Niestabilne testy w Cypress: skąd się biorą i jak sobie z nimi radzić

Testerzy automatyzujący często spotykają się z niestabilnymi testami. Nie jest łatwo uniknąć tego zjawiska, problematycznym czynią je również trudności z naprawą tego typu testów. Zanim jednak przejdziemy do przyczyn ich powstawania, przyjrzyjmy się definicji niestabilnego testu.
Test niestabilny — test jest uważany za niestabilny (ang. flaky test), kiedy może raz przejść a przy kolejnych powtórzeniach nie przejść, mimo żadnych zmian w kodzie.
Na przykład wykonanie testu kończy się niepowodzeniem, a podczas ponownego wykonania, bez zmiany kodu, test udaje się przeprowadzić.
Wpływ niestabilnych testów na proces testowania
Niestabilne testy mają istotny wpływ na proces ulepszania jakości oprogramowania. A ich wpływ na postępy w projekcie widać między innymi w następujących obszarach:
1. Niestabilne testy wydłużają testowanie nowej wersji systemu
Jeśli mamy testy, które raz nam przechodzą, a raz nie przechodzą, to w pewnym momencie nie wiemy, czy ten test nie przeszedł z powodu błędu w kodzie źródłowym aplikacji, czy był to po prostu flaky test, który przy kolejnym uruchomieniu zapewne zakończy się wynikiem pozytywnym.
W efekcie musimy ponownie uruchamiać testy na CI lub uruchamiać cały build aplikacji, gdzie jednym z ostatnich kroków jest przeprowadzanie testów, które pozwolą ponownie sprawdzić, czy były to błędy w aplikacji, czy problem z testami.
Jest to jeszcze bardziej dotkliwe, gdy korzystamy z usług chmurowych, gdzie jesteśmy rozliczani z czasu i wykorzystanych zasobów: kilkukrotne uruchomienie tych samych testów na tej samej wersji zwiększa koszt takiej operacji.
2. Dłuższy czas naprawiania testów
Niestabilne testy absorbują bardzo dużo uwagi i czasu testerów automatyzujących, ponieważ musi on sprawdzić, czy poprawiony test zawsze przechodzi, czy tylko czasami, ale częściej niż poprzednio.
Dodatkowo musi to zostać zweryfikowane na CI na docelowej maszynie i środowisku uruchomieniowym.
3. Zmniejszona pewność co do wyników testów
Przy dużej ilości niestabilnych testów nie wiemy, czy duża ilość „czerwonego” oznacza, że mamy dużo błędów czy po prostu flaky testy nie przeszły tym razem. Przez to wzrasta obojętność na czerwone wyniki i takie rezultaty są brane coraz mniej serio i zaczynają padać stwierdzenia: że te błędy to pewnie niestabilne testy, które znowu nie przeszły.
Dlatego bardzo istotne jest, aby testy zwracały jasny komunikat: albo przechodzą pozytywnie, albo jest błąd w aplikacji i testy w związku z tym nie przechodzą.
Kolejnym problemem związanym z flaky testami jest to, że podczas wykonywania niestabilnego testu prawdziwy błąd pozostanie niewychwycony, ponieważ zostanie ukryty pod flaky testami.
Przyczyny niestabilnych testów
1. Niestabilne testy związane z DOM (Document Object Model)
- występują, gdy elementy się nie pojawiają – np. chcemy kliknąć element, który się nie załadował,
- elementy pojawiają się za późno – wprawdzie element zostanie załadowany, ale po upływie zdefiniowanego w testach czasu oczekiwania na element,
- elementy nie wyglądają tak, jak powinny – za sprawą niedoładowania części strony, elementy mogą inaczej wyglądać i przy źle zbudowanym selektorze nie zostaną znalezione,
- elementy mają atrybuty świadczące o niemożności ich użycia np. włączoną przeźroczystość, parametr disabled itp.
Kilka zrzutów ekranu z runnera Cypressa i błędami związanymi z Document Object Modelem:
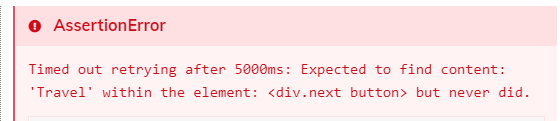
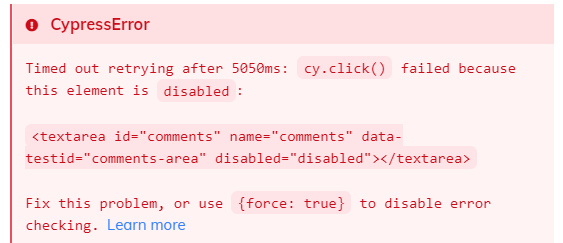
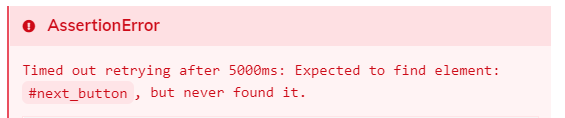
Przykłady:
