Source generators in C# - best practices

With the .NET 5, the source generators were introduced. The amount of cool stuff you can do with it is only limited by your imagination. You can automate a lot of tasks with it. But as always with something new, it’s hard to find the best approach to use it. Today I would like to give you my advice for how to write your source generators in the best possible way, based on my experience.
Before we start
The whole article assumes that you’ll work with Visual Studio. It has, as for now, the best tooling for any kind of tasks important when coding any source generator. Secondly, It’s not a tutorial; if you would like to start with the source generators, check out the great recording from JetBrains. Let’s start with the best practices then!
Generating “markers”
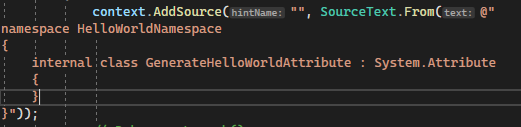
First thing to remember is that very often you will use attributes to mark what you would like to generate and what is the source of data to generate your code. That’s why in official guidelines, it is shown to generate the attributes dynamically by the source generator. You put the code in the form of a string. In my opinion it’s not the best approach to do it.
You must also remember about limitations of the source generation project. Projects that reference your generator can’t use any type inside it (probably that’s why they propose to generate attributes dynamically). However there is a workaround to it and I will show it to you today.
- Create a separate project ex.
Generator.Abstract. Let’s put our marker thereGenerateHelloWorld.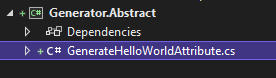
- In the original project Generator, you create linking to the class from the abstract project

What are the advantages of such an approach? Thanks to that you are able to use the compilation time class to, for example, search for the marker usages. For some cases, it can also prevent code duplication. But the most crucial part is about expandability.
Expandability
Thanks to the above approach, you are able to make your source generator expandable. It is very limited though, but still, I think it is nice to have. How does it work? I’ll show it in the example with usage of some data fixtures.
- You create an abstract attribute with all the templates that are needed to generate particular fragments of the code
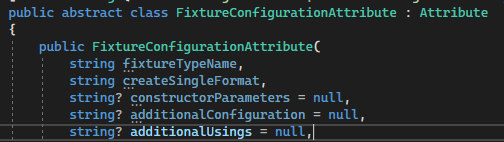
- You create a child attribute; here is an example with
AutoFixtureplusMoq.
- You extract the templates for your generator by the abstract class constructor arguments

By this approach you can create your own child attribute and use any other type of data generator if you don’t like the AutoFixture one.
When we’ve done with the attributes, it’s time to generate some code!
Generating source files
The general flow I recommend is to search for all information that you need to generate your new code and then actually do it. It’s much cleaner to read and understand what’s going on. Secondly, it’s a bit more performant because if you extract the information at the beginning, you’ll not reference the compilator objects every single time you need to check some property.
Gathering information
I recommend installing the SyntaxViewer from Microsoft. It’s a tool that gives you the possibility to see how the actual code is translated into the syntax tree. Thanks to it, it is much easier to write searching logic for your generator. Here you can find how to use it.
Generating
There are two common approaches for generating:
Using Microsoft.CodeAnalysis.CSharp.SyntaxFactory
- Pros:
- Prevents from doing some bad syntax mistakes from the beginning, like putting brackets in the wrong spots.
- Functional way of generating code is more natural.
- Cons:
- The picture does not show the whole, well, picture. There is a bit more to be done to actually generate the code from it.
- A lot of methods needs to be used to generate even some simple scenarios
- It still does not prevent typos or semantic errors.
- You can’t immediately see what the code will look like, without checking the results of the generation.
Simple string building
- Pros:
- Straightforward, you just write the string of whatever you would like to generate.
- You can write the result code, compile it, and just paste it as a string to your generator.
- You can use the expendability pattern from the first paragraph.
- Better “visibility”: it’s quicker to see what code will be generated.
- Cons:
- If the formatting of the result code is important, then you must take care of it by doing whitespaces by yourself.
- It’s easy to write some tokens in the wrong place by accident.
- It’s easy to make some silly mistakes.
In summary: If you really hate magic strings the SyntaxFactory approach will be the best for you. However, I recommend using the simple string builder approach anyway, because it’s, well, simple.
When a type is from a different project.
It’s a small warning about usage of the semantic analysis:
When the type used in the project you generate is from a different project, we can’t retrieve the localization information. Why bother? Without it you can’t check whether the exact place of the code is in the nullable references context or not. You can only check the whole project settings. It may lead to some compilation warnings. The workaround is to give an option to users, to force what kind of nullable context they would like to use in the generated code. It can be done by a custom enum type.

Testing
Testing is the most difficult part of this project, because how to test the compiler itself? There are some approaches and I will discuss the best ones.
Debugging
The most important tool of a programmer - debugging. When you create a separate project that is run by the .exe file it’s obvious, we run the debug mode in VS and we enjoy it. But here, source generators are libraries and are used only when dotnet does the compilation part, how do you approach it then? The best idea is just to put System.Diagnostics.Debugger.Launch() into the first line of your generator. Next, you hit the build, popup will appear to select a debugger, and voila! From now on, everything is as in the normal process of debugging any app.

Unit testing
Probably you won’t need it. Why? A number of lines of code of source generators is usually quite small. Secondly, you need to mock a lot of stuff related to the external interfaces from the compiler. Doing dependency injection is also a smelly idea to do here. If not the unit testing then what? Testing is important, isn't it?
Integration Testing
Yes, it is! That’s why I recommend approaching it with integration testing. Why? Because we are going to take advantage of the compiler itself. .NET community suggest (link) to use some special approaches with parsing your files or straight strings from your code, and they even call it as Unit tests. But I don’t like it. What is my approach then?
The idea is super straightforward:
- Create a new testing project
- Use your generator on many different scenarios, create classes that you’ll mark to be source generated.
- (optional) Write some “unit tests” of the generated code itself
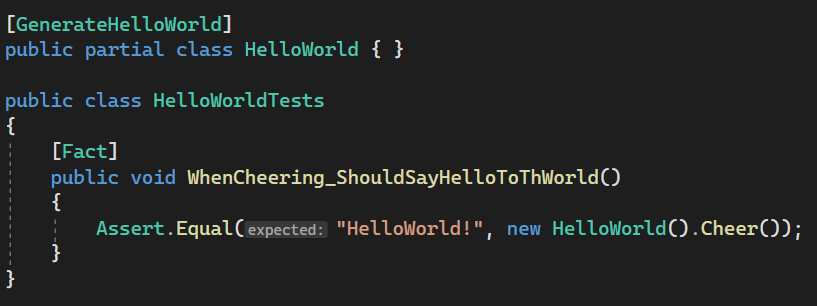
Voila! Easy-peasy, right?
You don’t need some magic tricks to mitigate the compiler. You just use it directly like a user of the source generator. You don’t even need to run any tests at all, because if the solution is built correctly, it means probably everything works correctly!
Performance testing
It’s optional, but I recommend writing some performance tests. Why? If you want your source generator to be usable, it shouldn’t slow down the compilation process. Imagine that because of your generator, compilation takes 30 minutes(!!). If your generator does the work in microseconds, you are safe to go.
How to write such tests is enough topic to cover a separate article, that’s why I’ll leave you with a link to an example of how you can quickly make your own performance tests.
Source generated!
I believe that with my tips & tricks you’ll be able to write great generators. I encourage you to dive into it, as it expands your knowledge about how the .Net compilation works, and it’s just a lot of fun. Don’t forget to let me know in the comments about your best practices and ideas for source generators. Happy automating!