Pisanie błyskawicznie szybkiego kodu z CUDA

Zanim zagłębimy się w pisanie naszej super szybkiej aplikacji, musimy poznać podstawową terminologię. Dodatkowo tutaj możesz znaleźć instrukcję instalacji CUDA i inne wymagania.
Obliczenia równoległe: forma architektury, w której wykonujemy nasze proces równolegle.
GPU: na polu obliczeń równoległych mówimy o naszych GPU jako o urządzeniach (device).
CPU: na polu obliczeń równoległych mówimy o naszym CPU jako o hoście.
CUDA: framework i API opracowane przez NVIDIA, które pozwalają budować aplikacje przetwarzające równolegle, przez wykonywanie kodu na GPU NVIDII.
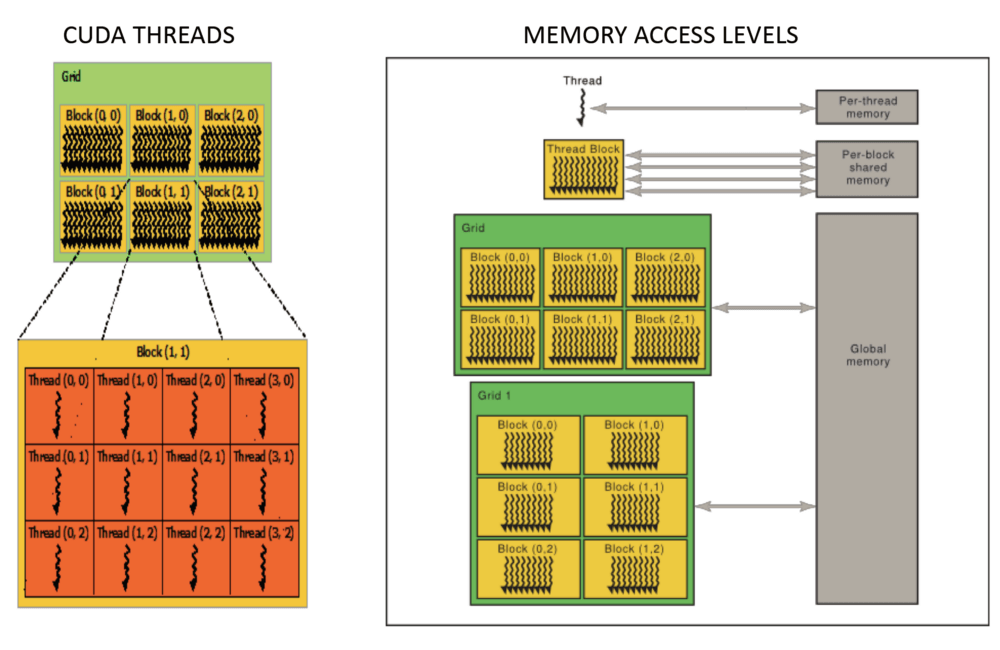
Wątek: łańcuch instrukcji, który działa na rdzeniu CUDA o określonym indeksie. Możesz mieć do 32 wątków CUDA działających współbieżnie na jednym rdzeniu CUDA.
Blok (Block): To kolekcja wątków.
Siatka (Grid): To kolekcja bloków.
Jądra (Kernels): Funkcje uruchamiane przez hosta i wykonywane na urządzeniach.
Użyjmy GPU!
Wszystkie przykłady zostały wykonane na NVIDIA Tesla V100 GPU.
Hello world!
Zacznijmy od prostego programu w C++, który wylicza sumę dwóch tablic, które mają po milion elementów.
#include <iostream>
#include <math.h>
#include <chrono>
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x = new float[N];
float *y = new float[N];
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
auto t1 = std::chrono::high_resolution_clock::now();
add(N, x, y);
auto t2 = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>( t2 - t1 ).count();
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
std::cout << duration;
delete [] x;
delete [] y;
return 0;
}
Może się wydawać, że jest tego dużo, ale przeanalizujmy ten kod.
