache Spark, czyli metodą Stop.
Uruchomienie pierwszego programu dla .NET for Apache Spark
W celu uruchomienia naszego programu dokonujemy jego kompilacji. Powinniśmy rozpocząć instancję przygotowanego obrazu dla Dockera oraz podłączyć do kontenera Dockera katalog z utworzonymi binariami w procesie kompilacji. Polecenie startu kontenera Dockera wygląda w sposób następujący:

Przełącznikiem -v montujemy nasze binaria do kontenera. Należy zwrócić uwagę by ścieżkę podmontować do katalogu /dotnet/Debug w kontenerze, bo tylko takie działanie umożliwia prawidłową pracę z tymi źródłami oraz z Debuggerem.
Przełącznik –network host oznacza w Linuxie automatyczne ujawnianie portów na zewnątrz. W przypadku Windowsa powinniśmy jawnie ujawnić porty kontenera przełącznikiem -p. Interesującymi nas portami są 8080, 8081, 8082, 7077, 6066, 5567, 4040 przeznaczone do dostępu do UI Webowego Spark oraz porty do debugowania aplikacji.
Uruchomienie naszego programu i pracę z nim możemy wykonać w dowolnym środowisku przeznaczonym dla .NET może to być Visual Studio, Visual Studio Code lub Rider. W każdym z tych środowisk mamy dostęp również do Debuggera i możemy pracować z program na Apache Spark jak z normalnym programem konsolowym i go debugować. Tak wygląda przebieg wykonania w przypadku uruchomienia go w środowisku Rider dla Linux:

Po uruchomieniu powstanie katalog result z wynikiem naszego programu i plikiem csv:
Opisywany w tym artykule kod możemy pobrać z GitHuba pod następującym adresem.
Podsumowanie
Podsumowując możemy zauważyć, że przygotowanie środowiska developerskiego dla .NET for Apache Spark nie jest skomplikowane. Konfiguracja całego środowiska opartego na narzędziu Docker sprowadza się do kilku prostych komend. Api do Apache Spark przygotowane przez Microsoft jest także bardzo proste i kompatybilne z przygotowanymi dla innych języków typu Scala, Java czy Python.