Tworzenie modeli predykcyjnych vs. faktyczna praca Machine Learning Engineera

Uczenie maszynowe to fascynująca i szybko rozwijająca się dziedzina, która zmienia sposób, w jaki żyjemy, pracujemy i współdziałamy z technologią. Polega na wykorzystaniu algorytmów i modeli statystycznych do analizy dużych zbiorów danych, a następnie tworzenia predykcji lub podejmowania decyzji na podstawie tych danych. Każdego dnia korzystamy z rozwiązań bazujących w oparciu o algorytmy ML, robiąc zakupy online, używając programów do automatycznego tłumaczenia tekstu lub korzystając ze sklepów bezobsługowych.
Podczas gdy potencjał uczenia maszynowego jest niezaprzeczalny, zrozumienie jak ono działa i jak je zastosować w praktyce może stanowić wyzwanie. Osoby podejmujące to wyzwanie to działający na styku programowania, matematyki i statystyki inżynierowie uczenia maszynowego.
Inżynierowie uczenia maszynowego zajmują się projektowaniem, wdrażaniem i utrzymywaniem systemów uczących się na potrzeby różnych branż i dziedzin, takich jak przetwarzanie języka naturalnego, rozpoznawanie obrazów czy systemy rekomendacyjne. Są odpowiedzialni za dobór odpowiednich algorytmów uczenia maszynowego, a także za ich dostosowanie do konkretnych potrzeb biznesowych.
Jak w takim razie wygląda praca inżyniera uczenia maszynowego i czym się różni ona od tworzenia modeli predykcyjnych na Kaggle?
Odpowiedź na to pytanie można znaleźć omawiając kolejne etapy projektu, nad którym pracowali stażyści podczas ubiegłorocznej edycji wakacyjnego stażu IT. Mowa tutaj o wyszukiwarce obrazów podobnych, czyli "Visual search" (rys. poniżej). Studenci podczas trzymiesięcznego stażu, pod okiem doświadczonych specjalistów przygotowywali projekt, który potem mieli okazję rozwijać.
1. Definicja problemu
Pierwszym krokiem w każdym projekcie uczenia maszynowego jest jasne zdefiniowanie problemu biznesowego, który ma zostać rozwiązany. W odróżnieniu od hackatonów i konkursów Kaggle, które są zazwyczaj prezentowane jako samodzielne problemy, w prawdziwym świecie projekty uczenia maszynowego są zazwyczaj częścią większej inicjatywy biznesowej, z określonymi celami i ograniczeniami, które muszą być brane pod uwagę. Wymaga to głębokiego zrozumienia kontekstu biznesowego, jak i umiejętności skutecznej komunikacji ze specjalistami z różnych dziedzin.
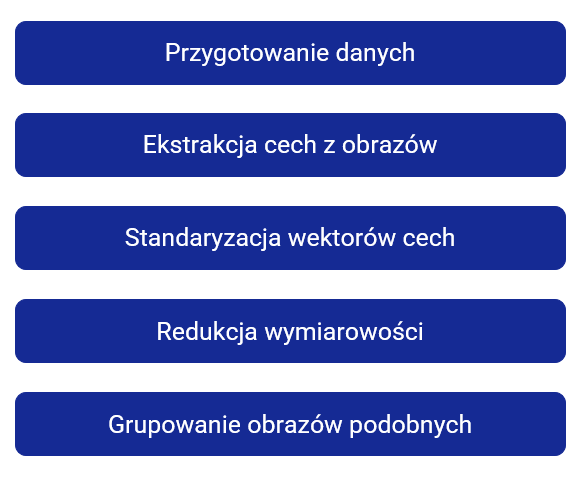 Definicja problemu i zaplanowanie działań na przykładzie projektu Visual Search Engine
Definicja problemu i zaplanowanie działań na przykładzie projektu Visual Search Engine
Współpraca i dobrze zdefiniowane cele to klucz do osiągnięcia wysokiej jakości rozwiązań w zakresie AI.
2. Zbieranie i wstępne przetwarzanie danych
Po zdefiniowaniu problemu kolejnym krokiem jest zebranie i wstępne przetworzenie danych, które będą użyte do trenowania modelu. Wymaga to pozyskania danych z różnych źródeł, ich preprocessingu oraz podziału danych na zbiory treningowe i testowe.
Na tym etapie można zauważyć znaczną różnicę między konkursami, a rzeczywistymi projektami. W konkursach i hackatonach dane są zazwyczaj czyste, dobrze zorganizowane, już wstępnie oznaczone oraz bez brakujących wartości i błędów. Natomiast w rzeczywistych projektach dane często są niekompletne, zaszumione i nieuporządkowane.
Inżynierowie uczenia maszynowego muszą poświęcić dużo czasu na oczyszczenie i przygotowanie danych przed ich użyciem do treningu modelu. Przydatne w tym procesie są biblioteki do wizualizacji, takie jak Matplotlib czy Seaborn, które pozwalają na lepsze zrozumienie danych i zależności pomiędzy nimi. Jeżeli jest taka możliwość, warto też skorzystać z pomocy specjalistów dziedziny, której dotyczy projekt. Wiedza ekspercka może pomóc w wyborze i tworzeniu odpowiednich cech oraz w identyfikacji i obsłudze brakujących danych, wartości odstających (outlineów) i innych anomalii.
