Rozpoznawanie twarzy w Pythonie

Jakiś czas temu napisałem artykuł o tym, w jaki sposób udało mi się wykonać rozpoznawanie twarzy przy pomocy zdjęcia profilowego z LinkedIn. Próbowałem to również podręcznikowo wyjaśnić mojemu współpracownikowi, po czym zdałem sobie sprawę, że nie jest to zbyt skuteczne. Podczas pracy z technologią wizualną, zobaczenie na własne oczy, jak coś działa, jest najlepsze.
Przygotowałem więc Jupyter Notebook, pokazujący wizualnie cały proces krok po kroku. Można go znaleźć na moim GitHubie.
Zachęcam do klonowania repozytorium i próbowania tego na własną rękę. Jedyną bolączką jest jednak to, że testowałem go tylko na Macu. Jupyter Notebook używa kamery wideo do wyświetlania obrazu HOG, a twarz wykrywana jest w czasie rzeczywistym, wraz z punktami orientacyjnymi.
Krok 1 - znajdź twarz na obrazku
Stwórz histogram zorientowanych gradientów (HOG)
Gdy patrzymy na piksel, widzimy go wraz z każdym innym pikselem, który go otacza. „Rysujemy strzałkę” do najciemniejszego sąsiedniego piksela. Powodem patrzenia na gradienty zamiast na intensywność pikseli jest to, że gradienty zwykle nie zmieniają się wraz ze zmianami jasności i ciemności obrazu. Jasny obraz danej osoby będzie miał w przybliżeniu te same gradienty, co ciemniejszy tej samej osoby.
Radzenie sobie z danymi na poziomie pikseli może być przytłaczające, więc algorytm bierze zazwyczaj pod uwagę segmenty 16x16 i tworzy wynikową „strzałkę” gradientu większości głosów z zawartych gradientów. Dzięki segmentowi 16x16 możesz zobaczyć kontur obrazu poniżej.
 Oryginalne zdjęcie vs. obraz z obliczonym HOG
Oryginalne zdjęcie vs. obraz z obliczonym HOG
Jeśli uruchamiasz kod z mojego repozytorium, wykonaj następujące czynności:
python video_hog.py
Naciśnij q, aby wyjść z aplikacji. Można to zrobić we wszystkich aplikacjach w tym poście.
Użyj HOG, aby znaleźć twarze
Biblioteki face_recognition i dlib zapewniają interfejs do wstępnie wyszkolonych modeli oraz które przyjmują HOG w celu odnalezienia twarzy na obrazie.

Możesz to zobaczyć, uruchamiając następujące polecenie w repozytorium GitHub.
python video_hog_face_detect.pyKrok 2 - Znajdź 68 punktów orientacyjnych na twarzy
Dlib jest wyposażony w przeszkolony wykrywacz punktów orientacyjnych twarzy, który wykrywa 68 różnych punktów.

dlib - wykrywacz punktów orientacyjnych twarzy
Zostaną one następnie wykorzystane jako dane wejściowe do CNN w celu wygenerowania 128 wartości reprezentujących twarz.
Oto, jak to wygląda.
 68 punktów orientacyjnych na twarzy
68 punktów orientacyjnych na twarzy
Możesz to uruchomić samodzielnie z repozytorium, przy użyciu poniższej komendy:
python face_landmarks.pyKrok 3 - utwórz 128 wartościowe kodowanie dla orientacyjnych na twarzy
Generowanie 128 wartości kodowania odbywa się za pomocą CNN. Model ten został już przeszkolony na wielu obrazach szkoleniowych i dzięki temu niezawodnie koduje twarze, których wcześniej nie widział. Zdjęcia tej samej osoby powinno dawać mniej więcej ten sam wektor.
