Prosty sposób na zmniejszenie złożoności systemów informatycznych

Jeśli chodzi o systemy informatyczne, sprawy mogą być nieco bardziej skomplikowane. Typowy system informatyczny, jakim jest serwis internetowy, na najbardziej podstawowym poziomie jest tylko jednym procesem w ogromnym, zintegrowanym potoku danych.
Zajmuje się głównie przetwarzaniem danych: pobieraniem danych, przekształcaniem ich i przekazywaniem do innego systemu. Jednak, w miarę jak inne systemy piętrzą się na szczycie tego procesu, złożoność szybko rośnie. Zarządzanie i łagodzenie tej złożoności staje się wtedy poważnym wyzwaniem dla zespołów programistów.
Tradycyjnie systemy informatyczne
Dotychczas były implementowane przy użyciu paradygmatów programowania, takich jak programowanie obiektowe, opartych na zagadnieniu „obiektów”, które mogą zawierać dane i kod. Systemy informatyczne, które opierają się na programowaniu obiektowym, mają tendencję do bycia złożonymi, w tym sensie, że są trudne do zrozumienia i trudne do utrzymania.
Wzrost złożoności systemu ma tendencję do zmniejszania szybkości działania zespołu programistów, ponieważ dodawanie nowych funkcji do systemu zajmuje więcej czasu. Trudne do zdiagnozowania problemy pojawiają się wtedy częściej w produkcji. Problemy, które powodują frustrację użytkownika, gdy system nie zachowuje się zgodnie z oczekiwaniami, albo co gorsza, przestój systemu.
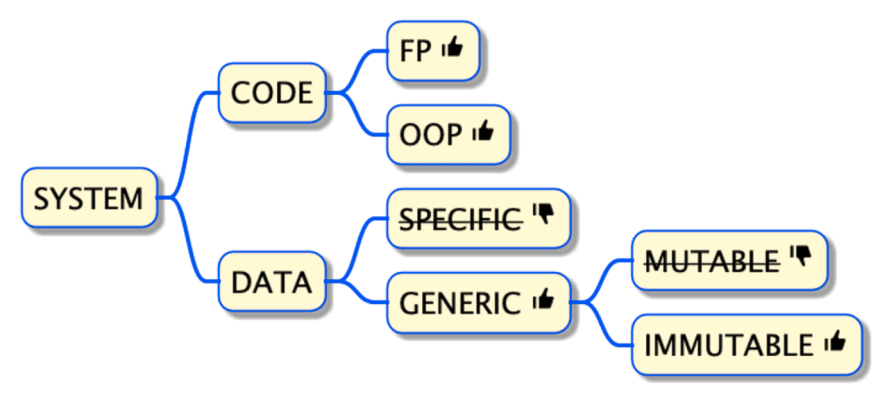
3 aspekty programowania obiektowego są źródłem złożoności:
- Enkapsulacja danych w obiektach
- Nieelastyczny układ danych w klasach
- Mutacja stanu
Enkapsulacja
Enkapsulacja danych wewnątrz obiektów jest w wielu przypadkach korzystna, jednak w kontekście współczesnych systemów informatycznych enkapsulacja danych ma tendencję do tworzenia złożonych hierarchii klas, w których obiekty wchodzą w wiele relacji z innymi obiektami.
Z biegiem lat złożoność ta została złagodzona dzięki wynalezieniu zaawansowanych wzorców projektowych i frameworków programistycznych. Jednak systemy informatyczne zbudowane z wykorzystaniem programowania obiektowego nadal mają tendencję do bycia zbyt skomplikowanymi.
Nieelastyczny układ danych w klasach
Reprezentowanie każdego kawałka danych poprzez klasę jest pomocne dla narzędzi (np. autouzupełnianie w edytorze), a błędy takie jak dostęp do nieistniejących pól są wykrywane w czasie kompilacji. Jednak sztywność układu klas sprawia, że dostęp do danych nie jest elastyczny.
W kontekście systemów informatycznych jest to dość problematyczne: każda wariacja danych jest reprezentowana przez inną klasę. Na przykład w systemie, który zajmuje się klientami, istnieje klasa, która reprezentuje klienta widzianego przez bazę danych i inna klasa, która reprezentuje klienta widzianego przez logikę manipulacji danymi. Podobne dane z różnymi nazwami pól, ale nie da się uniknąć mnożenia klas. Powodem jest to, że dane są „zamknięte” w klasach.
Mutacja stanu
W wielowątkowych systemach informatycznych fakt, że stan obiektu może być mutowany, jest kolejnym źródłem złożoności. Wprowadzenie różnych mechanizmów blokad w celu uniemożliwienia współbieżnej modyfikacji danych i zapewnienia aktualności stanu naszych obiektów powoduje, że kod jest trudniejszy do napisania i utrzymania.
Czasami, przed przekazaniem danych do metody w postaci bibliotek stron trzecich, używamy strategii tworzenia kopii zapasowych, aby upewnić się, że nasze dane nie zostaną zmodyfikowane. Dodanie mechanizmów blokad lub strategii tworzenia kopii zapasowych sprawia, że nasz kod staje się bardziej złożony i mniej wydajny.
Programowanie zorientowane na dane
To zbiór najlepszych praktyk, które zostały zastosowane przez programistów w celu zmniejszenia złożoności systemów informatycznych. Ideą takiego programowania jest uproszczenie projektowania i wdrażania systemów informatycznych poprzez traktowanie danych jako „obywatela pierwszej klasy”.
Zamiast projektować systemy informatyczne wokół obiektów łączących dane i kod, programowanie zorientowane na dane prowadzi nas do oddzielenia kodu od danych i reprezentowania danych za pomocą niezmiennych, generycznych struktur danych. W konsekwencji programiści manipulują danymi z taką samą elastycznością i spokojem, z jaką manipulują liczbami czy ciągami znaków w jakimkolwiek programie. Programowanie zorientowane na dane zmniejsza złożoność systemu.
Zasady zmniejszenia złożoności systemu:
- Oddzielenie kodu od danych
- Reprezentowanie danych za pomocą generycznych struktur danych
- Zachowanie niezmienności danych
Jednym z możliwych sposobów podążania za tym rodzajem programowania jest pisanie kodu w metodach klas statycznych, które otrzymują dane, którymi manipulują, jako argument eksplicytny.
Oddzielenie problemów, uzyskane przez oddzielenie kodu od danych, powoduje, że hierarchia klas staje się mniej złożona: zamiast projektować system z diagramem klas składającym się z encji powiązanych wieloma relacjami, system składa się z dwóch rozłącznych, prostszych podsystemów: podsystemu kodu i podsystemu danych.
Kiedy reprezentujemy dane za pomocą generycznych struktur danych (takich jak hashe i listy), dostęp do danych jest elastyczny i dąży do zmniejszania liczby klas w naszym systemie.
Zachowanie niezmienności danych pozwala programiście na spokojne pisanie kodu w środowisku wielowątkowym. Ważność danych jest zapewniona bez konieczności zabezpieczania kodu mechanizmami blokad lub kopii zapasowej.
Zasady programowania zorientowanego na dane mają zastosowanie zarówno do języków programowania obiektowego, jak i funkcjonalnego. Jednak dla programistów działających w programowaniu obiektowym przejście na to zorientowane na dane może wiązać się z większą zmianą sposobu myślenia niż dla programistów działających w programowaniu funkcyjnym, ponieważ programowanie zorientowane na dane prowadzi do pozbycia się nawyku hermetyzowania danych w klasach stanowych.
Oryginał tekstu w języku angielskim przeczytasz tutaj.