Mikroapki, czyli the good, the bad and the ugly

Mikrofrontendy (MFE) zyskują od paru lat na popularności jako alternatywa do architektury monolitycznej. Poniżej opisujemy ścieżkę, którą przeszliśmy, żeby rozszerzyć naszą architekturę w CyberVadis o mikroapki, jeden z wariantów MFE.
W tym artykule chcemy przedstawić, co skłoniło nas do przejścia na taką architekturę, zobrazować poszczególne etapy oraz wskazać bardziej i mniej trafione decyzje. Może to case study przyda Ci się do wyciągnięcia wniosków na temat Twojego projektu.
Dodatkowo chcemy podzielić się przepisem na automatyzację wersjonowania bibliotek wewnętrznych - jest to jedno z wielu fajnych odkryć, do których doszliśmy w trakcie drogi do systemu mikroapkowego.
Punkt wyjścia
CyberVadis oferuje platformę do przeprowadzenia audytów cyberbezpieczeństwa i zarządzania nimi. Zarówno firma jak i platforma są stosunkowo młode i znajdujemy się w fazie szybkiego rozwoju. W momencie, kiedy rozważaliśmy zmiany architektoniczne, frontend liczył kilka osób, z podziałem na dwa zespoły.
Frontendowa część platformy od momentu powstania była rozwijana jako pojedyncza, monolityczna aplikacja. Warto dodać, że część backendowa od początku była rozwijana w oparciu o architekturę mikroserwisów.
Stack platformy został symbolicznie rozrysowany na poniższym rysunku:
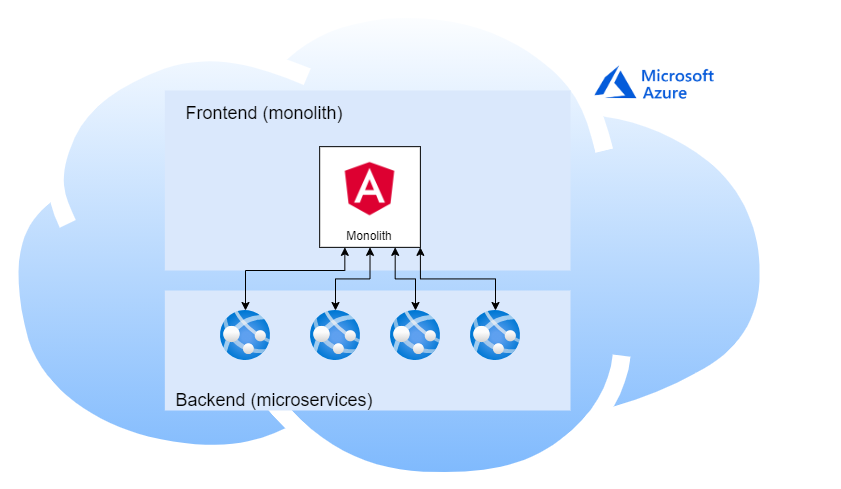
Czyli:
- frontend: pojedyncza aplikacja w Angularze (rozwój nowych feature’ów przez dodawanie kolejnych modułów)
- backend: mikroserwisy z podziałem domenowym
- infrastruktura: chmura Azure
Punktem wyjścia była zatem już stosunkowo stabilna, działająca platforma. Mimo niewielkiego zespołu z czasem zaczęliśmy odczuwać przypadłości charakterystyczne dla monolitu:
- dodawanie nowego feature’a, który nie był planowany od samego początku lub refactor, wymagały często zmian w całym kodzie
- coraz częstsze konflikty przy mergowaniu zmian
- rozmyta odpowiedzialność zespołu za określony fragment aplikacji
- dobór narzędzi (bibliotek) ma globalne znaczenie
- duży próg wejścia w duży projekt dla nowych programistów (utrudniona rekrutacja)
Zmęczenie powyższymi problemami, a także chęć poszukiwania nowych rozwiązań, pchnęło nas w stronę rozważenia architektury bazującej na mikrofrontendach jako odpowiedzi na monolityczne problemy.
