Migracja DC/OS na Kubernetes

W tym artykule zostanie przedstawiony proces przejścia Applause z platformy DC/OS na Kubernetes. Jakie były przyczyny migracji?
Do tej pory Applause korzystał z DC/OS do zarządzania kontenerami. Następujące argumenty za przeprowadzeniem migracji na Kubernetes zadecydowały o dokonaniu tej operacji:
- Zarządzalny klaster Kubernetes u dostawców chmur- dzięki wykorzystaniu k8s dostarczanego przez dostawców chmur, część zadań związanych z zarządzaniem klastrem będzie mogła być pominięta.
- Integracja z większą liczbą dostawców chmur - poniekąd związane z poprzednim punktem, ale warto dodatkowo zwrócić uwagę, że wiele dostawców stworzyło gotowe integracje dla woluminów czy load balancerów. Dzięki temu w części przypadków możliwa jest zmiana dostawcy bez znaczących zmian w konfiguracji usług w klastrze. Dodatkowo łatwiejsza staje się implementacja stanowych kontenerów przy wykorzystaniu dostarczonych woluminów czy automatycznego skalowania przy użyciu Kubernetes Autoscaler.
- Kubernetes na komputerach roboczych deweloperów - Kubernetes może zostać w łatwy sposób zainstalowany przy wykorzystaniu narzędzi k3s/k3d czy minikube na komputerach deweloperów. Dzięki temu mają możliwość pracy oraz testów w środowisku zbliżonym do docelowego.
- Większa społeczność - wokół Kubernetes jest zgromadzona większa społeczność, co przekłada się na jego szybszy rozwój. Dostępne są też gotowe paczki do wdrażania usług. Można do tego wykorzystać na przykład Helm Charts.
Migracja do Kubernetes
Wszystkie kontenery, jakie Applause posiadał w klastrze DC/OS były bezstanowe. To zdecydowanie ułatwiło migrację. Stanowe serwisy znajdowały się poza klastrem. Dzięki temu możliwe było przepięcie usług między klastrami bez przestoju.
Metronome API
Częścią DC/OS jest Metronome - framework do zarządzania zadaniami. Pozwala on na wykonywanie i planowanie zadań uruchamianych w kontenerach Docker. Wiele z serwisów stworzonych w Applause wykorzystuje Metronome API do wykonywania periodycznych zadań.
Aby zminimalizować nakład pracy wymagany do przeprowadzenia migracji, zdecydowaliśmy się na napisanie własnego API kompatybilnego z Metronome API do obsługi zadań na Kubernetes. Szczęśliwie, Kubernetes posiada obiekty, które można wykorzystać podobnie do tych w Mesos. Problem można sprowadzić do stworzenia warstwy kompatybilności. Zdecydowaliśmy się stworzyć narzędzie Metronomikon, które to umożliwi.
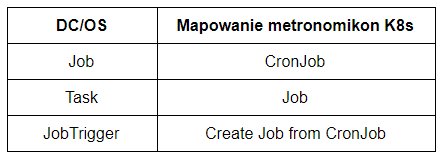
Metronome zadania mogą być jednorazowo zdefiniowane, a potem uruchamiane na żądanie. Kubernetes wymaga, aby każde zadanie miało zdefiniowany swój czas uruchomienia (w końcu jest to CronJob). Aby wykonanie odbyło się na Kubernetes, można skorzystać z 2 sposobów:
- Wykorzystać parametr
suspend, który zawiesi wykonywanie cronJob. W przypadku jednak gdy schedule zostanie zmieniony nie zadziała to zadowalająco w przypadku, gdy korzystamy z parametrustartingDeadlineSeconds. Jeśli od ostatniego czasu wywołania minęło mniej czasu niż wynosistartingDeadlineSeconds, zostanie wykonane zaległe zadanie, z czasu gdy CronJob był jeszcze zawieszony. - Ustawić
schedulena wartość, która nigdy nie wystąpi - na przykład Kubernetes uzna 30 lutego za poprawną datę.
Mając rozwiązany ten problem, można wykorzystać pole w CronJob spec.template do jednorazowego wykonania zadania.
Metronomikon na GitHubie.
Podejście do migracji
W wielu przypadkach nie da się uruchomić wszystkich kontenerów na nowym klastrze, aby od razu wszystkie działały. Mimo że są to kontenery, nadal może występować konfiguracja specyficzna dla danego klastra (na przykład sztywna adresacja, wykorzystanie specyficznych zmiennych środowiskowych, lub pewne zaszłości historyczne). Wystartowanie wszystkich jednocześnie spowoduje że kontenery, które są poprawnie skonfigurowane, nie wystartują, bo są zależne od tych które nie działają. Można pojedynczo zajmować się każdym kontenerem po przeniesieniu, ale w sytuacji gdy wiele osób pracuje nad migracją, takie działania mogą spowodować, że wiele osób będzie pracowało nad podobnymi problemami. Innymi rozwiązaniami mogą być:
- Przygotowanie drzewa zależności między usługami - przy jego użyciu można stwierdzić które serwisy mogą zostać przeniesione w pierwszej kolejności, a to pozwoli na pracę wielu osób nad migracją;
- Wykorzystanie serwisów na starym klastrze przez serwisy tworzone na nowym. Ten sposób nie zawsze jest możliwy - wymaganiem jest między innymi wspólna sieć wewnętrzna dla obu klastrów.