Feature selection i preprocessing to jedne z najważniejszych i najbardziej czasochłonnych części projektu, mająca kluczowy wpływ na końcową skuteczność modelu.
3. Wybór modelu
Po wstępnym przetworzeniu danych należy wybrać odpowiedni model uczenia maszynowego.
Nie ma jednoznacznej reguły mówiącej jaki model najlepiej sprawdzi się na zadanym zbiorze danych, dlatego warto eksperymentować z różnymi algorytmami, aby znaleźć najlepsze rozwiązanie.

Uczenie maszynowe to dziedzina ciągle się rozwijająca, dlatego ważne jest śledzenie artykułów naukowych na temat najnowszych modeli i ich zastosowań. Praktycznie co miesiąc pojawiają się nowe modele "state of the art", znacznie lepsze od swoich poprzedników. Doskonałym przykładem jest rozwój algorytmów do detekcji obiektów YOLO - "You Only Look Once", które z każdą iteracją poprawiają jakość predykcji oraz zmniejszają czas potrzebny na wyuczenie modelu.
4. Trening modelu
Wybrany model (lub modele) należy zaimplementować i wytrenować na zestawie danych treningowych. Częstą praktyką jest budowanie modelu „od zera” z użyciem bibliotek TensorFlow lub Pytorch. Można też skorzystać z gotowych architektur lub pre-trenowanych modeli dostępnych na huggingface, torchvision.models, czy tensorflow.keras.applications.
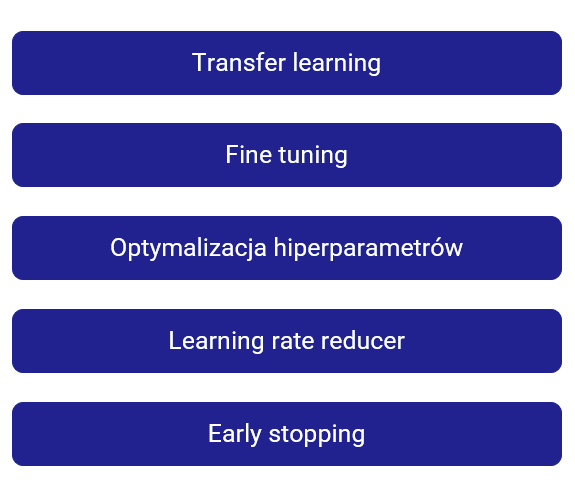 Trening i optymalizacja hiperparametrów modelu ResNet na potrzeby projektu Visual Search
Trening i optymalizacja hiperparametrów modelu ResNet na potrzeby projektu Visual Search
Przydatną techniką jest transfer learning, czyli wykorzystanie modelu wytrenowanego na potrzeby podobnego problemu i tylko douczenie go na własnym zbiorze danych.
Na tym etapie warto też skupić się na dostosowaniu hiperparametrów modelu. Tutaj z pomocą przychodzą biblioteki takie jak Ray czy Optuna, pozwalające na przeszukanie przestrzeni hiperparametrów w sposób optymalny. Przydatnym narzędziem jest również mLflow Tracking, czyli biblioteka służąca do rejestrowania modeli, hiperparametrów, metryk ewaluacyjnych i plików wyjściowych podczas uruchamiania I testowania kodu.
5. Ocena modelu
Skuteczność wytrenowanego modelu można ocenić poprzez porównanie predykcji modelu z rzeczywistymi wartościami, używając różnych metryk ewaluacyjnych. Ważne jest, aby zidentyfikować wszelkie obszary, w których model może osiągać słabe wyniki lub być nadmiernie dopasowany. W odróżnieniu od konkursów Kaggle, w rzeczywistych projektach duży nacisk kładzie się na tworzenie modeli, które nie tylko osiągają najlepsze wyniki w przyjętej metryce, ale są także wydajne i skalowalne. Dodatkowo, w niektórych branżach takich jak finanse i opieka zdrowotna, na równi ze skutecznością modelu stoi jego interpretowalność, czyli możliwość wyjaśnienia jak model doszedł do konkretnego przewidywania.