Mikrofrontendy - z czym to się je
Warto zaznaczyć, że MFE nie jest jedną, jasno zdefiniowaną architekturą, a raczej pewną ideą którą można realizować na wiele sposobów. Obszerniejsze omówienie możliwych microfrontend flavors można przeczytać w tym artykule.
Pierwszą i najważniejszą decyzją jaką musieliśmy podjąć było wybranie rozwiązania, które najlepiej wpasowałoby się w nasz tryb pracy. Klasyczne podejście do MFE, z wieloma apkami frontendowymi na jednym widoku, nie do końca odpowiadało naszym wymaganiom. Po analizie problemu doszliśmy do wniosku, że doskonałym rozwiązaniem w naszym przypadku będą mikroapki.
Mikroapki FTW!
Czym dokładnie charakteryzują się mikroapki? Ten wariant mikrofrontendów to nieduże, w pełni niezależne aplikacje, rozwijane jako osobne projekty i deployowane na osobnych urlach. Połączenie ich jest możliwe za pomocą zwykłych linków.
Podejście mikroapkowe okazało się być mniej inwazyjne, bardziej ewolucyjne niż rewolucyjne. Mogliśmy zostawić starą aplikację, natomiast nowe funkcje implementować jako oddzielne mikroapki. Z czasem moglibyśmy również zacząć wyciosywać funkcje z monolitu. Budowa naszego backendu oraz uwierzytelnienie w oparciu o OAuth 2.0/OIDC powinny znacznie ułatwić pracę. Próg wejścia ograniczyłby się do nauczenia się nowych frameworków.
MFE w wariancie microapps daje nam większość zalet MFE:
- możliwość równoległego developmentu platformy przez niezależne zespoły frontendowe
- łatwy refactor
- łatwa możliwość podmiany narzędzi
- ułatwiona migracja starych systemów - można wydzielać pojedyncze feature’y do nowych mikroapek metodą małych kroków
- potencjalna dowolność doboru frameworków przy kolejnych feature’ach (opcja, z której ostatecznie zrezygnowaliśmy, ale o tym później)
Nie musimy się natomiast zmagać z wyzwaniami charakterystycznymi dla klasycznych mikrofrontendów, gdzie konieczne jest zwykle zastosowanie dodatkowego narzędzia do połączenia poszczególnych mikrofrontendów w pojedynczy widok (SingleSpa, Bit itp.).
Ogromnym plusem była też możliwość stosunkowo bezinwazyjnej integracji z naszym monolitem: ponieważ mikroapki są w pełni niezależnymi aplikacjami, integracja sprowadzała się do umieszczenia w istniejącej aplikacji odpowiedniego linka oraz do podłączenia mikroapek do naszego systemu uwierzytelniania.
W oczywisty sposób powyższe było wariantem najlepszym w naszej konkretnej sytuacji w danym momencie (mała skala, niewielkie zespoły, niezła komunikacja).
Implementacja
Mikroapki dają, co prawda, potencjał na całkowitą dowolność w doborze technologii per aplikacja, ale ma to swoją cenę. Wiedza zespołów, zarówno domenowa jak i techniczna, może ulec rozproszeniu, jeśli stack zanadto się rozrośnie (pogorszenie tzw. bus factor). Komplikuje się też kwestia współdzielenia komponentów oraz logiki między apkami w odmiennych technologiach.
