Llama 3 prześciga... większość otwartych LLM-ów

Meta ogłosiła wydanie kolejnej wersji swojego popularnego już LLM-a - Llama 3. Przedstawia go jako najbardziej wydajny obecnie dostępny otwarty model językowy.
W dniu premiery Meta wypuściła na rynek dwa warianty modelu: 8B i 70B. Na razie dostępne są tylko odpowiedzi tekstowe, ale w trakcie trenowania jest model 400B.
Właściwości Llama 3
Według opublikowanego na blogu Mety posta, Llama 3 prezentuje się obiecująco pod wieloma względami. Model wykazuje większą różnorodność w odpowiedziach na pytania, rzadziej odmawia udzielenia odpowiedzi oraz ma lepszą od Llama 2 zdolność do wnioskowania.
Ta wersja ma też dokładniej rozumieć instrukcje oraz lepiej radzić sobie z pisaniem kodu niż poprzednia. Model Llama 3 może uwzględniać kontekst o długości do 8 tysięcy tokenów. To progres względem poprzedniej wersji, gdzie maksymalny kontekst wynosił 4 tysiące tokenów.
Modele konkurujące z Llamą 8B mają często podobną długość kontekstu, natomiast te konkurujące z Llama 70B obsługują dłuższy kontekst, więc nie we wszystkim modele od Mety są najlepsze.
Llama 3 to modele tekstowe, które zdecydowanie najlepiej radzą sobie w języku angielskim.
Możliwości modelu
Wg testów porównawnych Llama 3 wyprzedza wiele innych modeli sztucznej inteligencji, w tym Gemini od Google oraz Mistral 7B i Claude 3 od Anthropic.
Model 8B konkuruje z modelami o podobnej wielkości, zapewniając lepsze rezultaty w wielu zadaniach. Wariant 70B modelu Llama 3 jest konkurencyjny względem wielu komercyjnych modeli, takich jak Gemini Pro czy Claude Sonnet. Na potwierdzenie tego Meta przygotowała następujące benchmarki:
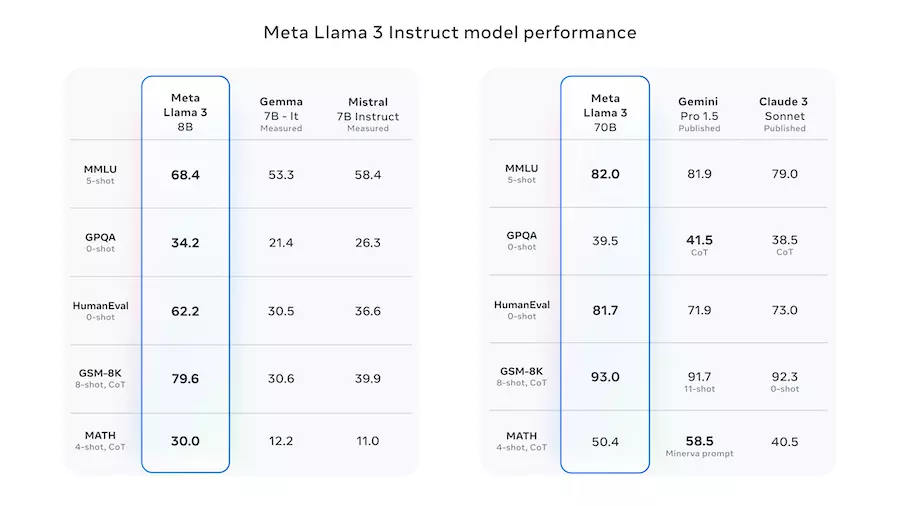
[źródło: https://ai.meta.com/blog/meta-llama-3/]
Jak widać model 8B radzi sobie znakomicie w przedstawionych benchmarkach. Natomiast wersja 70B jest bardzo porównywalna z konkurencją.
