Paginacja SQL – robisz to źle!

Każda aplikacja napotyka na te problemy na wczesnym etapie rozwoju: trzeba ograniczyć ilość danych wysyłanych do klienta w związku z jego żądaniami, aby nie dopuścić do pogorszenia jakości usług. Z tym pytaniem możemy spotkać się bardzo często: jak wdrożyć to rozwiązanie?
Przeanalizujemy prosty przypadek użycia paginacji dla obiektu tabeli zawierającego 1000000 wierszy. Rozważamy dwa różne przypadki paginacji: jeden z unikalnym kluczem podstawowym id, a drugi z nazwą tenanta (pole varchar z indeksem).

Prosta implementacja
Najprostszym rozwiązaniem dla paginacji, które można znaleźć wszędzie w Internecie jest zastosowanie wartości LIMIT i OFFSET.

Wypróbujmy to zapytanie dla dwóch indeksowanych kolumn (id i tenant), z różnymi wartościami OFFSET:
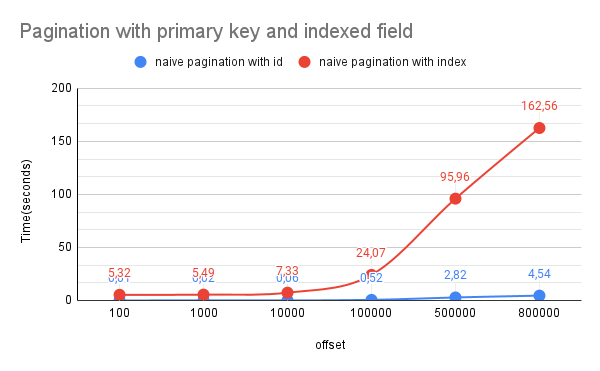
Gdy sprawdzimy plan optymalizatora bazy danych dla naszego zapytania o paginację, zauważymy, że baza danych używa operacji sortowania zawartości pliku do uporządkowania kolumny bez indeksowania oraz indeksu dla kolumny tenant i id. Na tej podstawie możemy stwierdzić, że:
- Użycie offsetu na posortowanej kolumnie bez indeksowania jest trudnym zadaniem dla bazy danych i należy go unikać za wszelką cenę.
MySQL musi wykonać dodatkową operację, aby dowiedzieć się, jak zwrócić wiersze w posortowanej kolejności. Sortowanie odbywa się poprzez przejście przez wszystkie wiersze zgodnie z typem sprzężenia i zapisanie klucza sortowania oraz wskaźnika do wiersza dla wszystkich wierszy, które pasują do klauzuli WHERE.
- Zastosowanie
OFFSET, nawet na kluczu głównym, staje się z czasem wolniejsze w przypadku dużego rozmiaru bazy danych, ponieważ liczba wierszy, które muszą zostać wczytane, aby zostały pominięte, staje się coraz większa. - Użycie offsetu na polu indeksowanym z dużym
key_lenghtjest wolniejsze niż na małymkey_lenght.
Jak widać, paginacja OFFSET ma pewne wady:
- W przypadku dużych rozmiarów bazy danych strony końcowe są trudniejsze do wyszukania niż strony początkowe, ponieważ liczba wierszy do załadowania i pominięcia jest duża.
- W przypadku rosnącej bazy danych docieranie do początkowych wierszy staje się z czasem coraz mniej efektywne. (4,54 s lub 160 s według zapytania staje się bezużyteczne dla witryny z tysiącami użytkowników)
- Gdy użytkownik przeskakuje od strony do strony, po wstawieniu wiersza, w zależności od sortowania kolumn, może nie zauważyć nowego elementu i zobaczyć zduplikowany obiekt (ostatni element poprzedniej strony).
Ponieważ wdrożenie paginacji OFFSET jest wygodne na początku projektu (nie trzeba przewidywać planu zapytań, przypadków użycia sortowania UI i tworzenia indeksów), często zdarza się, że wydajność aplikacji powoli spada i z czasem staje się ona bezużyteczna. Jednak ze względu na sposób określania wartości OFFSET baza danych musi iterować przez wszystkie wiersze OFFSET, co sprawia, że to rozwiązanie staje się bardzo nieefektywne.
Metoda wyszukiwania paginacji
Jak można było wcześniej zobaczyć, nawet jeśli spróbujemy użyć indeksu, OFFSET sprawi, że będzie to nieefektywne, ponieważ wszystkie zaangażowane wiersze muszą zostać załadowane, a my będziemy musieli stworzyć zapytanie, które użyje indeksu, aby zwrócić strony, do których chcemy dotrzeć.