Zwłaszcza ten ostatni argument przekonał nas, żeby na początku trzymać się ograniczonego stacku:
- React z TypeScript
- Redux (przy bardziej złożonych apkach)
- axios
- Material UI
- StyledComponents
- Jest, React Testing Library
Dzięki temu współdzielone części platformy można było wynieść do wewnętrznych bibliotek npm opartych o poniższe narzędzia:
- TSdx - setup biblioteki
- React
- zautomatyzowane wersjonowanie (semver, semantic release)
- Storybook
Ostatecznie nasza architektura frontendowa przyjęła następującą postać:
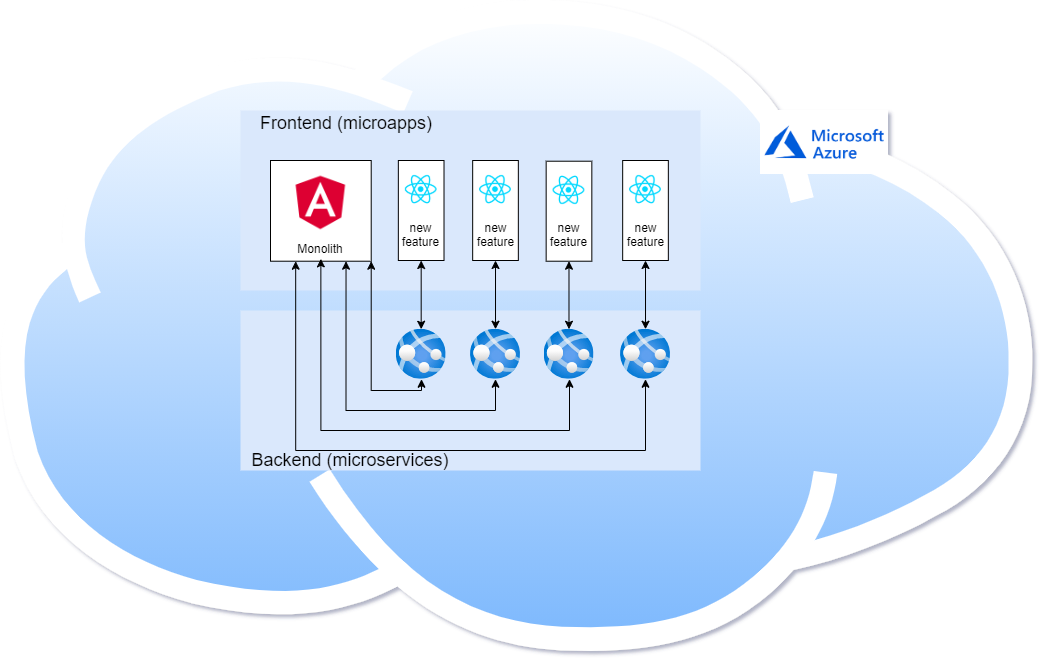
- monolityczna aplikacja w Angularze
- mikroapki w React (rozwój nowych funkcjonalności, migracja istniejących feature’ów)
- współdzielone komponenty i logika wyciągnięte do wewnętrznych bibliotek npm (TSdx, Storybook).
Co z tego wynikło
Dochodzimy do najciekawszej części naszej podróży sentymentalnej, czyli ujawnienia, które z powyższych decyzji i założeń okazały się trafione, a które skórkami banana, na których się spektakularnie rozłożyliśmy. A zwłaszcza jakich kwestii nie spostrzegliśmy, dopóki nas nie ugryzły.
Według nas mikroapki spełniły sporą część pokładanych w nich nadziei! W szczególności rozwój niedużych, odrębnych projektów okazał się szybki i przyjemny. Podział odpowiedzialności między zespołami zrobił się czysty, co dodatkowo przyspieszyło development.
Uwaga: powyższe dwa punkty są prawdziwe w momencie, kiedy mamy skonfigurowane, działające mikroapki z przyległościami (infrastruktura, współdzielone biblioteki). Dojście do takiego stanu rzeczy okazało się dość pracochłonne.
O ile poszczególne kroki procesu nie były bardzo skomplikowane, to było ich sporo: nauka nowego stacku frontendowego (React itd.) + konfiguracja tego stacku + tworzenie i wykorzystywanie bibliotek frontendowych + ogarnianie infrastruktury. Po dodaniu wszystkich okazało się, że złożoność procesu, a co za tym idzie czas developmentu, znacząco się zwiększyły.