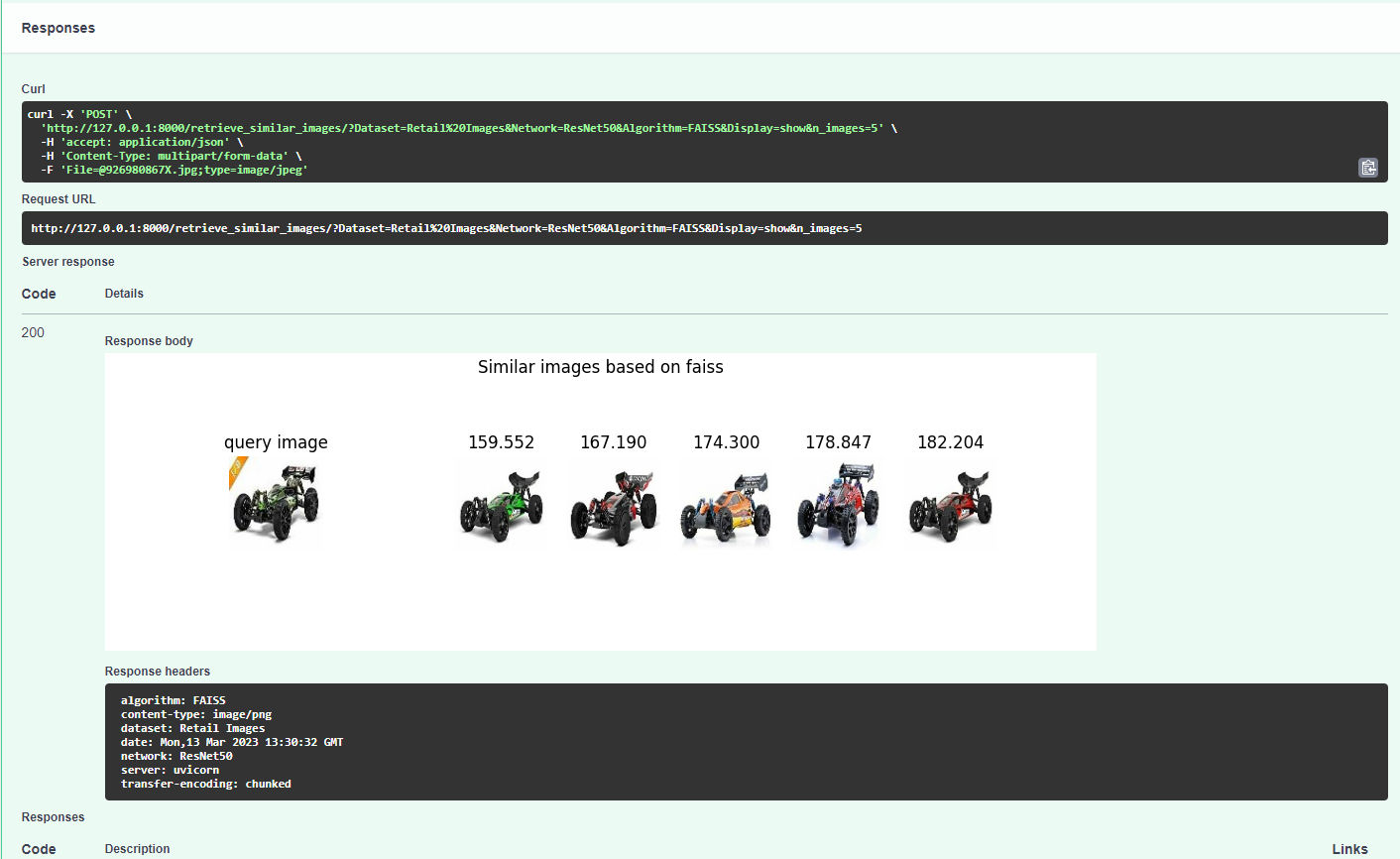
Porównanie wyników Visual Search
6. Produktyzacja i wdrożenie
Na koniec wytrenowany model należy przygotować do wdrożenia jako produkt lub usługa.
Obejmuje to dokładne przetestowanie modelu, ocenę jego wydajności na różnych zestawach danych, pisanie dokumentacji i wersjonowanie. Tak przygotowany model wraz z zależnościami jest pakowany do kontenera (docker container) i „wypuszczany w świat”.
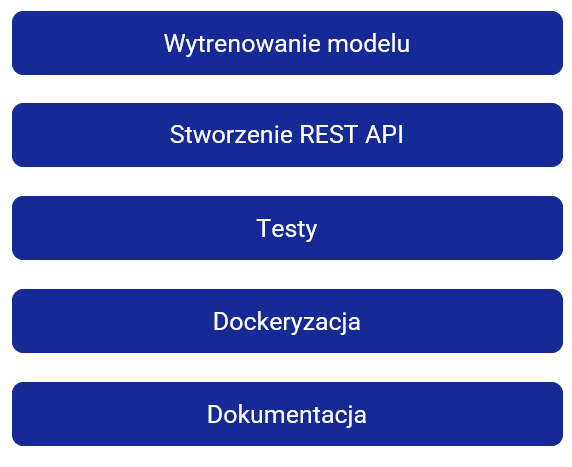 Kolejne etapy produktyzacji
Kolejne etapy produktyzacji
Spakowany modeli może być szybko i łatwo wdrożony w środowisku produkcyjnym. Może to oznaczać integrację modelu z istniejącą aplikacją lub wdrożenie modelu do usługi chmurowej.
Podsumowanie
Jeżeli więc temat uczenia maszynowego Cię zainteresował, dołącz do nas i przekonaj się sam, jak wygląda praca machine learning engineer’a lub aplikuj na wakacyjny staż IT i rozwijaj się w takich dziedzinach jak programowanie, DevOps, aplikacje mobilne, czy cyber security.