Problemy algorytmiczne: w poszukiwaniu duplikatu w tablicy

Z mojego doświadczenia wynika, że większość źródeł odnoszących się do rozwiązywania problemów z algorytmami, przedstawia jedynie same rozwiązania, a bardzo rzadko opisywany jest proces myślowy, który do nich doprowadził. Chcę zatem opisać, w jaki sposób podejść do rozwiązywania takich problemów i jak sobie z nimi radzić od zera.
Problem
Znajdź duplikat w tablicy. Biorąc pod uwagę tablicę n + 1 liczb całkowitych od 1 do n, znajdź jeden z duplikatów. Jeśli istnieje wiele możliwych odpowiedzi, zwróć jeden z duplikatów. Jeśli nie ma duplikatu, zwróć -1.
Przykład:
Input: [1, 2, 2, 3]
Output: 2
Input: [3, 4, 1, 4, 1]
Output: 4 lub 1
Proces rozwiązywania
Zanim przejdziemy do rozwiązania, porozmawiajmy o problemie. Mamy tablicę n + 1 z liczbami całkowitymi od 1 do n.
Tablica pięciu liczb całkowitych sugeruje, że każda z tych liczb będzie miała wartość od 1 do 4 (włącznie). Co najmniej jeden duplikat pojawi się wtedy automatycznie.
Wyjątkiem jest tablica o rozmiarze 1, gdzie powinniśmy zwrócić -1.
Metoda „na siłę”
Metoda „na siłę” polega na implementacji dwóch osadzonych w sobie pętli:
for i = 0; i < size(a); i++ {
for j = i+1; j < size(a); j++ {
if(a[i] == a[j]) return a[i]
}
}
Złożoność czasowa O(n²) i pamięciowa O(1).
Policzenie wystąpień
Innym rozwiązaniem jest policzenie iteracji każdej liczby całkowitej przez strukturę danych. To rozwiązanie można zaimplementować za pomocą tablicy lub tablicy mieszającej.
Implementacja w Javie:
public int repeatedNumber(final List<Integer> list) {
if(list.size() <= 1) {
return -1;
}
int[] count = new int[list.size() - 1];
for (int i = 0; i < list.size(); i++) {
int n = list.get(i) - 1;
count[n]++;
if (count[n] > 1) {
return list.get(i);
}
}
return -1;
}
Wartość indeksu i reprezentuje liczbę iteracji i + 1.
Rozwiązanie to nie złożoność czasowa O (n), a pamięciowa O (n), ponieważ potrzebujemy dodatkowej struktury.
Posortowana Tablica
Jeśli zastosujemy technikę uproszczenia, możemy spróbować znaleźć rozwiązanie przy pomocy posortowanej tablicy.
W takim przypadku musielibyśmy po prostu porównać każdy element z jego prawym sąsiadem.
W Javie wygląda to następująco:
public int repeatedNumber(final List<Integer> list) {
if (list.size() <= 1) {
return -1;
}
Collections.sort(list);
for (int i = 0; i < list.size() - 1; i++) {
if (list.get(i) == list.get(i + 1)) {
return list.get(i);
}
}
return -1;
}
O(1) w pamięciowej złożoności obliczeniowej, ale O(n log (n)) w złożoności czasowej, ponieważ musimy posortować kolekcję z góry.
Suma Elementów
Kierunek, w którym możemy pójść, to zsumowanie elementów tablicy i porównanie ich z 1 + 2 +… + n.
Zobaczmy to na przykładzie:
Input: [1, 4, 3, 3, 2, 5]
Sum = 18
As in this example, we have n = 5:
Sum of 1 to 5 = 1 + 2 + 3 + 4 + 5 = 15
=> 18 - 15 = 3 so 3 is the duplicate
W powyższym przykładzie jesteśmy w stanie znaleźć rozwiązanie w złożoności czasowej O(n) i pamięciowej O(1). Działa to jednak tylko w przypadku, gdy mamy tylko jeden duplikat.