Proces wygląda trochę tak jak poniżej (disclaimer - nie jestem pewien, jak dokładnie wyglądała architektura CNN, więc jest to tylko luźna interpretacja):
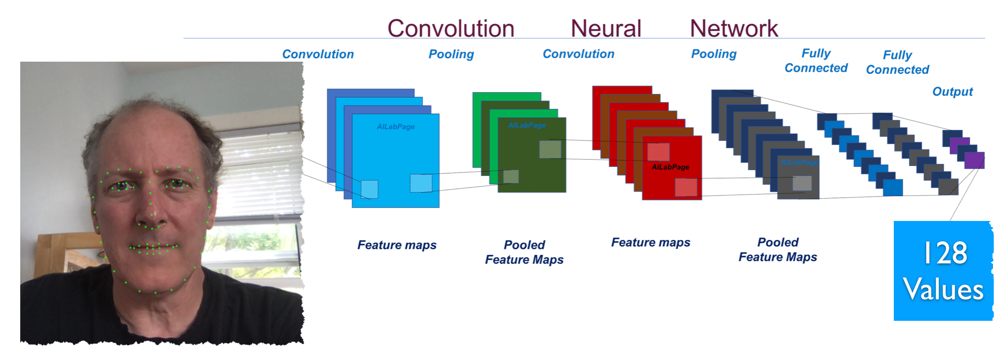 68 punktów na wejściu - wektor 128 zakdowanych wartości na wyjściu
68 punktów na wejściu - wektor 128 zakdowanych wartości na wyjściu
Biblioteka facial_recoginition zapewnia bardzo prosty interfejs do pobierania kodowań i kolekcji prostokątów reprezentujących twarze na obrazie.
Poniżej znajduje się obraz wartości mojej twarzy. Oto indeksy: 0, 32, 64, 96, 127.
 Obraz twarzy z zakodowanymi wartościami
Obraz twarzy z zakodowanymi wartościami
Możesz to uruchomić samodzielnie w następujący sposób:
python encodings_display.py
Po uzyskaniu zakodowanego wektora i imienia osoby jako etykiety, do której należy twarz, określenie, do kogo należy twarz, staje się dosyć proste. Wystarczy obliczyć odległość nowego obrazu twarzy od tych zakodowanych i wybrania tej z najniższą wartością odległości.
W tym artykule i prezentacji w notebooku używam zestawu danych z PyImageSearch.com.
Powyższa strona zawiera zestaw danych postaci z Parku Jurajskiego. Korzystając z nich, stworzyłem kolekcję kodowania każdej postaci wraz z sobą. Zestaw ten wykorzystano do ustalenia, czy biblioteka rozpoznawania twarzy może ustalić kto jest na nowym zdjęciu.
 Próbka zestawu danych Jurassic Park z PyImageSearch
Próbka zestawu danych Jurassic Park z PyImageSearch
 Mój przykładowy zestaw
Mój przykładowy zestaw
Aby zakodować wszystkie zdjęcia, utwórz katalog zawierający foldery dla każdej osoby i wykonaj następujące czynności:
python create_facial_encodings.py -d images/dataset -e
encodings/facial_encodings.pkl -r true
-d to główny katalog zawierający wszystkie inne katalogi dla każdej osoby. -e jest miejscem, w którym ma zostać wyprowadzony plik kodowania, a -r służy do wskazania, czy najpierw nie należy usunąć istniejącego pliku kodowania. Jeśli nie użyjesz opcji -r, skrypt dopisze wynik do istniejącego pliku kodowania.
Krok 4 - Oblicz odległość nowego obrazu względem kodowania
Biorąc pod uwagę 128-wartościowe kodowanie nowego obrazu, obliczamy odległość euklidesową i wybieramy najkrótszą. Domyślnie biblioteka facial_recognition używa progu 0,6. Odkryłem jednak, że wartość 0,5 lub 0,55 działa lepiej.
Użyłem tego zdjęcia z mojego LinkedIna:
Stwórzmy kodowanie obrazu z LinkedIn i porównajmy go z kodowaniem innych obrazów.
python calculate_encoding_distance.py -i
images/pat_ryan_linkedin/pat.ryan.smaller.png -e
encodings/facial_encodings.pkl
Powyższy skrypt pobiera obraz do porównania wraz z plikiem kodowania i tworzy uporządkowaną listę odległości. Poniżej znajduje się skrócona lista z powyższego skryptu.