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
Wszystko, co tu robimy, to stworzenie funkcji, która dodaje elementy tablic x i y.
int main(void)
{
int N = 1<<20; // 1M elements
float *x = new float[N];
float *y = new float[N];
Ty mamy naszą funkcję main, która tworzy liczbę całkowitą N, która ustali rozmiar naszych tablic. Dodatkowo uzupełnimy nasze tablice.
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
Pętla for pozwala nam zainicjalizować tablice x i y na hoście.
auto t1 = std::chrono::high_resolution_clock::now();
add(N, x, y);
auto t2 = std::chrono::high_resolution_clock::now();
Tu po prostu wywołujemy funkcję add. Dodatkowo używamy chrono, które pozwala nam zmierzyć czas wykonania naszej funkcji.
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
std::cout << duration;
To pozwala nam sprawdzić obecność błędów i czas poświęcony na wykonanie naszej funkcji.
delete [] x;
delete [] y;
Po wykonaniu zwalniamy zarezerwowaną pamięć.
Kompilowanie
Skoro mamy nasz program “Hello world”, to musimy go skompilować. Możemy to zrobić wykorzystując różnorodne narzędzia w zależności od systemu operacyjnego. Ja używam Ubuntu i g++. By skompilować swój program po prostu odpal:
g++ helloWorld.cpp -o helloWorld
By wykonać program, odpalamy go tak, jak każdy inny skrypt:
./helloWorld
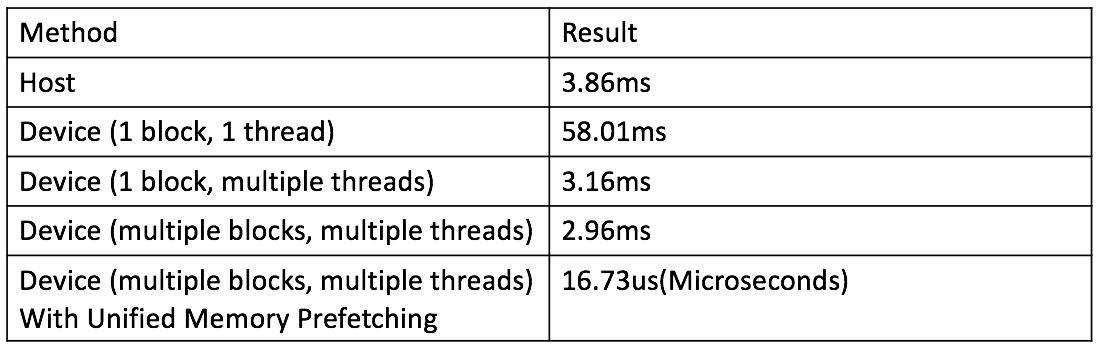
Po zakończeniu programu helloWorld, będzie widać dwie wypisane linijki. Pierwsza wskazuje, że nie mamy błędów “Max error:0”, a druga powie, jak szybko udało nam się wykonać funkcję - w moim przypadku było to 3,860ms.
Musimy przyspieszyć!
3,860ms to nie jest jakaś tragedia, ale możemy znacznie przyspieszyć.
Uwaga: To ważne, żeby zrozumieć, że nie wszystkie operacje będą działać szybciej na GPU. Prędkość wykonania zawsze będzie zależeć od mnóstwa czynników - takich jak rozmiar danych albo wymagana ilość obliczeń. Nasz przykład, mimo, że jest szybszy na CPU wobec wymaganej liczby iteracji na GPU, to służy tylko jako przykład wprowadzający. Miej to na uwadze, czytając ten turorial.
Tutaj zaczeniemy używać CUDA, by wykonać nasz kod na urządzeniu, a nie na hoście.
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
Możemy to osiągnąć przez dodanie specyfikatora __global__ do naszej funkcji add. Ten specyfikator mówi kompilatorowi CUDA, że ta funkcja powinna zostać uruchomiona na urządzeniu.
float *x, *y;
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
...
