Mechanizm Change Data Capture z wykorzystaniem debezium

CDC to mechanizm przechwytywania zmian danych (ang. Change Data Capture), jak sama nazwa wskazuje, służy do efektywnego śledzenia modyfikacji danych przechowywanych w bazie danych.
Zastosowań tego mechanizmu może być bardzo wiele. Najczęstsze przykłady to:
- Hurtowanie danych.
- Replikacja danych pomiędzy systemami (np.: odwzorowanie zmian danych klienta w systemie źródłowym, które musi zostać rozpropagowane do innych systemów, które mają zreplikowane te dane).
- Transformacja danych (na podstawie danych wprowadzanych lub zmienianych w relacyjnej bazie danych można budować bardziej efektywne struktury danych np.: indeksy ElasticSearch zoptymalizowane pod kątem wyszukiwania).
Wzorzec ten może być realizowany na kilka sposobów:
- Cykliczne sprawdzanie zawartości poszczególnych tabel – tzw. pooling.
- Wykrywanie zmian za pomocą triggerów.
- Wykorzystanie mechanizmów baz danych (WAL, Redo Logs, itd.)
Oczywiście najefektywniejsza jest ostatnia metoda, gdyż w jej przypadku polegamy na natywnym dla danej bazy i wspieranym przez jej dostawcę mechanizmie. Wydaje się też najbardziej wiarygodna i generująca najmniejsze opóźnienia.
Mechanizm ten jest wspierany przez wszystkie popularne bazy relacyjne tj. MySQL, PostgreSQL, Oracle czy SQL Server. W przypadku bazy danych Oracle 12, CDC realizowane jest w oparciu o rozwiązanie Golden Gate, które dostępne jest dopiero w wersji Enterprise.
W tym artykule skonfigurujemy i wypróbujemy działanie CDC dla bazy danych PostgreSQL z wykorzystaniem systemu Debezium.
Debezium
Debezium to zestaw modułów do przechwytywania zmian w bazach danych i ich propagowania. Rejestruje on wszystkie zmiany danych, na poziomie wierszy tabel i publikuje je jako strumień danych.
Aplikacje, które chcą skorzystać z tych danych, nasłuchują na tych strumieniach, otrzymując w ten sposób informacje o wszystkich zmianach danych w źródłowej bazie. Są one przekazywane w kolejności w jakiej one wystąpiły.
