Rails monolith modularisation with CQRS

Ruby on Rails and its supporting gems built by the community form a fantastic environment for bringing ideas to life. It provides developers with a market advantage by allowing them to build new products at an extremely high pace. However, over time, with application and team growth, the velocity decreases.
It’s caused by Rails apps' centralized structure. Adding new features to the application directly increases the complexity of the overall development, thus slowing everything down. The solution for this problem is modularization: dividing a big application into smaller units.
This article describes the methodology of breaking down Rails applications into smaller, more manageable modules supported by the CQRS (Command and Query Responsibility Segregation) pattern.
Centralized app structure - great for small apps
Applications built with Rails are very similar in terms of their physical directory structure. You can expect to see models in app/models and custom rake tasks in lib/tasks, DB schema in db/schema.rb, etc.

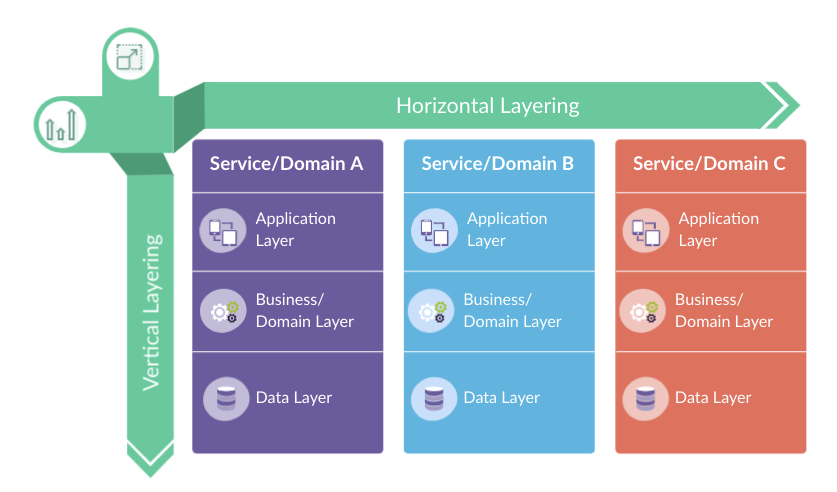
This common feature has undeniable value. New developers are able to quickly enter existing projects and make changes from day one.
Creating new features in a Rails app usually involves adding new files in multiple app/directories, each representing a vertical layer (MVC layers, background jobs, etc.). Rails framework alone was not built with modularization as a priority. There are no horizontal layers (by-feature) separation so eventually, all the features blend together.
With this method, gaining an overview by layer is straightforward. If you want to see all models just look at app/models. However, when you want to see an overview of features or modules, it’s not quite as straightforward.

This centralized approach works great for small apps, and that’s where Rails really shines.
However, when the app grows, this simple, slightly native attitude becomes unmanageable, especially in the model and business logic context.
Community solutions
Over time, the Rails community has developed some common patterns to make bigger applications more manageable.
The current consensus is to keep the models slim and move the logic to Service Objects; they absorb all the old-fashioned models’ fat. Services often use PORO (Plain Old Ruby Objects), non-Rails libraries like dry-rb, and are in general less coupled with the framework.
Service objects and models can be moved into namespaces too. For example, everything connected with account settings could be moved to Accounts module.
In Rails, it’s also possible to move models into namespaces. It’s a common pattern to see both services and models to be within the same namespace.
So it looks good on paper, but there’s just one big problem. All Active Record classes form an interconnected mesh, where all the models from the whole system are connected together.
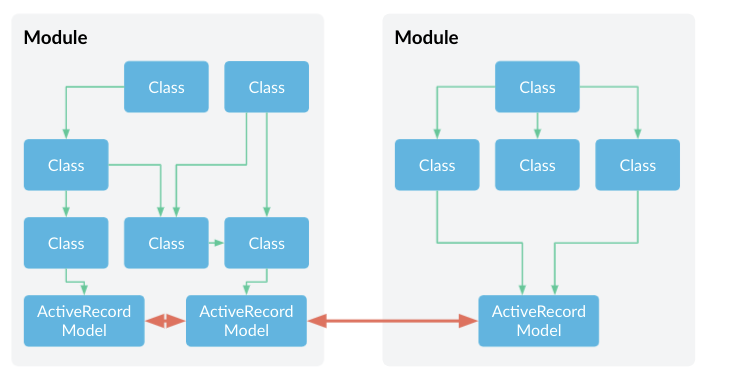
ActiveRecord accidental coupling
When a method receives an object with a limited public interface, then the programmer’s power also becomes limited. This limited power, however, is actually the strength of our system. Encapsulation gives us the secure freedom to change the internals as long as the public interface is not changed.