// Free memory
cudaFree(x);
cudaFree(y);
Musimy też zaalokować dane w pamięci wspólnej (unified memory), co możemy osiągnąć przez wywołanie cudaMallocManaged. To ma zamienić oryginalne wywołania new. Dodatkowo musimy zamienić nasze wywołania delete przez cudaFree. To zwalnia pamięć na urządzeniu w momencie, gdy jej nie potrzebujemy.
add<<<1, 1>>>(N, x, y);
To wywołanie funkcji uruchamia jeden blok na urządzeniu, z jednym wątkiem, by wykonać naszą funkcję add.
cudaDeviceSynchronize();
Na koniec musimy dodać wywołanie funkcji cudaDeviceSynchronize. To w zasadzie mówi CPU, że ma poczekać aż GPU skończy, zanim będzie próbować dostać się do wyników.
Kompilacja i test!
nvcc helloWorld.cu -o helloWorld
By skompilować program CUDA, musimy zachować nasz plik z rozszerzeniem .cu i skompilować program przez nvcc, czyli kompilatorem CUDA.
nvprof ./helloWorld
CUDA zapewnia również sprytne małe narzędzie zwane nvprof, które pozwala nam na podejrzenie czas wykonania poszczególnych funkcji.
Powinniśmy uzyskać taki output.
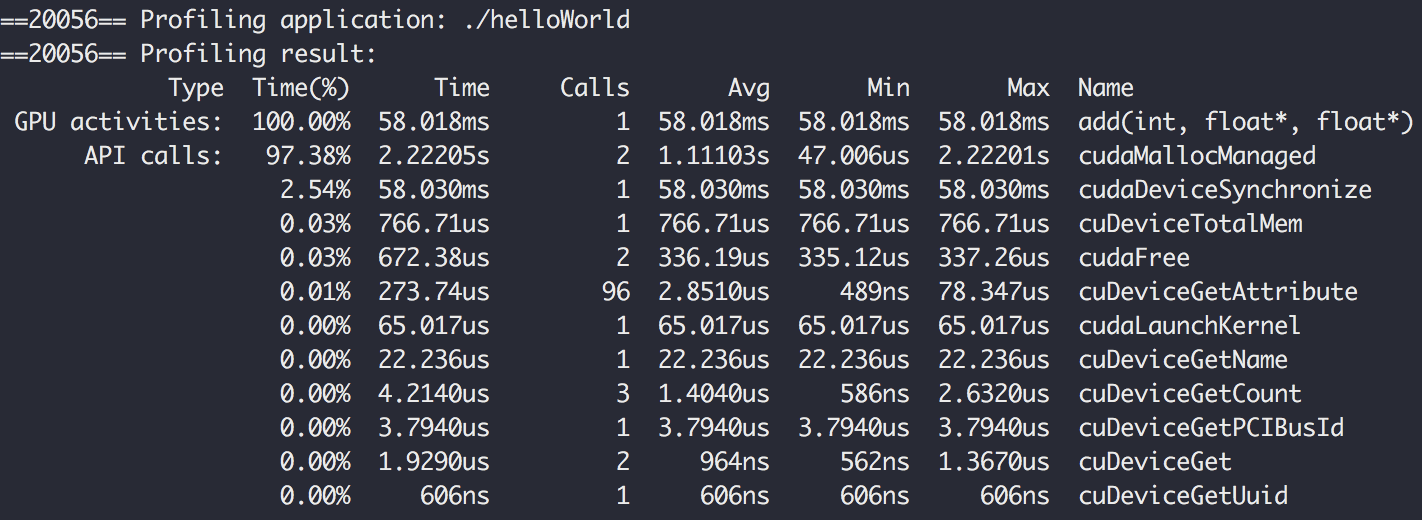
Jak możemy zobaczyć wykonanie funkcji add zajęło 58,018ms. Nie jest źle, ale może być lepiej.