Kontrprzykład:
Input: [1, 2, 3, 2, 3, 4]
Sum = 15
As in this example we have n = 5,
Sum of 1 to 5 = 1 + 2 + 3 + 4 + 5 = 15
/!\ Not working
To jednak nic nam nie daje. Warto jednak było spróbować, bo to przybliża nas do faktycznego rozwiązania.
Marker
Warto w tym miejscu wspomnieć o czymś interesującym. Do tej pory nasze rozwiązania tak naprawdę nie wykorzystywały faktu, że każda liczba całkowita ma wartość od 1 do n. Z powodu tego ograniczenia, każda wartość ma swój własny indeks w tablicy. Rozwiązaniem jest myślenie o tej konkretnej tablicy jako o liście. Każdy indeks wskazuje na wartość tego indeksu.
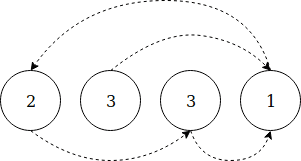
Przykład z [2, 3, 3, 1]
Powtarzamy iterację każdego elementu i zaznaczamy odpowiadający mu indeks, ustawiając jego znak na minus. Jeśli już to zrobiliśmy, oznacza to, że jego indeks jest duplikatem.
Zobaczmy krok po kroku, jak to działa:
Input: [2, 3, 3, 1]
* Index 0:
Absolute value = 2
Put a minus sign to a[2] => [2, 3, -3, 1]
* Index 1:
Absolute value = 3
Put a minus sign to a[3] => [2, 3, -3, -1]
* Index 2:
Absolute value = 3
As a[3] is already negative, it means 3 is a duplicate
Tak to wygląda w Javie:
public int repeatedNumber(final List<Integer> list) {
if (list.size() <= 1) {
return -1;
}
for (int i = 0; i < list.size(); i++) {
if (list.get(Math.abs(list.get(i))) > 0) {
list.set(Math.abs(list.get(i)), -1 * list.get(Math.abs(list.get(i))));
} else {
return Math.abs(list.get(i));
}
}
return 0;
}
Rozwiązaniem jest złożoność czasowa O(n) i pamięciowa O(1). Wymaga to jednak mutacji wejściowej tablicy.
Technika biegacza
Istnieje jeszcze jedno rozwiązanie, które również traktuje podaną tablicę jako listę (jest to możliwe z powodu ograniczenia, że każda liczba całkowita zawiera się między 1 a n).
Przeanalizujmy przykład [1, 2, 3, 4, 2]:
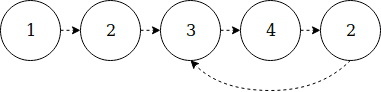
Przykład z [1, 2, 3, 4, 2]
Dzięki takiemu ukazaniu problemu można stwierdzić, że duplikat istnieje, gdy istnieje cykl. Ponadto duplikat jest punktem wejścia do cyklu (w tym przypadku drugim elementem).
Jeśli zainspirujemy się algorytmem Floyda do znajdowania cykli, możemy uzyskać następujący algorytm:
- Zainicjuj dwa wskaźniki:
slowifast - Dla każdego etapu, slow porusza się o jeden krok razem z
slow = a [slow], podczas gdy fast porusza się o dwa kroki wraz zfast = a [a [fast]] - Gdy
slow == fast, to jesteśmy w cyklu
Czy algorytm jest już ukończony? Jeszcze nie. Punktem wejścia do tego cyklu będzie duplikat. Musimy zresetować slow i przesuwać oba wskaźniki krok po kroku, aż znów będą równe.
Możliwa implementacja w Javie:
public int repeatedNumber(final List<Integer> list) {
if (list.size() <= 1)
return -1;
int slow = list.get(0);
int fast = list.get(list.get(0));
while (fast != slow) {
slow = list.get(slow);
fast = list.get(list.get(fast));
}
slow = 0;
while (fast != slow) {
slow = list.get(slow);
fast = list.get(fast);
}
return slow;
}
Rozwiązaniem jest czas O(n) i pamięć O(1) i nie wymaga ono mutowania listy inputów.
Dodatkowe źródła
- Projekt z GitHuba: teivah/algorithmic
- Solving Algo publications
Oryginał tekstu w języku angielskim przeczytasz tutaj.