Active Record interface is the opposite of that. When a method receives an ActiveRecord object, it literally means that it has access to the whole database. Active Record provides no barrier between modules since everything has to be connected.
Subsystems isolation
There’s a reason why ActiveRecord classes from separate modules are connected; no module lives in isolation.

(Image source: https://www.newkidscar.com/)
Subsystems and modules are not new concepts in engineering. For instance, when you press a brake pedal in a car, multiple subsystems react to it.
- Pressure is applied in the hydraulic brakes system.
- The electric system reacts and turns on the rear brake light.
- During an emergency braking, it might also
- enable emergency lights (and both turn signals)
- stiffen active suspension
While these subsystems are connected, they maintain some isolation. The braking light bulb might be burned out, but it won’t cause your brakes to completely stop working.
Isolation allows engineers of each subsystem to work independently. They establish a common interface to communicate, ensuring that once those isolated systems eventually connect, everything will work as expected.
Imagine a car built the way we built our Rails systems, where everything was potentially dependent on each other. All engineers would always need a complete car to work because everything was interconnected. And with limitations or lack of protocols, a sloppy engineer might take some shortcuts to get the work done.
That would be a complete mess.
Extract internal module
External services analogy
When connecting Rails applications to external services using a public API that manages some entities, it’s common practice to save the references to those entities in our local database.