- ładujące się lub nieładujące elementy – wpadnięcie w cy.get() timeout,
- znalezienie elementu, ale przy kliknięciu ciągle jest w statusie disabled, ponieważ stan nie zdążył się zmienić,
- przeładowanie drzewka DOM pomiędzy wykonaniem komendy cy.get() i komendą akcji (np. .click() ) - błąd detached from the DOM,
- zbyt szybkie wpisywanie w pola tekstowe tak, że aplikacja nie zdąży poprawnie przyjmować tekstu, a przycisk ‘dalej’ już zostanie kliknięty.
2. Niestabilne testy związane z siecią
Podstawowym problemem z niestabilnymi testami, kiedy przyczyny są związane z siecią, są wolne odpowiedzi API, które sprawiają, że elementy nie ładują się w zadanym czasie.
Kolejnym problemem są wolne odpowiedzi od systemów zależnych np. do płatności, obsługi logowania czy wyświetlania elementów osadzonych na stronie.
Zdarza się również, że niestabilność w testach jest spowodowana przez „zimny start serwisu” – gdzie pierwsze zapytanie jest wolniejsze i nie mieści się w zadanym maksymalnym czasie, natomiast wszystkie kolejne są już odpowiednio szybkie.
3. Niestabilne testy związane ze środowiskiem
Kolejną grupą przyczyn niestabilności testów są problemy ze środowiskiem. Jednym z częstszych problemów są przekierowania load balancera na różne maszyny docelowe. Jeśli ruch będzie przekierowany raz na wydajniejszą maszynę, to testy przejdą pozytywnie, innym razem load balancer może przekierować na wolniejszą maszynę, gdzie testy nie zakończą się powodzeniem.
Sposoby radzenia sobie z niestabilnymi testami
1. Izoluj test runy
Test runy muszą być od siebie odizolowane i nie wchodzić sobie w drogę, aby nie doszło do zjawiska, gdzie jeden test zmienia dane/parametry, które są wykorzystywane przez drugi test.
Jest to jedna z najbardziej podstawowych zasad, o jakich trzeba pamiętać, aby zapewnić stabilność testów.
Np. jeżeli mamy różne zespoły działające nad jednym produktem i zespoły puszczają testy w tym samym czasie, wtedy może dojść do „kolizji” i losowych niepowodzeń w testach.
2. Zrób testy niezależnymi od siebie
Wprawdzie jest to jedna z podstawowych dobrych praktyk tworzenia testów automatycznych, jednak niestety nie każdy tester o niej pamięta. Wciąż istnieją projekty, w których zespół zmaga się z testami, które nie przechodzą. Wcale nie tak rzadko okazuje się, że są one napisane tak, że kolejne testy są zależne od poprzednich.
3. Nigdy nie używaj cy.wait(liczba)
Jest to najważniejsza i najczęściej powtarzana zasada. Nigdy nie używaj cy.wait(), ponieważ:
- po pierwsze to mocno spowalnia testy,
- po drugie nie ważne, jaką liczbę wpiszesz, i tak nie masz pewności, że będzie wystarczająca.
Używanie statycznie zadeklarowanego oczekiwania jest złym podejściem i nie jest zgodne z dobrymi praktykami programowania!
Użycie cy.wait(liczba) powoduje stałe spowolnienie testów:
- jeśli element pojawi się po 1 sekundzie, a mamy waita ustawionego na 5 sekund, to marnujemy 4 sekundy,
- jeśli element pojawia się i znika, to z tym waitem możemy go przegapić (np. boczny pasek z dodanym produktem do koszyka),
- jeśli używalibyśmy statycznego waita do czekania na elementy przed każdym elementem, to nasze testy wykonywałyby się bardzo długo.
4. Trzeba wiedzieć, że Cypress automatycznie powtarza ostatnią komendę. I tylko ją!
Można to wykorzystać do takiego stworzenia testów, aby były bardziej stabilne.
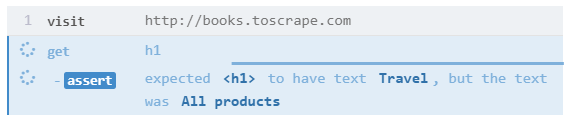
Jeżeli przy asercji tekstu znajdzie element np. h1, to potem będzie próbował porównać teksty na znalezionym elemencie. Jeżeli element zmieni się w międzyczasie, to nie będzie to wzięte pod uwagę i asercja będzie robiona na pierwszej znalezionej wersji.


