Konfiguracja Jenkinsa z użyciem dynamicznych agentów na Kubernetesie

Większość z nas (programistów, administratorów, devopsów, testerów) korzysta z Jenkinsa każdego dnia. Czasem jest to znajomość z konieczności, ale jednak nic lepszego jeszcze nie wynaleziono. Dobra praktyka mówi że pipeline’y powinny być uruchamiane na agentach jenkinsa zamiast na masterze, ale takiego agenta trzeba odpowiednio wcześniej przygotować, aby mógł uruchamiać nasze zadania. Tutaj zawsze poruszamy kwestie: wymaganych narzędzi, wymiarowania i skalowania. Przy paru nodach to jeszcze nie problem, ale wraz z adopcją Jenkinsa, ilość nodów oraz wymaganej konfiguracji na nich, zaczyna masowo przyrastać. Wtedy zaczynamy się zastanawiać czy można coś zrobić lepiej.
Droga do perfekcji (?)
Od samego początku mojej pracy z Jenkinsem chciałem zarządzać tym rozwiązaniem przez kod i stworzyć rozwiązanie skalowalne. Stąd każdy agent był konfigurowany automatycznie do pracy z Jenkinsem przez Chefa (włącznie z podpięciem do mastera) i umożliwiało to wprowadzenie zmian konfiguracyjnych na całej populacji agentów za jednym kliknięciem.
Dodawanie/usuwanie agentów również było proste, ale nie działo się automatycznie, brakowało autoskalowania. A utrzymywanie np. 40 takich serwerów po to, aby były wykorzystywane raz w miesiącu przy okazji nowej „wersji”, nie jest oszczędnością zasobów.
Na szczęście pojawił się docker i docker plugin do Jenkinsa, co umożliwiło:
- tworzenie efemerycznych agentów,
- wykorzystanie zestawu narzędzi wbudowanego w obraz, korzystasz z mavena – wybierasz obraz mavena, potrzebujesz node.js – masz node.js
- teoretycznie nieograniczona skalowalność
Rozwiązanie to na pierwszy rzut oka adresuje większość wyzwań, które mieliśmy ze standardowymi node’ami. Jednak po dłuższym zastanowieniu się, zmiana ta dotyka tylko sposobu uruchomienia, ale nie adresuje wyzwań infrastrukturalnych – przecież ten docker musi być na czymś zainstalowany. I tak znowu musimy wyskalować odpowiednią ilość serwerów i zainstalować na nich dockera…
A gdyby tak istniała możliwość uruchamiania agentów dockerowych, ale bez serwera pod nim - po prostu „gdzieś” ?
I w tym przypadku ostatnimi czasy pojawiła się nowa technologia – Kubernetes. Oczywiście nie mamy tutaj do czynienia z uruchamianiem kontenerów w oderwaniu od fizycznego serwera, ale z naszego punktu widzenia traktujemy to bardziej jako usługę, gdzie interesuje nas tylko kwestia „wykupienia” odpowiednich zasobów. Co się z tym wiąże:
- W momencie braku zadań nie istnieją żadne nody agenta
- Agenci są tworzeni ad-hoc, zależnie od ilości zadań
- Wymuszamy efemeryczność środowiska
- Konfigurację agenta utrzymujemy jako kod w Dockerfile
Wygląda to bardzo dobrze, przystąpmy więc do konfiguracji.
Kubernetes plugin for Jenkins
*w tym artykule wykorzystamy Jenkins w wersji 2.222.4 , oraz Kubernetes plugin for Jenkins w wersji 1.26.1
Instalacja pluginu
Wymagany plugin możemy zainstalować przez domyślny Plugin Manager, co nie jest trudne, więc pozwolę sobie wskazać jedynie, o który plugin konkretnie chodzi.
Konfiguracja
W panelu Manage Jenkins -> Manage nodes and Clouds, a następnie z bocznego panelu wybieramy Configure Clouds
Dodajemy nową chmurę o typie Kubernetes i uzupełniamy podstawowe informacje, jak podłączyć się do naszego środowiska k8s.
