Optymalizacja wydajności poprzez statyczną analizę kodu

 Statyczny analizator kodu to narzędzie, które parsuje kod programu oraz dokonuje jego analizy według wcześniej zdefiniowanych reguł. Najbardziej popularne narzędzia tego typu dla technologii Java to m. in. Checkstyle, PMD oraz Findbugs. Rozwiązania te kojarzone są zazwyczaj z odnajdywaniem drobnych błędów takich jak niewykorzystywana zmienna bądź wykrywaniem odstępstw od standardów nazewnictwa klas, metod bądź zmiennych. W naszej firmie odkryliśmy, że statyczna analiza kodu doskonale nadaje się również do wykrywania wielu typowych problemów wydajnościowych takich jak nadmiarowe zapytania do bazy danych, nieoptymalny kod albo nawet wycieki pamięci.
Statyczny analizator kodu to narzędzie, które parsuje kod programu oraz dokonuje jego analizy według wcześniej zdefiniowanych reguł. Najbardziej popularne narzędzia tego typu dla technologii Java to m. in. Checkstyle, PMD oraz Findbugs. Rozwiązania te kojarzone są zazwyczaj z odnajdywaniem drobnych błędów takich jak niewykorzystywana zmienna bądź wykrywaniem odstępstw od standardów nazewnictwa klas, metod bądź zmiennych. W naszej firmie odkryliśmy, że statyczna analiza kodu doskonale nadaje się również do wykrywania wielu typowych problemów wydajnościowych takich jak nadmiarowe zapytania do bazy danych, nieoptymalny kod albo nawet wycieki pamięci.
Statyczna analiza kodu jest częścią procesu „continuous integration” – jest uruchamiana w nocy, na wszystkich repozytoriach, w których nastąpiły zmiany kodu. Dzięki temu jesteśmy w stanie wykryć wiele problemów wydajnościowych już na etapie tworzenia kodu – zanim aplikacja trafi do testów.
Nasz zbiór reguł analizatora kodu powstał na bazie technologii Sonar (www.sonarsource.com) i jest ciągle rozbudowywany. Poniżej opisałem kilka ciekawych reguł, które być może okażą się dla Was przydatne.
Częste zapytania do bazy danych
Jednym z typowych problemów wydajnościowych wielu aplikacji są częste odwołania do bazy danych. Przy dzisiejszych możliwościach infrastruktury, wykonanie prostego zapytania na bazie danych jest dosyć szybką operacją i może trwać około 1 ms. Problemy zaczynają się jednak gdy wykonujemy duże ilości takich zapytań – na przykład w pętli – a ich liczba zależy od rozmiaru danych wejściowych.
Weźmy jako przykład taki fragment kodu:

Jest to całkowicie poprawny kod, który wzorowo przejdzie wszystkie możliwe testy funkcjonalne. Może nawet działać przez jakiś czas po wdrożeniu. Może też nadejść dzień, w którym użytkownik systemu załaduje plik zawierający 100’000 transakcji płatniczych, który spowoduje wykonanie 100’000 zapytań do bazy danych, co będzie skutkowało znacznie dłuższym czasem przetwarzania, być może nawet wycofaniem transakcji po przekroczeniu timeout-u.
Aby zapobiec tego typu problemom zaimplementowaliśmy regułę analizatora, która wykrywa operacje bazodanowe wykonywane w pętlach – jako potencjalnie niebezpieczne fragmenty kodu. W części przypadków okazuje się, że można całą pętlę zastąpić jednym zapytaniem „update ...”, aktualizującym te same rekordy wybrane przez klauzulę „where”. Można też stosować mechanizm grupowania („batchowania”) zapytań, aby znacznie zredukować ich ilość.
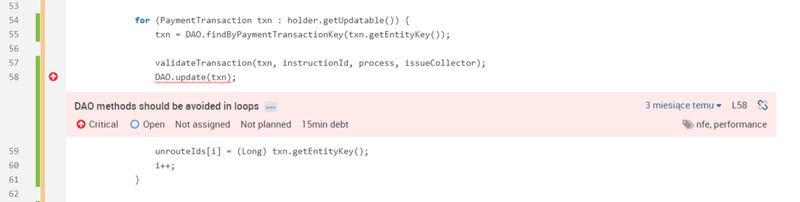
Wykrywanie częstych zapytań do bazy danych
Wyciek zasobów
Przez zasób rozumiemy tu przede wszystkim połączenia do bazy danych bądź serwera kolejek komunikatów. Wyciek połączeń to nic innego jak brak kodu zamykającego połączenie, lub ogólniej – zwalniającego zasób. Jest to bardzo groźny błąd, jednocześnie dosyć trudny do wykrycia przy pomocy typowych testów. Otwarte połączenia mogą z czasem zająć całą dostępną pamięć maszyny wirtualnej, albo spowodować wyczerpanie puli połączeń – w obu przypadkach prowadzą do destabilizacji systemu.