Zrównoleglenie
Powyżej wykonaliśmy funkcję add na pojedynczym bloku z jednym wątkiem na naszym urządzeniu. Zróbmy to teraz równolegle, przez dodanie większej liczby wątków i przy okazji przyspieszmy działanie funkcji add.
add<<<1, 256>>>(N, x, y);
Po pierwsze, musimy zaktualizować wywołanie funkcji add, poprzez zmianę drugiego parametru z 1 do 256. Drugi parametr definiuje liczbę wątków w bloku.
__global__
void add(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
Dodatkowo musimy przejść przez pętle równoległymi wątkami. threadIdx.x zawiera indeks bieżącego wątku w bloku a blockDim.x zawiera liczbę wątków w bloku.
Powyższa pętla nazywa się stride loop i możecie o niej poczytać tutaj.
Skompilujmy nasz plik i odpalmy go ponownie.
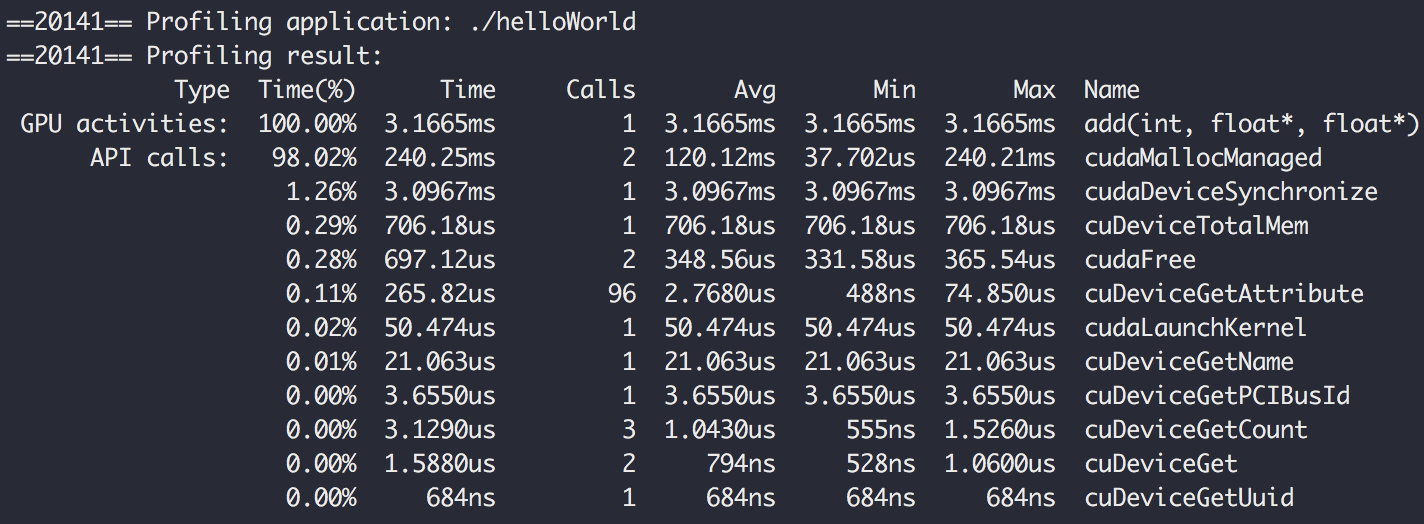
Widać imponujący spadek czasu wykonania z 58,018ms do 3,166ms
Więcej bloków!
By w pełni wykorzystać nasze wątki, musimy uruchomić jądro w wielu blokach wątków.
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);
Ustalamy nasz blockSize na 256 i dzielimy N przez blockSize, by wyliczyć liczbę bloków, których potrzebujemy dla N wątków. Wtedy musimy również sparametryzować funkcję add, by wywołać ją z nowymi parametrami
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
Dodatkowo musimy zaktualizować nasz kod jądra, by użyć całej siatki bloków wątków. Zobaczmy, co się pod tym kryje.
gridDim.x: Zawiera liczbę bloków w siatce.
blockIdx.x Zawiera indeks bieżącego bloku w siatce.
blockIdx.x * blockDim.x + threadIdx.x: Logika tutaj jest taka, że chcemy znać indeks wątku poprzez wyliczenie jego bloku i dodanie jego indeksu wewnątrz bloku.