(0.32661354282556054, 'pat_ryan')
(0.3396320380221242, 'pat_ryan')
(0.37282213715155005, 'pat_ryan')
(0.3873396941553151, 'pat_ryan')
(0.3931766472928196, 'pat_ryan')
(0.5899434975941679, 'john_hammond')
(0.5915515133378403, 'pat_ryan')
(0.5931512383511677, 'pat_ryan')
(0.6181329489347294, 'john_hammond')
(0.6220354071101851, 'pat_ryan')
(0.6288404317148943, 'claire_dearing')
(0.6289871731418288, 'pat_ryan')
(0.6362522359834057, 'ellie_sattler')
(0.6385852659752145, 'ian_malcolm')
(0.6402352852332767, 'pat_ryan')
(0.64030341755603, 'ian_malcolm')
(0.6481591277972383, 'john_hammond')
(0.6492390421627161, 'pat_ryan')
(0.6536934378322224, 'pat_ryan')
(0.6558663581518828, 'john_hammond')
(0.6581323325011266, 'ian_malcolm')
(0.6581323325011266, 'ian_malcolm')
(0.9935973296143709, 'claire_dearing')
Z powyższej listy widać, że nawet przy domyślnym progu 0,6 większość otrzymanych wyników to była moja twarz. Większość, bo John Hammond się tam wkradł. Ale próg 0,5 pasowałby tylko do mojego kodowania.
Przekonaj się sam
Możesz spróbować tego samemu. W Jupyter Notebook znajduje się sekcja o nazwie Photo Booth. Możesz użyć kamery internetowej, aby zebrać niektóre zdjęcia, zakodować je i uruchomić rozpoznawanie twarzy.
Aby przechwycić nowe obrazy, zbierz 10 zdjęć przy użyciu poniższej komendy:
python capture_webcam_face_images.py -d images/dataset -n
ernest_t_bass -c 10
Następnie utwórz nowy zestaw kodowań zawierający Twoje zdjęcia:
python create_facial_encodings.py -d images/dataset/ernest_t_bass -e
encodings/facial_encodings.pkl
Zwróć uwagę, że w tym przypadku opcja -d zawiera nazwę katalogu Twoich zdjęć, a nie zbioru danych. Chodzi tylko o dodanie Twoich zdjęć do kolekcji. Zauważ też, że skrypty nie używają opcji -r, ponieważ nie chcemy usuwać istniejących kodowań, tylko coś do nich dodać.
Po otrzymaniu kodowania uruchom skrypt wideo, aby sprawdzić, czy kamera Cię rozpoznaje.
python video_facial_recognition.py -e encodings/facial_encodings.pkl
--distance-tolerance 0.5Na koniec
Mam nadzieję, że daje to bardziej wizualny i praktyczny wgląd w działanie rozpoznawania twarzy.
Źródła
Ten wpis jest podsumowaniem tego, co udało mi się dowiedzieć o rozpoznawaniu twarzy. Skorzystałem z kilku źródeł, które, moim zdaniem, są nieocenione w tej dziedzinie.
PyImageSearch.com
Powyższa strona ma niesamowite artykuły i równie niesamowite książki. Jego materiał jest jasno napisany i dokładny.
MachineLearningIsFun.com
Adam jest twórcą i opiekunem biblioteki facial_recognition, która jest fantastycznym wrapperem dla biblioteki dlib. Sprawia ona, że zadanie jest bardzo proste i dostępne dla osób bez większego doświadczenia w uczeniu maszynowym. Jego artykuły obejmują więcej niż tylko wizję komputerową, a jego książka również jest świetną lekturą.
To oficjalne tłumaczenie z języka angielskiego, a oryginał tekstu przeczytasz tutaj.