For example, when using a file storage service to upload and host files, we only store an external object identifier. That reference, the identifier, is enough to carry out any operations on the entity using the API.
In the practical example below, we only store external object identifiers in the database’s stored_file_id column.
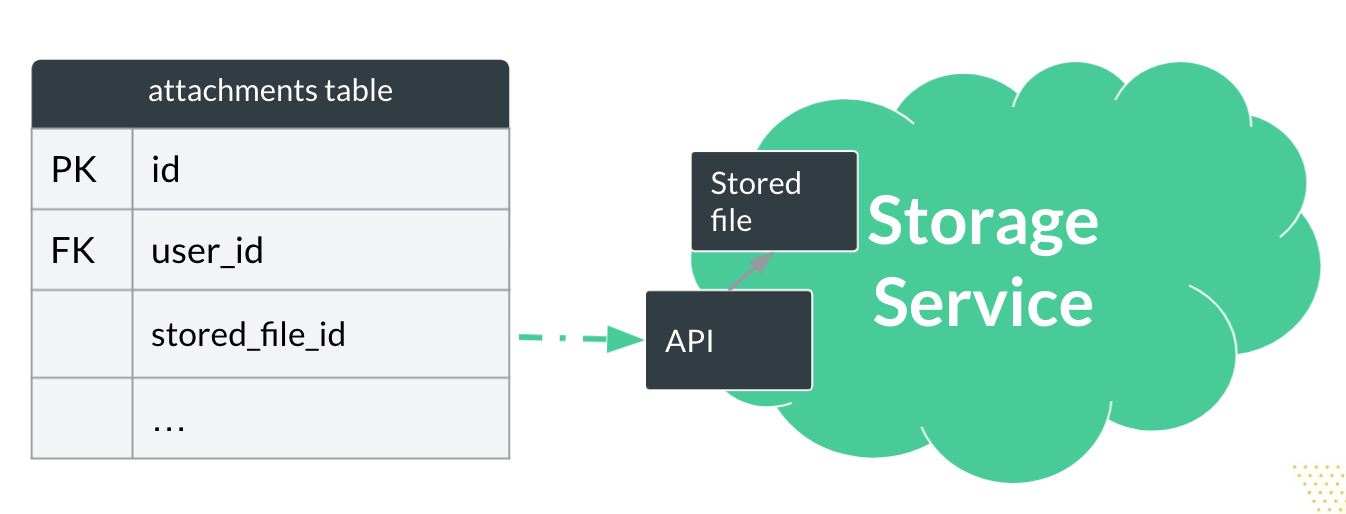
What if the Storage Service was something we built inside Rails, inside the monolith? The standard, Rails-way implementation could look something like this:
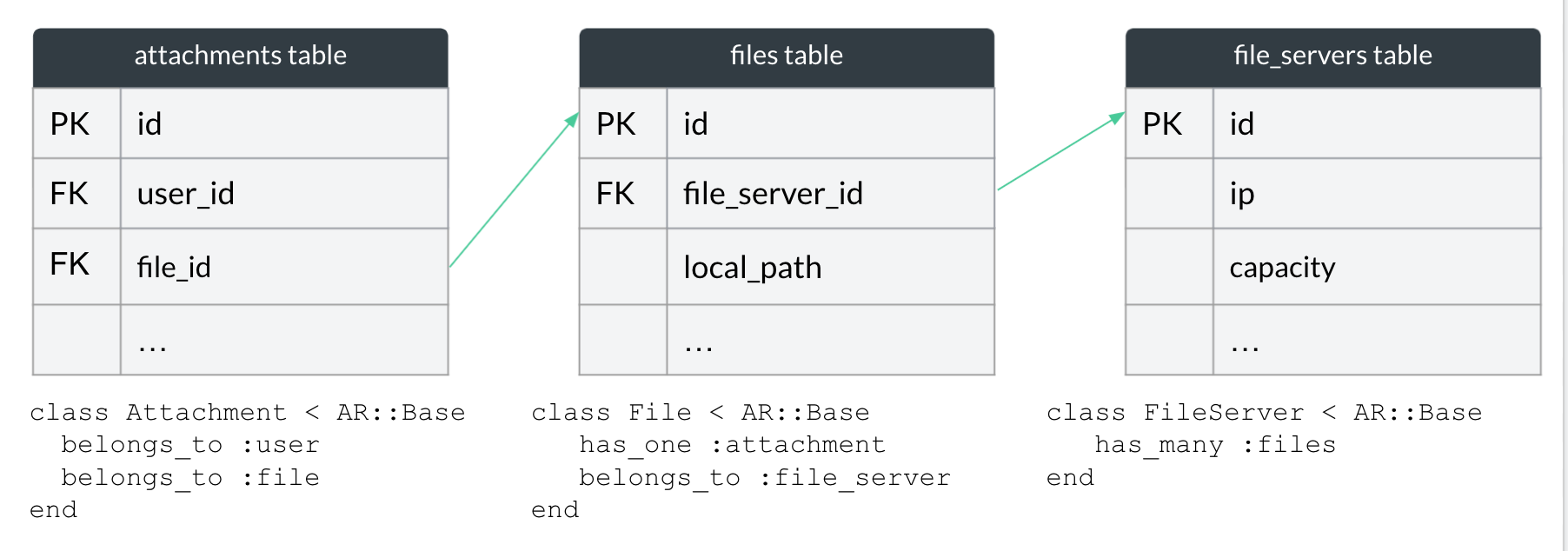
We would have to add files table (and probably a few more internal tables, file_servers is just an example) and replace the remote stored_file_id from the previous scenario withfile_id, which points to a local table.
Now the biggest difference between the two implementations is coupling.
In the remote solution, service implementation is encapsulated and independent from the application; it’s implemented in total separation. Our application presence or lack of presence doesn’t change much.
However, in the local solution, the storage feature is heavily coupled with the application. Both the new storage feature and the application are dependent on each other.
That begs the question: Does it really have to be this way in the local solution? How can we disconnect them?
Decoupling with internal API
The simplest solution is to encapsulate the Storage module behind a local API. Unlike remote HTTP API, the local API is just an object with a known interface.
Because it’s a local call, the API theoretically could return the ActiveRecord object. It’s important though to NOT leak an ActiveRecord object through the API.