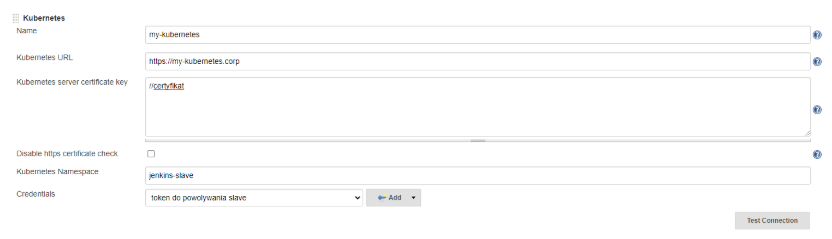
Odpowiednie opcje odpowiadają za:
Name: nasza przyjazna nazwa klastra
Kubernetes URL: Adres API kubernetesa
Kubernetes server certificate key: certyfikat API
Kubernetes Namespace: domyślny namespace w którym będą powoływane pody
Credentials: token
Po wybraniu Test Connection powinniście dostać komunikat: Connection test succesful.
Połowa droga za nami, teraz kolej na skonfigurowanie jak ma wyglądać nasz slave-pod. Mamy do wyboru 2 opcję:
- definicja podów w konfiguracji pluginu
- definicja podów jako kod w Jenkinsfile
Definicja podów w konfiguracji pluginu
W sekcji Pod Templates dodajemy definicję nowego poda:
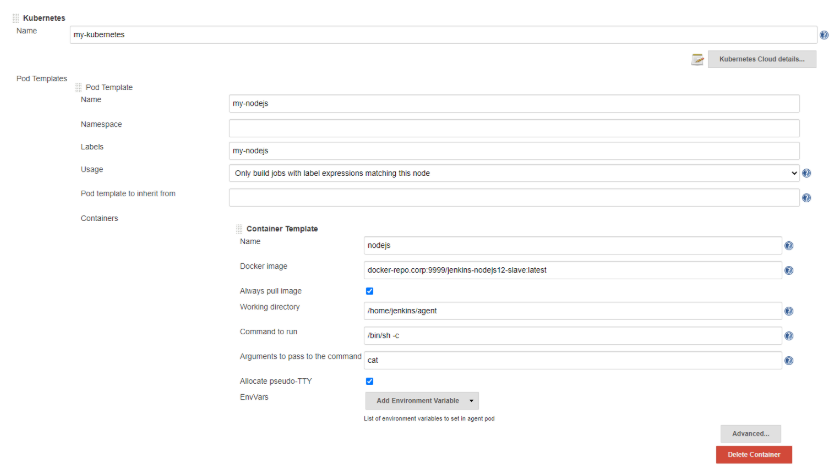
W naszym przypadku będzie to node.js. Ważne by entrypoint tego kontenera wskazywał na long running proces, na przykład przez ustawienie polecenia cat oraz włączenie pseudo TTY jak w przykładzie. Zapisujemy konfigurację.
Dla skorzystania z naszego poda, wykorzystamy prosty declarative pipeline i dyrektywę label:
pipeline {
agent {
label 'my-nodejs' // nazwa labela który nadaliśmy agentowi
}
stages {
stage('Run nodejs') {
steps {
container('nodejs') { // Uwaga, musimy wskazać na którym kontenerze ma zostać wykonane zadanie
sh 'node --version'
}
}
}
}
}
Uruchomienie pipeline kończy się sukcesem !
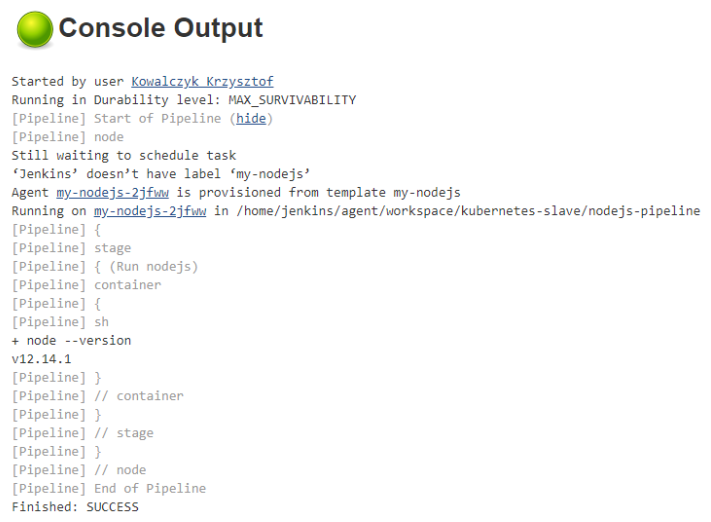
Zapewne zwróciliście uwagę że w kodzie pojawiła się dodatkowa dyrektywa container. Wyjaśnię dlaczego. Przy połączeniu do mastera Jenkinsa wykorzystywane jest połączenie jnlp. W praktyce oznacza to że nasz pod musi mieć zainstalowanego agenta jnlp oraz być odpowiednio skonfigurowany, aby nawiązać połączenie.
