Kubernetes – cienie i blaski „infrastruktury” do przetwarzania danych

W dzisiejszym świecie mamy dostęp do wielu różnych technologii wspomagających przetwarzanie wielkich wolumenów danych. Wielu słyszało takie nazwy, jak BigQuery, Athena, Spark, Flink, Beam, DataFlow, Kinesis i tak można bardzo długo wymieniać… Większość chmur oferuje powyższe technologie w przeróżnych swoich produktach tak zwanych „managed services”. Użytkownik klika i używa „Pay for use”. Więc o czym ten wpis?
Gdzie jest miejsce dla kubernetesa w świecie „silników” służących do przetwarzania wielkich wolumenów danych?
Jednym z trendów na świecie od kilku dobrych lat jest „ucieczka do chmury”. Oznacza to, że wszystko, co obecnie robimy on prem - jest traktowane jako legacy. Dostawcy chmur prześcigają się w oferowaniu produktów, które ułatwiają nam zadanie. Storage, Security, Compute, DataVirtualization itd.
W trakcie takiej migracji musimy odpowiedzieć sobie na różne pytania. Jednym z pytań jest koszt operacyjny, jaki poniesiemy po migracji oraz jaki będzie ewentualny koszt wycofania się z chmury (lub zastąpienia inną). I dochodzimy do punktu vendor lock. Jednym z pryncypiów nowoczesnej architektury powinna być modularność oraz zastępowalność komponentów.
Kubernetes umożliwia spełniania powyższych pryncypiów. W T-Mobile Polska architekturę nowoczesnego data lake house oparliśmy w całości o kubenetesa. Z ciężkiego i scentralizowanego DWH zmierzamy ku lekkim i zwinnym serwisom. Kluczowym w całej architekturze mikro serwisowej elemencie jest komunikacja.
Postawiliśmy na komunikację w opartą o bazę dokumentową MongoDB oraz ich rozwiązaniu Mongo Streams. Każdy serwis, który miał być wpięty, musiał komunikować się z szyną komunikatów (Event Hub). Komunikacja jest sercem i mózgiem całego datalake house.
Jak obecnie to robimy w TMPL przy pomocy kubernetesa.
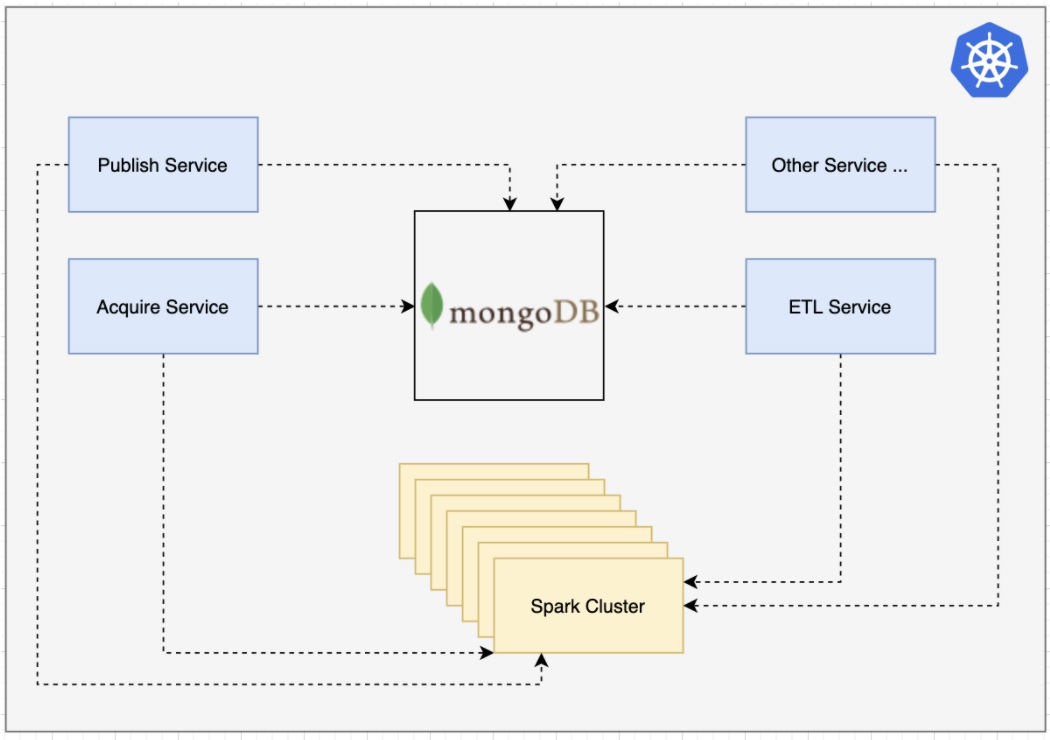
Tak więc naszym silnikiem wykonawczym (compute) jest spark. Sparka zainstalowaliśmy w najnowszej dostępnej na dany dzień wersji (3.1.2) w trybie standalone z dynamiczną alokacją.
Dynamiczna alokacja zasobów pozwala na lepszą utylizację i priorytetyzację zadań na klastrze.
Serwisy, które wykonują logikę biznesową — są napisane w Springu (Java 11). Wszystkie serwisy napisane są w taki sposób, aby skalować się horyzontalnie.
Wyróżniamy kilka grup serwisów:
- Acquire – serwisy, które bezpośrednio łączą się z systemami zewnętrznymi,
- Publish – serwisy publikujące dane. Np. na S3, do SnowFlake etc.,
- ETL Service – serwisy manipulujące dane w sparku,
- Inne – Data Catalog, DataGovernance etc.
Do tego jako EventHub korzystamy z Mongo. Co jest ciekawe jeszcze na tym obrazku?
Serwisy nie komunikują się ze sobą bezpośrednio. Dzięki temu zachowujemy pełną autonomię i niezależność serwisów.
„Benefity” powyższej architektury:
- IaaC – Infrastructure as a code, cała infrastruktura opisana w YAML,
- CaaC – Configuration as a code, pozwala na to z unifikowana komunikacja,
- Uruchomiania tego samego przetwarzania na wielu silnikach,
- Brak
cloud lock– każdy provider chmurowy dostarcza kubernetesa, Pay for use– płacimy tak naprawdę tylko za infrastrukturę,- Proste „wpinanie” nowych serwisów.
Wady rozwiązania:
- Cała architektura jest oparta na niezależnej komunikacji. Co w tym momencie robi ją „single point of failure”
- Narzut zasobowy na kubernetesa, przez serwisy. Każdy serwis musi mieć określony request i limit
- Należy stworzyć odpowiedni
distribute tracingimonitoring, dzięki któremu w łatwy sposób zdiagnozujemy problemy w „znikających komunikatach” oraz w monitorowaniu performance’u