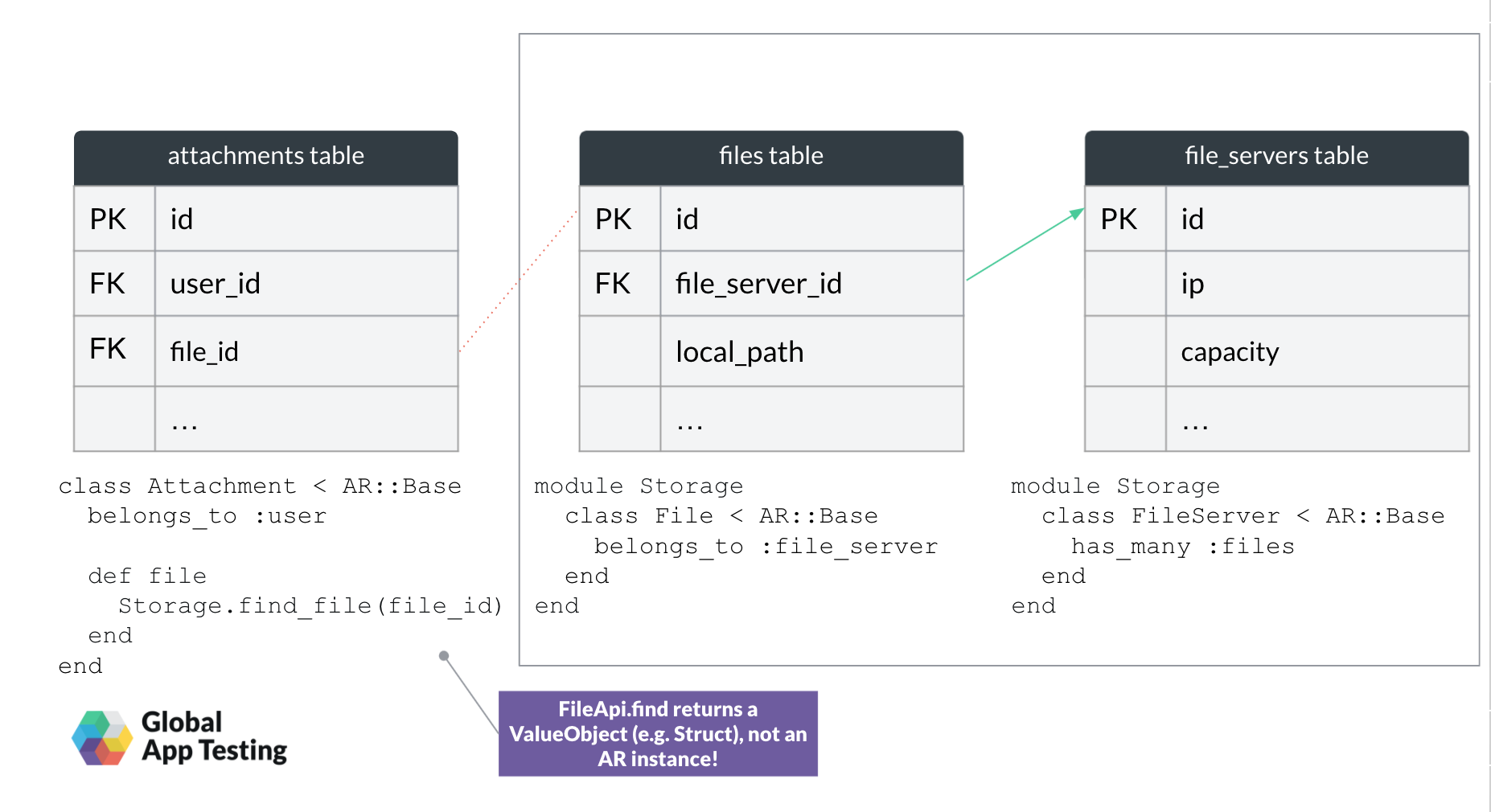
In practice, Storage API could look like this:
module Storage
def self.find_file(file_id)
# Inside Storage I have access to Storage::File AR class
file_record = File::Storage.find(file_id)
FileValueObject.from_record(file_record).freeze
end
FileValueObject = Struct.new(:url, :file_type) do
def self.from_record(file_record)
new(
file_record.file_server.root + file_record.path,
file_record.file_type
)
end
end
endfind_file as a part of the Storage module had access to its internal Active Record class. The method fetches the record from the database and then converts it into a value object that is just the representation for the rest of the system, outside the Storage module.
For the purpose of the article, it uses Struct, a very simple Ruby built-in. In practice, you might want to use more sophisticated solutions. We use and recommend dry-struct.
What we achieved so far
By applying this approach, the system becomes more modularized.
We’re now able to work on the isolated modules independently, only needing to ensure that the public API is not changed. And if we do need to change it, we must do only non-breaking changes (like adding a new field), support multiple API versions, or migrate the breaking changes in the code that calls the API.