Jak więc tego dokonać ? W zasadzie nie musimy, gdyż Jenkins automatycznie do definicji poda dodaje dodatkowy kontener z jnlp. Ma to jednak swoją ciemną stronę. Jak dobrze wiemy, w ramach jednego poda Kubernetesa, możemy mieć więcej niż jeden działający kontener. Tym samym możemy zdefiniować sobie takiego agenta który będzie miał w sobie wiele kontenerów np. nodejs i maven (a w zasadzie to trzy, bo jeszcze jnlp) i wykorzystywać je w pipeline naprzemiennie.
Jednakże w jakiś sposób musimy wskazać Jenkinsowi z którego kontenera chcemy korzystać, gdyż jeśli tego nie zrobimy, zadania będą domyślnie wykonywane na kontenerze jnlp. Dotyczy to również sytuacji, w której mamy tylko kontener z node.js oraz jnlp. Stąd w moim prostym Jenkinsfile pojawia się dyrektywa container, która wskazuje kontener z nodejs.
Definicja podów jako kod w Jenkinsfile
Metoda ta pozwala uniezależnić się od definicji podów na instancji Jenkinsa i jest znacznie bardziej elastyczna, jeśli chodzi o parametryzację podów pod konkretne joby. Całą definicję poda umieszczamy w Jenkinsfile:
pipeline {
agent {
kubernetes {
cloud 'my-kubernetes' // nazwa wcześniej skonfigurowanej instancji kubernetesa
yaml '''
apiVersion: v1
kind: Pod
spec:
containers:
- name: nodejs
image: docker-repo.corp:9999/jenkins-nodejs12-slave:latest
command:
- cat
tty: true
'''
}
}
stages {
stage('Run Nodejs') {
steps {
container('nodejs'){
sh 'node --version'
}
}
}
}
}
Można ją podać w formacie yaml, zgodnie z definicją obiektu Kubernetesa, co pozwala na konfigurację wszystkich parametrów poda.
Podejście to sprawdzi się w przypadku, gdy nasze joby wymagają różnie sparametryzowanych agentów, a my nie chcemy ich definiować globalnie (co wymaga również uprawnień administratora jenkinsa).
Dodatkowo Pod Templates umożliwiają dziedziczenie ustawień, co może być przydatną opcją, gdy chcemy mieć bazę, na której będziemy się opierać przy definiowaniu nowych podów.
Podsumowanie
Wykorzystanie Kubernetes plugin for Jenkins daje ogrom możliwości. Nody agentów są powoływane „na żądanie” kiedy są potrzebne, nie trzeba ich utrzymywać, a sama konfiguracja sprowadza się do przygotowania odpowiedniego obrazu. Skalowanie jest teoretycznie nieograniczone, a praktycznie ograniczone jedynie przez dostępne zasoby Kubernetesa. Zawsze jednak mamy tą przewagę nad zwykłym dockerem, że nie polegamy na jednym hoście, ale mamy do czynienia z całym klastrem Kubernetesa, który powinien zapewnić nam wysoką dostępność i niezawodność. Mamy gwarancję efemeryczności workspace – każdy build odbywa się w identycznych warunkach, tym samym gwarantuje powtarzalność.
Nie ma jednak rozwiązań idealnych i tutaj trzeba zaznaczyć że wykorzystanie wyżej opisanego mechanizmu ma parę wad. Pierwszą z nich jest wydajność. Dochodzi nam spory narzut czasowy potrzebny na powołanie poda, a następnie na aktywację agenta jnlp – jest to od parunastu sekund, aż do paru minut (np. kiedy wymagane jest pobranie dużego obrazu kontenera).
Kolejną jest… efemeryczność (którą wcześniej podałem jako plus). Domyślnie zawsze startujemy z nowym czystym systemem, więc np. w procesie budowania aplikacji przez maven, nie możemy skorzystać z pobranych wcześniej zależności i musimy je każdorazowo ściągać (o ile w tym celu nie skonfigurujemy persystentnego volumenu na dane – co jednak nie zawsze wchodzi technicznie w grę). Ostatecznie przez to, że pod po wykonaniu zadania znika (ustawienie domyślne, można zmienić ale wtedy nieużywane pody pozostają i to administrator kubernetesa odpowiada za ich usuwanie), ciężko nam wykonać debugowanie zadań, które z jakiegoś powodu nie działają tak jak powinny.
Niemniej znając te ograniczenia i tak warto zainteresować się tą technologię.