Do dzieła!
Utworzymy teraz przykładowa bazę danych z wykorzystaniem silnika PostgreSQL i uruchomimy dla niej przechwytywanie zmian. W tym celu wykorzystamy następujące mechanizmy:
- Debezium– system, do przechwytywania zmian w bazie danych, pisałem o nim przed chwilą
- Apache Kafka– w największym skrócie, to platforma przesyłania strumieniowego, umożliwiająca przekazywanie ogromnych ilości danych w modelu publish-subscribe.
- Kafka Connect– jak sama nazwa wskazuje, moduł służący do definiowania łączników pomiędzy różnymi systemami (w naszym przypadku bazami danych) a systemem Kafka.
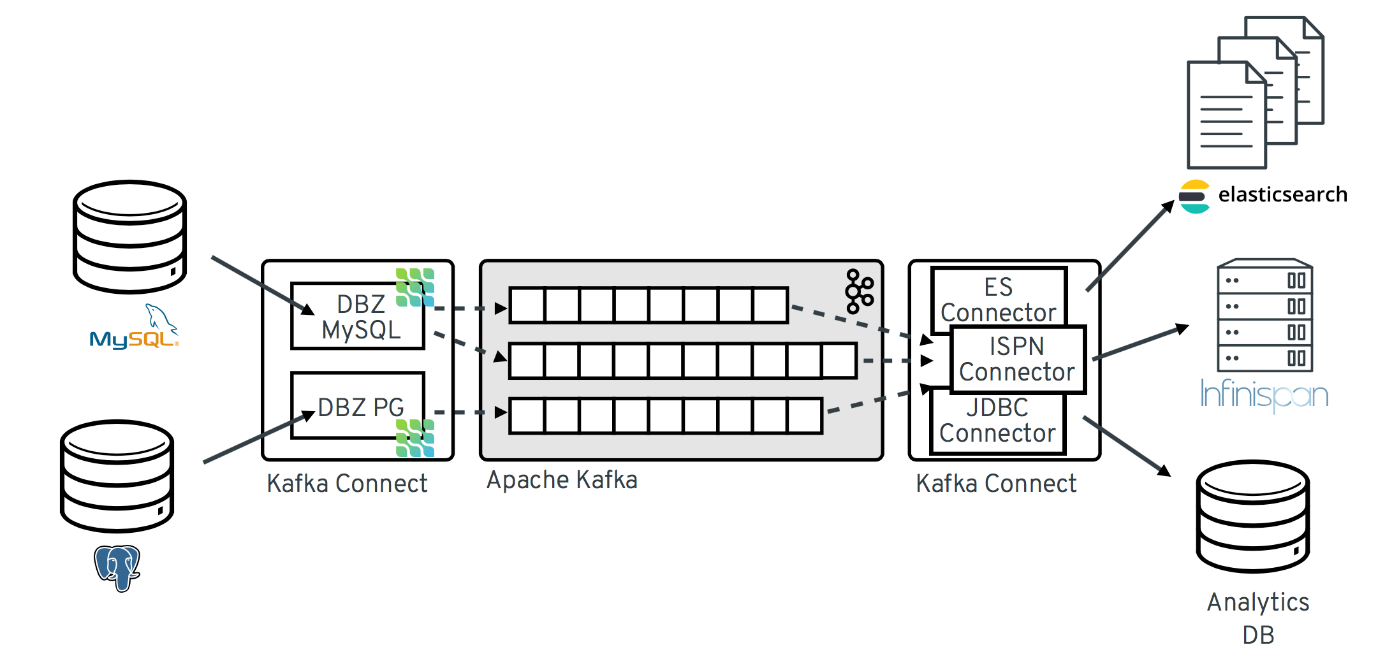 Rysunek 1 Schemat rozwiązania (źródło: debezium.io)
Rysunek 1 Schemat rozwiązania (źródło: debezium.io)
Nasze rozwiązanie uruchomimy w oparciu o dostępne obrazu dockerowe. W tym celu przygotujemy plik docker-compose.yml, który umożliwi nam ich sprawną obsługę.
Zaczniemy od bazy danych. Skorzystamy z obrazu debezium/postgres:12-alpine. Jest to najnowsza wersja bazy Postgres, której konfiguracja została wzbogacona o elementy konieczne do połączenia do debezium. W szczególności chodzi tu o plugin wal2json, który transformuje zmiany bazy danych do formatu json.
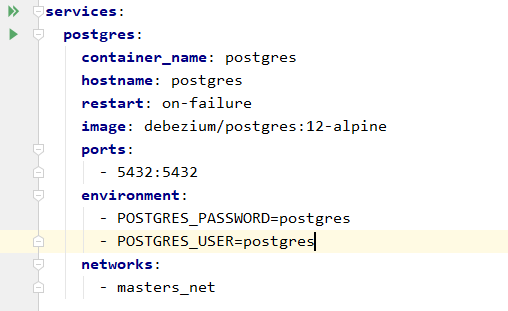 Rysunek 2 Uruchomienie postgresql z docker-compose
Rysunek 2 Uruchomienie postgresql z docker-compose
Po uruchomieniu kontenera, założymy nowego użytkownika (rolę), utworzymy bazę danych i przykładową tabelę.
 Pragnę zwrócić tu uwagę na rolę REPLICATION, która jest wymagana w procesie pobierania zmian danych.
Pragnę zwrócić tu uwagę na rolę REPLICATION, która jest wymagana w procesie pobierania zmian danych.
Utworzymy teraz przykładową tabelę o nazwie USERS.

Gdy mamy uruchomioną bazę danych, kolejnym elementem będzie Kafka wraz z systemem Zookeeper, który zarządza konfiguracją Kafka.
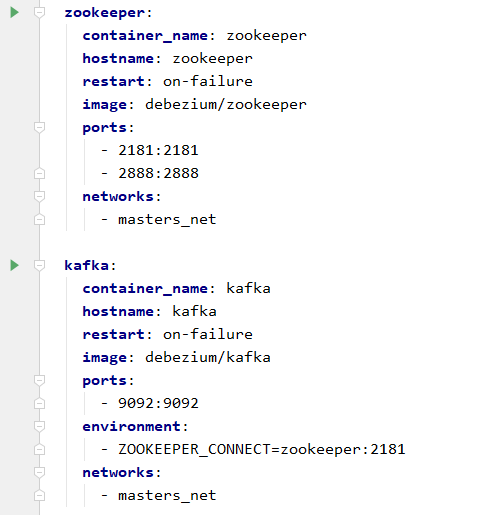
Tak jak poprzednio, są to obrazy prekonfigurowane do pracy z CDC.