Jak możemy wykorzystać tę wiedzę?
a) nie używać łączenia ze sobą komend

b) wykorzystywać komendy, które łączą w sobie potrzebne komendy i całość jest odświeżana np. używanie alternatywnych asercji z should
Przykład:

5. Aby ustabilizować testy, które są zależne od długiego oczekiwania na zapytania sieciowe, można użyć polecenia cy.intercept()
Pozwala to na oczekiwanie na wykonanie się wolnego zapytania sieciowego.

6. Automatyczne ponowne uruchamianie testów
Zdarzają się testy, które wymagają dużo czasu na ich przepisywanie od nowa. Bywa też, że mamy do poprawienia bardzo dużą ilość testów.
Co możemy wtedy zrobić z naszymi niestabilnymi testami?
Najprostszym i najszybszym sposobem jest ustawienie automatycznego, ponownego ich uruchamiania. W Cypressie od wersji 5.0 posiadamy natywne wsparcie tego i jest to bardzo proste i szybkie w implementacji.
Do pliku cypress.json dodaj:
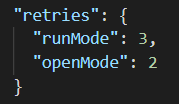
Można zdefiniować ilość powtórzeń dla różnych rodzajów uruchomień testów:
- dla uruchomienia z konsoli poprzez cypress run w powyższym przykładzie testy zostaną uruchomione maksymalnie 4 razy,
- dla uruchomienia w trybie graficznym poprzez cypress open testy zostaną uruchomione maksymalnie 3 razy.

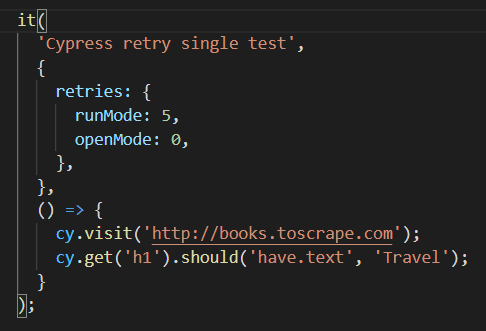
Poza globalnymi ustawieniami można ustawić powtarzalność dla pojedynczych testów:
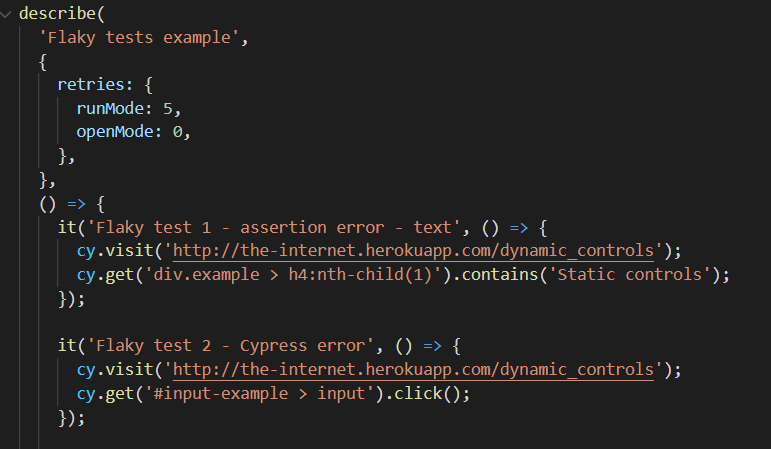
Niestabilne testy można również zebrać do Test Suitów i nadawać im odpowiednio parametry powtórzeń:
Podsumowanie, czyli o czym warto pamiętać
Trzy główne przyczyny niestabilnych testów:
- DOM– najczęściej występują, gdy elementy się nie pojawiają – np. chcemy kliknąć element, który się nie załadował lub elementy ładują się zbyt długo.
- sieć– podstawowym problemem z niestabilnymi testami, w których przyczyny są związane z siecią, są wolne odpowiedzi API, które sprawiają, że elementy nie ładują się w zadanym czasie.
- środowisko— jedną z częstszych przyczyn są przekierowania load balancera na różne maszyny docelowe posiadające różnice w wydajności czy architekturze.
Jak sobie radzić z niestabilnymi testami:
- nie używaj cy.wait(liczba)– jest to zła praktyka programistyczna i nie powinna być używana. Użycie stałych zatrzymań testów to poważne, stałe spowolnienie, które w dodatku ich nie naprawia, a tylko w pewnym stopniu maskuje problemy, ponieważ, żadna wpisana liczba nie daje gwarancji bycia wystarczającą,
- wykorzystaj fakt, że Cypress powtarza zawsze ostatnią komendę – poprzez odpowiednie budowanie i wykorzystywanie komend można w istotny sposób zwiększyć ich niezawodność, bez strat na wydajności,
- w przypadku API używaj cy.intercept()- polecenie to daje nam ogromne możliwości, a jednym z nich jest oczekiwanie na odpowiedź wolnego zapytania sieciowego,
- skonfiguruj automatyczne powtarzanie testów które, nie przeszły– stosowanie powyższych metod jest bardzo skuteczne, jednak w przypadku, gdy już posiadamy dużą ilość niestabilnych testów, poprawienie ich wszystkich wymaga dużo czasu. Nie zawsze w projekcie jest wystarczająca jego ilość na gruntowne poprawki. Wtedy można zacząć od wykorzystania automatycznego powtarzania testów.