Przykładowy kod z brakującym wywołaniem trnIter.close() w bloku finally
Wykrywanie wycieków poprzez statyczną analizę kodu nie jest trywialnym zadaniem. W bardziej skomplikowanych przypadkach – kiedy połączenia są przekazywane pomiędzy metodami, albo umieszczane w osobnej strukturze danych (np. mapie lub liście) – znalezienie błędu może okazać się niemożliwe. Trzeba pamiętać, że statyczna analiza jest „słabsza” niż faktyczne wykonanie kodu – przede wszystkim nie zna kontekstu: stosu wywołań oraz stanu zmiennych. Nie mniej jednak w praktyce skomplikowane przypadki stanowią margines.
Używanie prekompilowanych wyrażeń regularnych
Programiści często zapominają, że wyrażenia regularne to w rzeczywistości mini programy, kompilowane przez JVM w trakcie działania aplikacji. Kompilacja wyrażeń oczywiście ma swój koszt, który może być zaniedbywalny w pojedynczych przypadkach – w końcu nie ma tu operacji I/O, tylko i wyłącznie czas procesora – należy jednak pamiętać o efekcie skali – dany fragment kodu może być wielokrotnie wykonywany np. w pętli, albo na wielu równoległych wątkach.
Na szczęście zarówno wykrycie jak i naprawa takich fragmentów kodu jest bardzo łatwa – przykład poniżej:
Źle:
Dobrze:
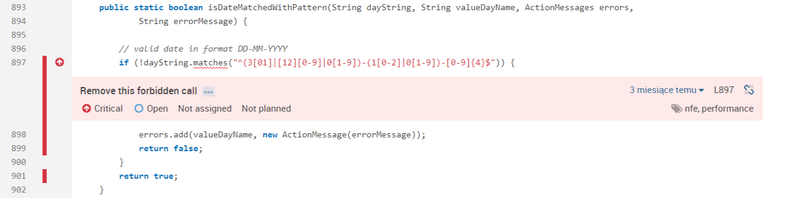
Wykrywanie nieoptymalnego zastosowania wyrażeń regularnych
Implementacja
Zainteresowanych szczegółami rozwiązania odsyłam do dokumentacji Sonar (www.sonarsource.com). Implementacja reguł jest stosunkowo łatwa i polega na rozszerzeniu klasy BaseTreeVisitor – jest to abstrakcyjna klasa z pakietu org.sonar.plugins.java.api.tree która implementuje przejście po drzewie składni zgodnie ze wzorcem Tree Visitor.
Poniżej przykład implementacji jednej z reguł analizatora kodu:
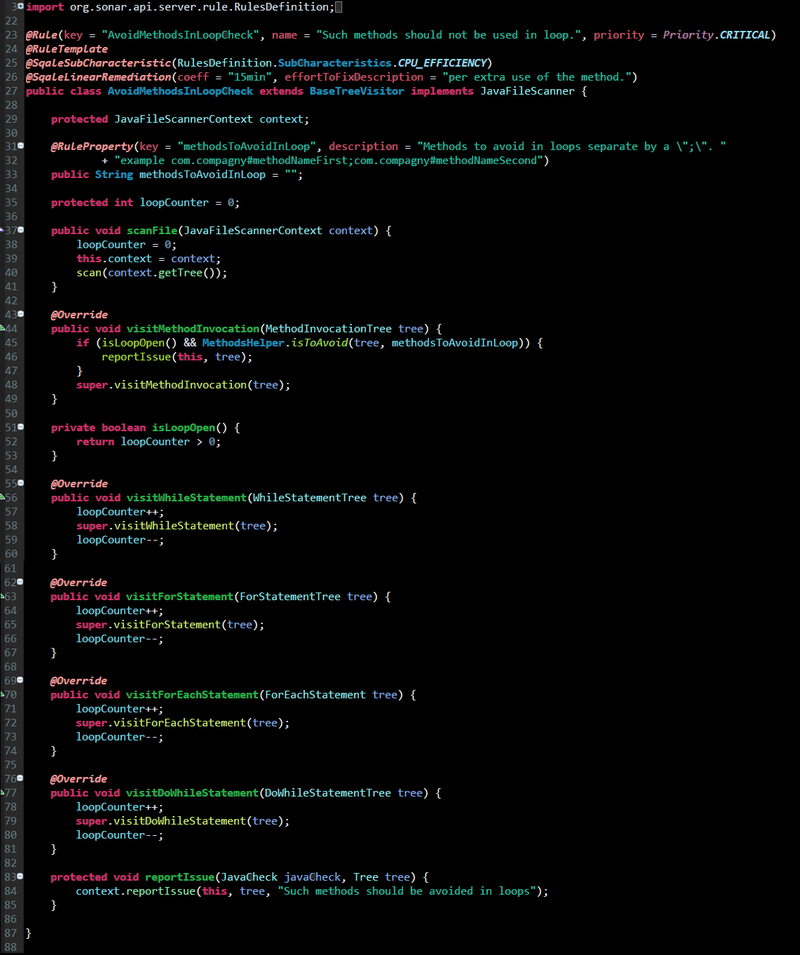
Implementacja reguły AvoidMethodsInLoopCheck
Podsumowanie
Statyczna analiza kodu nie jest w stanie wykryć wszystkich problemów wydajnościowych. Nie zastąpi ona prawdziwych testów wydajnościowych – uruchamianych na dużych zbiorach danych i środowiskach zbliżonych do produkcyjnego – stanowić może jednak wartościowe rozwiązanie uzupełniające, które pozwala na „odsianie” sporej ilości problemów na bardzo wczesnym etapie.
Kolejnym usprawnieniem, nad którym pracujemy jest analiza kodu „na żywo” – już w środowisku programistycznym (IDE), w trakcie pisania kodu. W ten sposób środowisko same zwróci programiście uwagę na problem wydajnościowy, który będzie można naprawić jeszcze przed wysłaniem zmian do repozytorium.
Autor: Robert Popławski (IT Architect Specialist)