Co więcej Meta stworzyła własny benchmark, gdzie odpowiedź była oceniana przez ludzi:
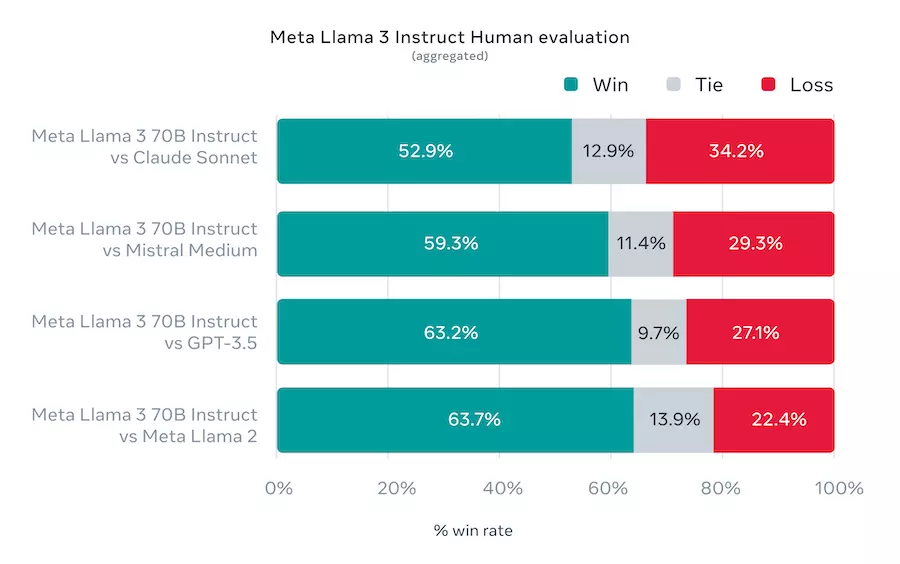
[źródło: https://ai.meta.com/blog/meta-llama-3/]
W ten sposób sugerują, że Llama 3 70B jest lepsza niż GPT 3.5.
Proces rozwoju Llama 3
Jak zawsze pada pytanie "na jakich danych był trenowany model". Jak zawsze też oficjalna odpowiedź brzmi "na publicznie dostępnych źródłach o wysokiej jakości". W sumie do treningu wykorzystano 15 miliardów tokenów. 95% tych danych była w języku angielskim, dlatego też model nie radzi sobie za dobrze w innych językach. Meta twierdzi, że sporo czasu spędzili na filtrowaniu danych wejściowych, by znaleźć odpowiedni balans, jak chodzi o ich kompozycje. Dzięki temu Llama 3 ma sobie radzić dobrze zarówno z podawaniem faktów, ale też np. z kodowaniem.
Kluczowym elementem w doskonaleniu modelu była zmiana tokenizera oraz dostosowanie treningu w taki sposób, aby mechanizm uwagi skupiał się na jednym temacie. To pozwoliło uzyskać lepsze wyniki w zadaniach generowania tekstu.
Bezpieczeństwo i ocena ludzka
Jednym z istotnych aspektów nowego modelu jest jego bezpieczeństwo. Meta poświęciła sporo uwagi opisowi mechanizmów bezpieczeństwa wewnątrz modelu, szczególnie wrażliwych na tematy związane z biologią, chemią oraz cyberbezpieczeństwem. Model ma oceniać zarówno wejście, jak i wyjście pod względem bezpieczeństwa.
Firma stworzyła też nowy zestaw danych do oceny modelu przez ludzi, emulując scenariusze rzeczywistego użytkowania Llama 3. W przypadku tej oceny, model osiągnął lepsze wyniki niż konkurencyjne modele, w tym GPT-3.5 od OpenAI.
Meta w swoich materiałach zachęca do budowania aplikacji w oparciu o nowe modele, twierdząc, że właśnie dzięki nowym zabezpieczeniom będzie to najbardziej odpowiednia podstawa w wielu przypadkach.
Co dalej?
Choć Llama 3 została już opublikowana, to sporo jeszcze brakuje. Przede wszystkim wraz z raportem ogólny, nie został opublikowany szczegółowy raport techniczny dotyczący modeli. Ma zostać udostępniony w ciągu następnych kilku miesięcy.
Bardziej imponująco zapowiadają się kolejene zapowiedzi firmy. Llama 3 jest obecnie modelem wyłącznie tekstowym, ale ma się to zmienić w najbliższej przyszłości. Modele mają stać się multimodalne - jeszcze nie wiemy, czy w pierwszej kolejności Meta skupi się na obrazie czy dźwięku.
Rodzina Llama 3 ma zostać uzupełniona o duży model o wielkości 400B parametrów. Ta wersja jest obecnie trenowana i Meta podzieliła się wstępnymi wynikami benchmarków. Nie są porównywane wprost do żadnego z istniejących modeli, ale są one w okolicach tych, uzyskanych przez GPT 4 w momencie premiery.
Jeżeli budujesz aplikacji AI, to dość łatwo będzie Ci przetestować nowy model, bo jest dostępny dosłownie wszędzie. Można go już teraz uruchomić u wszystkich ważniejszych dostawców chmury. Jest dostępny na Kaggle czy HuggingFace. Można też poprosić o dostęp do modelu prostu u Mety pod tym linkiem.