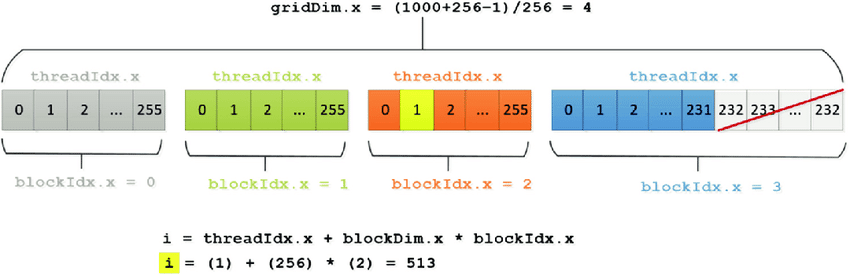
Kiedy skompilujemy i odpalimy nasz kod ponownie dostaniemy taki rezultat.
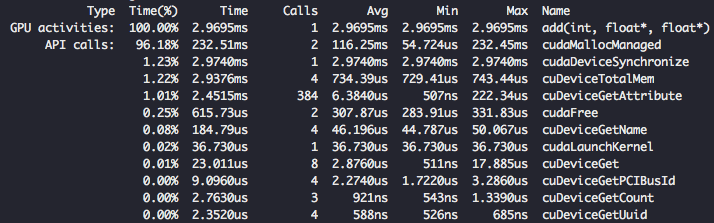
Widać niewielki wzrost wydajności… Przyczyną tak małego wzrostu wydajności jest koszt przerzucania danych między CPU a GPU, który został zawarty w czasie wykonania jądra.
Jak możemy to naprawić?
Prefetching pamięci wspólnej
Pamięć wspólna zachowuje się jak pojedynczy adres w pamięci, który jest dostępny z dowolnego procesora. To pozwala naszemu GPU na dostęp do każdej strony w naszej całej pamięci i przeniesienie danych do jego własnej pamięci, która jest bardziej wydajna. Możesz znaleźć więcej informacji o pamięci wspólnej tutaj.
Prefetching w zasadzie przenosi te dane do pamięci naszego urządzenia przed wykonaniem funkcji, więc oszczędza czas na migrowaniu danych.
int device = -1;
cudaGetDevice(&device);
cudaMemPrefetchAsync(x, N*sizeof(float), device, NULL);
cudaMemPrefetchAsync(y, N*sizeof(float), device, NULL);
Możemy zaimplementować prefetching powyższym kodem, tuż przed wywołaniem naszej funkcji add.
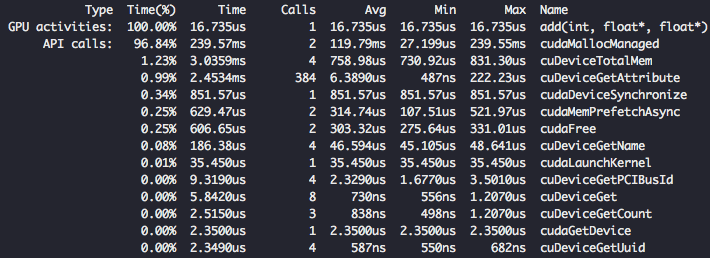
Wow, 16.73us. To z pewnością spora poprawa z poprzednich 2m96ms. Zakończmy porównując wyniki otrzymane w tym tutorialu!
Mam nadzieję, że ten post wprowadzający do CUDA okazał się przydatny i zachęci Cię do eksperymentowania z różnymi funkcjami arytmetycznymi i zobaczenia, jak szybko możesz je wykonać.