Ogarnięcie infrastruktury to cały osobny temat. Mikroapki są w 100% niezależne - co oznacza również niezależną infrastrukturę per aplikacja. W naszym multifunkcyjnym zespole oznaczało to sporą inwestycję w wiedzę devopsową po stronie frontendowców
Z innych problemów, jak dotąd nie udało się nam całkowicie pozbyć duplikacji, nawet mimo wyciągnięcia sporej części współdzielonych komponentów i logiki do bibliotek. Oprócz duplikacji części kodu, w tym core’owych (np. tłumaczenia, obsługa http), męcząco powtarzalne okazały się też konfiguracje.
Zakres odpowiedzialności naszych aplikacji bazuje na podziale na feature’y, a nie na podziale domenowym. Na tę chwilę podział per feature nie przysparza nam większych kłopotów - ale na pewno jest to obszar, gdzie chcemy rozważyć zmiany w przyszłości.
1,5 roku później
Z perspektywy 1,5 roku spędzonego z nowym wariantem architektonicznym, siedząc na górce mikroapek i trzaskając radośnie kolejne, możemy spróbować odpowiedzieć sobie na kilka pytań:
Czy zdecydowalibyśmy się na mikroapki ponownie?
Tak! Z całą pewnością!
Co doceniamy najbardziej z perspektywy ostatniego 1,5 roku?
- kilkakrotnie już wspomnianą elastyczność mikroapek i jasny ownership, umożliwiający równoległy development
- wiedzę (!) wyniesioną z procesu: u nas de facto poskutkował on powstaniem sekcji frontopsowej (frontend + devops :))
- łatwą migrację feature’ów ze starej platformy (jeden feature = jedna mikroapka)
- prostotę rozwiązania - w porównaniu z wariantem zakładającym wiele mikrofrontendów per widok
Nasze sugestie dla chętnych do przejścia na mikroapki:
- odpowiedni timing - mikroapki są świetnym rozwiązaniem, kiedy chcecie mieć niezależny, równoległy development (czyt. sporą liczbę zespołów pracujących obok siebie równocześnie). Decyzja o ruszeniu w tym kierunku na wcześniejszym etapie może zakończyć się spowolnieniem developmentu w zamian za korzyści, których nie zrealizujemy przez dłuższy czas. Natomiast jeśli na horyzoncie, nawet odległym, pojawia się szybki wzrost produktu / firmy, na pewno warto rozważyć tę ścieżkę
- iteracyjne podejście do rozwiązywania problemów. Perfekcjonizm w migracji do MFE może zabić całe przedsięwzięcie, zanim na dobre się zacznie.
- ekstrakcja wspólnego kodu do wewnętrznych bibliotek
- automatyzacja (testy, CI/CD, tworzenie nowych aplikacji)
Bonus ? przepis na automatyczny semver
Na koniec chcemy podzielić się jednym z wielu fajnych rezultatów naszej podróży przez mikroapki i pokazać, jak można zautomatyzować publikację pakietów npm tak, aby cały proces był praktycznie przezroczysty dla developerów.
Największą odpowiedzialność za automatyzację bierze na siebie narzędzie semantic-release.
Zasada działania jest prosta! Semantic-release śledzi wszelkie zmiany na wskazanym branchu, następnie w oparciu o istniejącą wersję, oraz informacje zawarte w commit messages oblicza i publikuje kolejną wersję biblioteki. Wersjonowanie, jak wskazuje nazwa, oparte jest o standard Semantic Versioning.
Przykładowy plik konfiguracyjny mógłby wyglądać następująco:
// .releaserc
{
"repositoryUrl": "https://__USER__:__GIT_SECRET__@<REPO_URL>",
"branches": [
"master",
],
"plugins": [
"@semantic-release/commit-analyzer",
"@semantic-release/npm"
]
}
W powyższym przykładzie obserwujemy branch master, który jest częścią repozytorium o adresie wskazanym w atrybucie repositoryUrl.
W momencie, gdy na gałęzi nastąpi zmiana, do akcji wkracza plugin @semantic-release/commit-analyzer, który jest odpowiedzialny za obliczenie kolejnej wersji biblioteki, a ona sama zostanie opublikowana za sprawą drugiej wtyczki @semantic-release/npm .