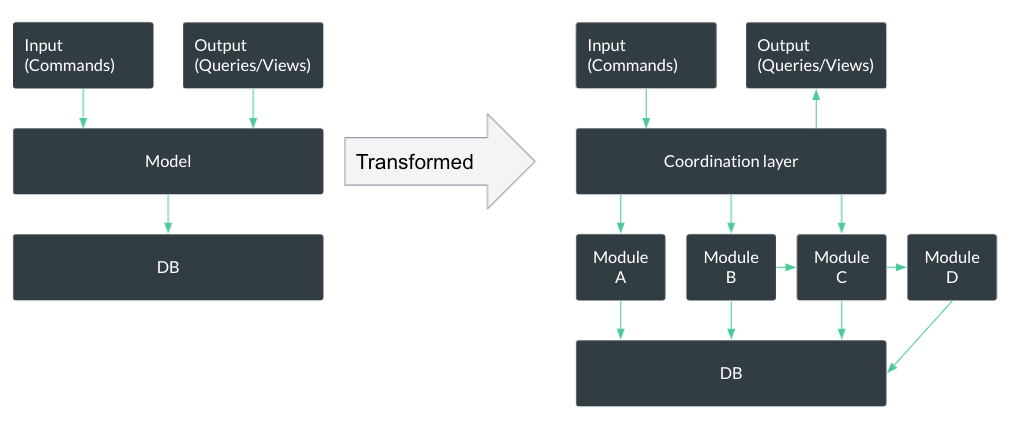
While the process changed the logical structure of the application and encapsulated Active Record classes, the structure of the database has not changed at all. That’s important, as DB migrations, often irreversible, are much riskier.
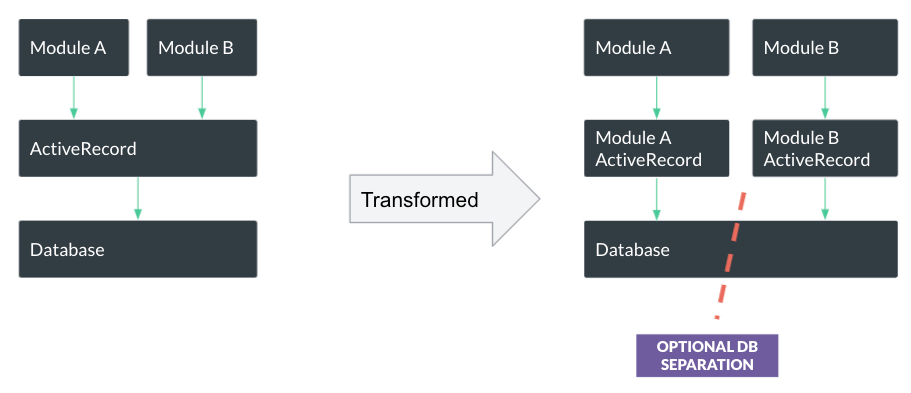
But is it really better now?
Well… sort of.

Modularized code is much easier to maintain and work with. But what are the cons? At this stage, there are plenty compared to a Rails-way approach.
While the database structure hasn’t changed, it’s no longer possible to create inter-modules queries using Active Record’s Arel. We can still write them by hand, but it’s much more painful.
A lot of essential features built on top of Active Record that popular gems provide, such as pagination, advanced querying (e.g. ransack gem) are much more complicated now.
Also avoiding N+1 queries with includes or joins is not that obvious anymore.
And even more so, the experience of using the Rails console is massively degraded. You no longer can quickly traverse through the database using Active Record, as the relations between modules are no longer explicit.
All the problems listed in this section share one common feature: They are all related to the query side of the system.
Commands and queries - two different worlds
In web apps, including Rails, commands (HTTP POSTs that might change the system state) and queries (HTTP GETs, idempotent requests that don’t change the system state) are treated differently.
Commands usually have a limited scope of changes. A single command usually interacts with and changes from one up to a few entities.
Queries are completely different. It’s not an edge case that to render a single page (e.g. an order summary or status page in an e-commerce system) it’s necessary to fetch data from multiple modules.
As a result, while the command side can and should be divided, the query side cannot be easily modularized.
When using GraphQL, where all the queryable types are connected together, it’s even more vivid.
There’s nothing wrong with having a non-modularized query side model.
CQRS to the rescue
CQRS (Command and Query Responsibility Segregation) pattern describes using different models for commands (actions that might change the system state) and queries (reading data that does not change the state).