Ostatnim elementem jest moduł kafka connect, a dokładniej konektor debezium, służący do monitorowania bazy danych.
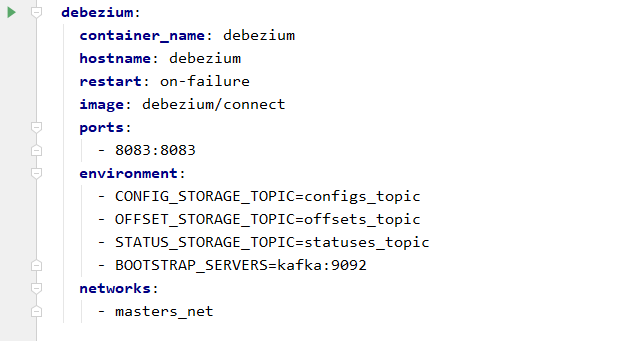
Po uruchomieniu wszystkich tych elementów pozostaje wprowadzić konfigurację, która wskaże konektorowi szczegóły monitorowanej bazy. Konfigurację przekazujemy za pomocą wywołania funkcji REST, udostępnianej przez debezium.
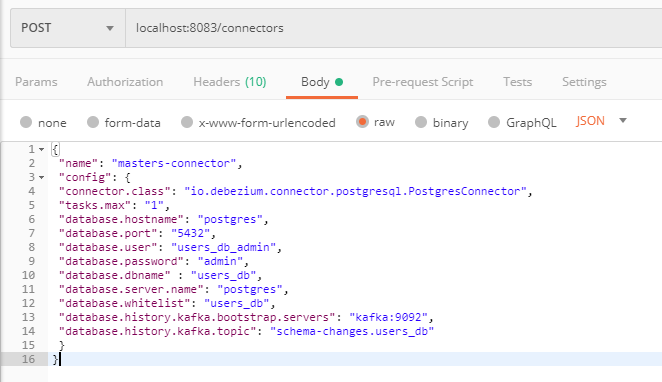
Jak widzimy, przekazujemy tutaj szczegóły bazy danych i użytkownika. Od tego momentu zmiany danych są monitorowane. Każda modyfikacja danych w tabeli, powoduje publikację informacji, w formacie json, gdyż taki plugin został użyty, na topicu odpowiadającym tej tabeli.
Aby to zobaczyć, uruchomimy jeszcze jedną aplikację, a mianowicie prostego klienta, który wyświetli nam informacje publikowane na określonym topicu. Użyty zostanie klient zawarty w systemie kafka. Nazwa topica, który nas interesuje, to postgres.public.users (nazwa serwera, schemat i nazwa tabeli).
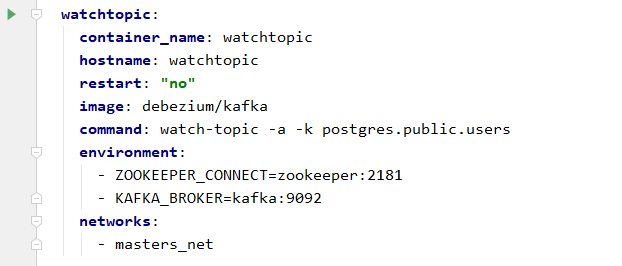
Po uruchomieniu tego polecenia, na konsoli drukuje on informacje publikowane na skonfigurowanym topicu. Dodamy nowy rekord do tabeli USERS:
INSERT INTO USERS (FIRST_NAME, LAST_NAME, PHONE)
VALUES ('Jan', 'Kowalski', '178888888');
Po zatwierdzeniu transakcji zobaczymy, że natychmiast na topicu publikowany jest obiekt json, który zawiera m.in. dane wstawiane do tabeli:

Jak widzimy mechanizm działa bez zarzutu, a my mamy uruchomione wszystkie elementy potrzebne do rozpoczęcia przygody z CDC.
Następne kroki
Informacja opublikowana na topicu Kafka może być odebrana przez różnego rodzaju konsumentów. Może to być np.: baza danych EalsticSearch, która zaktualizuje swój indeks, umożliwiając efektywne wyszukiwanie danych użytkowników. Może to też być dowolna aplikacja SpringBoot, wykorzystująca Kafka Streams.
O autorach
Artykuł przygotowali: Dobromir Matusiewicz, Ekspert Architekt i Maciej Hadam, Ekspert Projektant. Chłopaki codziennie sprawiają, że niemożliwe staje się możliwe.