Sprawdźmy, ile czasu zajmuje to zapytanie podczas iteracji po ostatnim id.
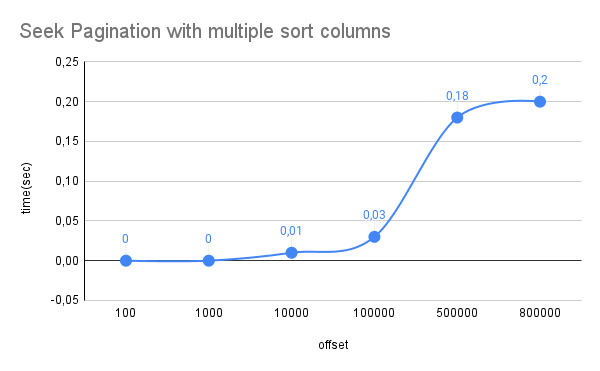
Wynik pokazuje, że w naszym przypadku wygraliśmy o wiele rzędów wielkości, dzięki czemu czas odpowiedzi na zapytanie jest mniej zależny od rozmiaru bazy danych. Przy przechodzeniu na metodę paginacji Seek można jednak zauważyć pewne zmiany:
- Nie możemy już polegać na zachowaniu interfejsu użytkownika pod względem numeru strony, ponieważ teraz polegamy na tokenie, który oddajemy aplikacji, aby uzyskać następną stronę (ostatnie id poprzedniej strony).
- Należy zastanowić się, która kolumna będzie używana do paginacji, ponieważ będzie nam potrzebny odpowiedni indeks.
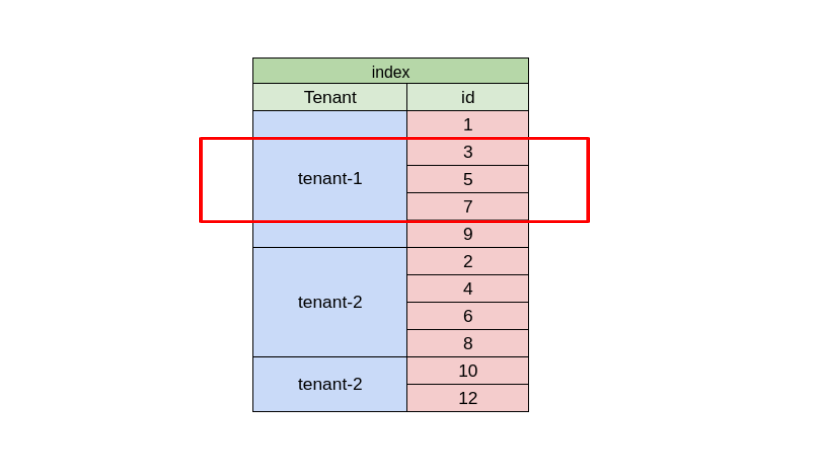
- Jeśli chcemy porządkować według kolumny, która nie jest unikalna, musimy stworzyć indeksy wielokolumnowe (używając klucza głównego jako jednej z kolumn) i dostosować nasze zapytanie tak, aby nawigowało po naszym indeksie:
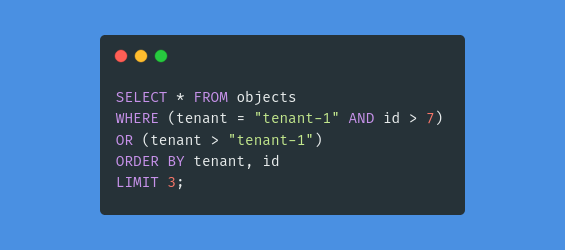
To rozwiązanie sprawia, że paginacja jest naprawdę wydajna, ale zwiększa złożoność programowania: musimy uwzględnić w schemacie naszej bazy danych paginację i dozwolone kolumny sortowania.
Jak to zwykle bywa w inżynierii oprogramowania, wydajność to kwestia kompromisu.
W tym artykule przekonaliśmy się, jak wyeliminować używanie paginacji OFFSET w naszej bazie danych SQL, gdy wydajność jest krytyczna.
W zamian za pewną złożoność i utratę funkcji metoda seek zapewnia jeden z najszybszych, niezależnych od dostawców SQL, sposób stronicowania danych.