If you are not familiar with this, I highly recommend a write-up from Martin Fowler.
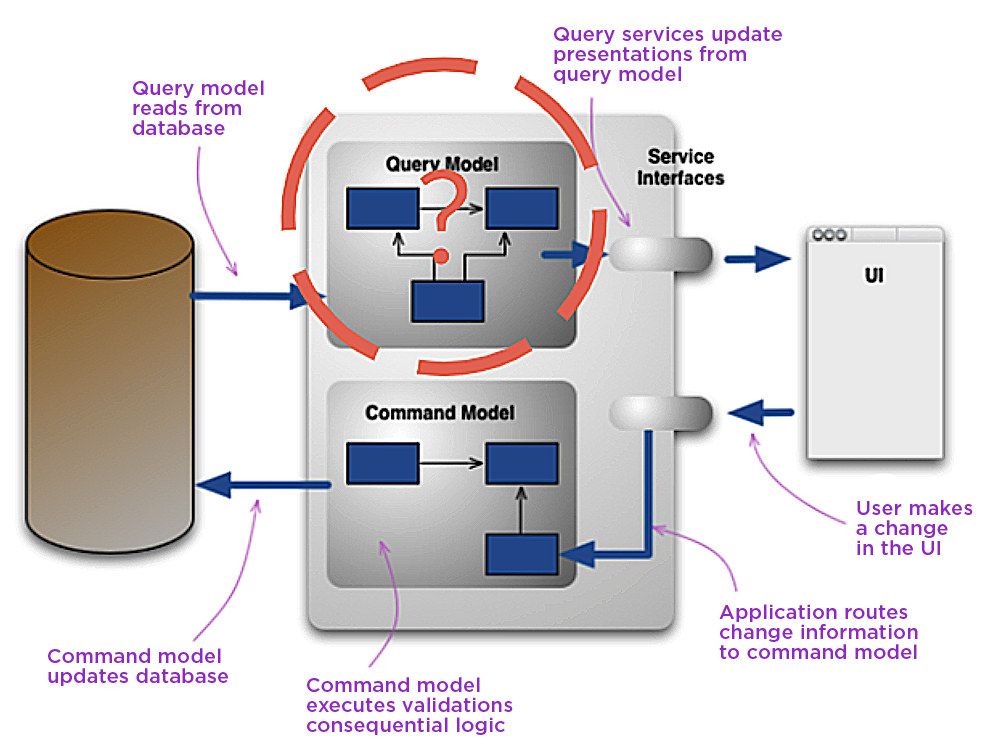
In the search for the query model
Was there anything wrong with the query side the way it was implemented in the good ol’ Rails way, where all the Active Records are connected together?
We came to a conclusion. No!
So how could this be implemented in practice? There’s no limitation in Active Record preventing us from creating multiple, different Active Record classes for the same database table.
Let’s take a look again at the ActiveRecord code for the Storage example.
So far we have a command side:
class Attachment < AR::Base
belongs_to :user
def file
Storage.find(file_id)
end
end
module Storage
class File < AR::Base
belongs_to :file_server
end
end
On the query side, Attachment is connected with File indirectly. We can’t call Attachment.joins(:files).
However on the query side, we want that capability. The implementation of the Query module with connected Active Record classes is as follows:
module Query
class Base
def readonly?
true
end
end
end
module Query
class Attachment < Base
belongs_to :user
belongs_to :file
end
end
module Query
class File < Base
has_one :file
belongs_to :file_server
end
end
On the query side, all the models are interconnected. Additionally, we’re marking models as read-only to ensure that we don’t accidentally perform a write on these models.
Do I really need modularization?
It depends. Engineering is a balancing act. If you have a compact team (or no team at all) or a small codebase, this is probably overkill.
What’s important is that this methodology doesn’t have to be applied everywhere in the codebase. Modularization always adds some additional cost and overhead.
Boring, non-essential CRUD parts of the system optimally don’t have to be changed and can remain as they are.
Summary
With the CQRS approach, we were able to modularize the most critical and error-prone part of the application, while also keeping the flexibility and all capabilities provided by Rails on the query side.
Because the logical changes in the code don’t require any data migrations, the change is an evolution, not a revolution. This approach gave us the ability to slowly and safely extract isolated modules from the application without a headache.
This article was originally published in the GAT Engineering Blog.