W czasie migracji użyliśmy drugiego podejścia. Ułatwiło je nam to, że do tej pory wykorzystywany był Linkerd.
Linkerd jest usługą service mesh, w skrócie, działa jak przezroczyste proxy pomiędzy kontenerami. Wykorzystanie go pozwala na łatwiejsze zarządzanie ruchem między usługami, zbieranie metryk, a także szyfrowanie ruchu sieciowego.
W tym przypadku, na każdym hoście DC/OS i Kubernetes znajdował się kontener Linkerd, który odpowiadał za kierowanie ruchu przychodzącego do odpowiedniego kontenera na hoście, a także kierował ruch wychodzący - ruch z kontenera trafiał do Linkerd znajdującego się na tym samym hoście, następnie Linkerd wysyła zapytanie do Namerd o adres IP hosta docelowego, na którym znajduje się żądany kontener. Ruch trafia do Linkerd na hoście docelowym w klastrze Kubernetes, który kieruje go już do odpowiedniego kontenera. Linkerd, w zależności od zastosowania, działa w warstwie 4 lub 7. Należy umożliwić routowanie ruchu pomiędzy sieciami wewnętrznymi obu klastrów.
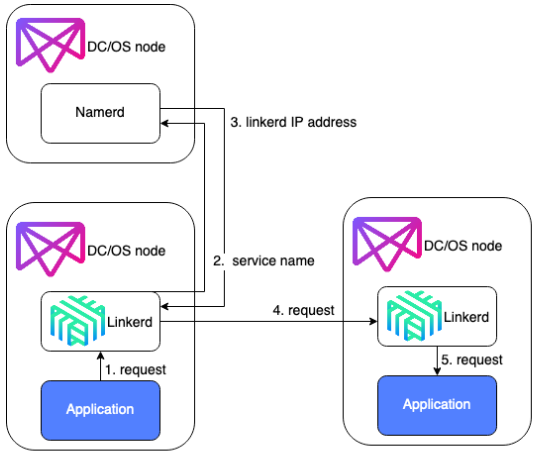 Ruch między kontenerami w klastrze DC/OS
Ruch między kontenerami w klastrze DC/OS
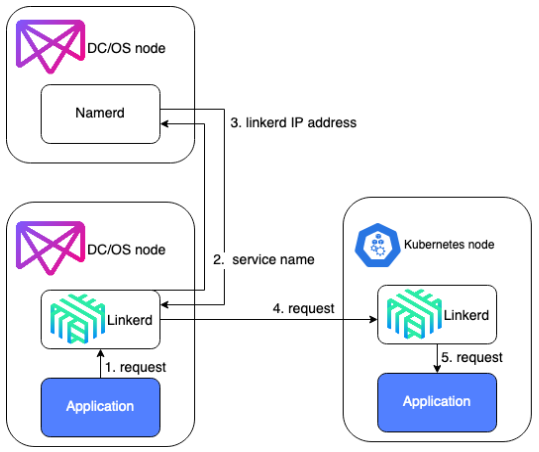 Żądanie z aplikacji w klastrze DC/OS do aplikacji w klastrze k8s
Żądanie z aplikacji w klastrze DC/OS do aplikacji w klastrze k8s
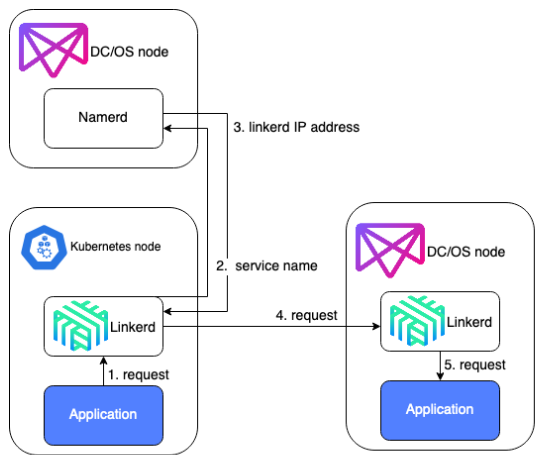 Żądanie z aplikacji w klastrze k8s do aplikacji w klastrze DC/OS
Żądanie z aplikacji w klastrze k8s do aplikacji w klastrze DC/OS
Generowanie konfiguracji
Do wdrażania aplikacji na mesos Applause wykorzystuje własne narzędzie deploy-config-generator. Umożliwia ono generowanie z pliku konfiguracyjnego o własnej strukturze plików konfiguracyjnych dla innych usług, w tym właśnie Marathon i Metronome oraz Kongfig.
Dzięki wykorzystaniu tego narzędzia, możliwe było stworzenie wtyczki generującej pliki konfiguracyjne dla Kubernetes. Ułatwiło to migrację, gdyż nie było potrzeby tworzenia nowych plików z konfiguracją każdego serwisu.
Deploy-config-generator na GitHubie.
Podsumowanie
W Applause migrację platformy do orkiestracji kontenerów udało się dokonać bez przestojów. W całym procesie udało się zminimalizować zaangażowanie deweloperów serwisów w proces migracji. Użycie generatora konfiguracji zdecydowanie ułatwiło cały proces. Dzięki wykorzystaniu Linkerd przy migracji serwisów na nowy klaster, możliwa była praca wielu członków zespołu równolegle. Skróciło to czas potrzebny na migrację.