Nasuwa się pytanie, skąd sematic-release wie, jaką wersję biblioteki ma opublikować? Tutaj z pomocą przychodzi ściśle określony format commit messages, na podstawie którego narzędzie jest w stanie obliczyć kolejną wersję biblioteki. Domyślną strukturą jest tzw. Angular Commit Message Format, który pozwala bardzo dokładnie sprecyzować typ releasu oraz skok wersji.
Całość wystarczy wrzucić do pipeline CI/CD, który mógłby wyglądać jak ten zaprezentowany poniżej:
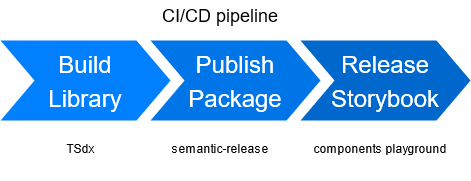
I to wszystko! Prawda? No nie do końca…
Wiadomo nie od dzisiaj, że najsłabszym ogniwem wszystkich automatycznych systemów jest człowiek korzystający z takiego systemu. W naszym przypadku będzie to developer, który nieraz zapomni jak taki format wygląda. Co więcej, może on nie znać wszystkich możliwości, które oferuje Angular Commit Message Format, tym samym nie wykorzystując w pełni potencjału jaki daje semantic-release.
Jak się przed tym obronić?
Dobrym pomysłem jest dodanie hooków do Gita, które mogłyby sprawdzić czy format commitów jest właściwy. By to osiągnąć, możemy skorzystać z biblioteki husky, która ładnie integruje się z procesem developmentu. Poniżej wycinek konfiguracji pliku package.json z odpowiadającym setupem:
// package.json
{
...,
"husky": {
"hooks": {
"commit-msg": "commitlint -E HUSKY_GIT_PARAMS"
}
},
...
}
Powyższa konfiguracja rejestruje hook gitowy na etapie commitowania wiadomości. Wiadomość jest oceniana przez plugin commitlint, który jest skonfigurowany tak, by wyłapać wszelkie pomyłki. Wraz z rozszerzeniem @commitlint/config-conventional, sama konfiguracja jest banalnie prosta:
// commitlint.config.js
module.exports = {extends: ['@commitlint/config-conventional']};
Ostatnim krokiem wartym rozważenia jest wyciągnięcie pomocnej dłoni do osób, które chciałby swobodnie korzystać możliwości oferowanych przez Angular Commit Message Format - do tego świetnie nada się interaktywne narzędzie CLI git-cz.
Dodajemy odpowiedni skrypt npm:
// package.json
{
"scripts": {
"commit": "npx git-cz" ,
...,
},
...
}
I wywołując odpowiednią komendę otrzymujemy interaktywne menu, pozwalające łatwo wybrać poprawny commit messages:
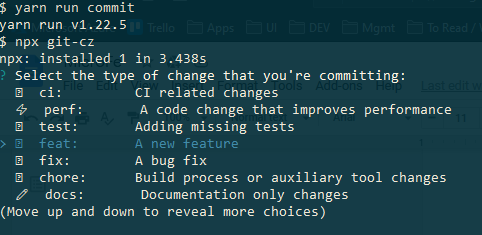
Opisany mechanizm ma wiele zalet w porównaniu do manualnego podbijania oraz publikowania wersji:
- nakład prac potrzebny do opublikowania paczki jest znikomy
- nie musimy przejmować się konfliktami wersji w przypadku, gdy wiele osób równocześnie pracuje nad biblioteką - analiza commitów zawsze wybierze właściwą wersję
- osoby rozwijające funkcjonalność biblioteki nie muszą znać specyfikacji wersjonowania paczek, gdyż mogą polegać na interaktywnym narzędziu, które zawsze podpowie najlepszą opcję
- jesteśmy chronieni przed pomyłkami - są wyłapywane już na etapie commitów
W CyberVadis stawiamy na jakość kodu i dzielenie się wiedzą. Jeśli macie dodatkowe pytania o mikroapki, automatyzację czy inne zagadnienia, zapraszamy do kontaktu!