Jak zrobić backend na miliony odczytów (i zapisów)

Siedziałem przy biurku w leniwy poniedziałkowy poranek. Nagle na moim ekranie pojawiło się powiadomienie. Przetwarzanie żądań przez nasz punkt końcowy, który wyświetla informacje o profilu użytkownika, pochłaniało ogromną ilość czasu.
Byłem odpowiedzialny za tę część systemu i musiałem coś zrobić… i to szybko. Klienci są najważniejszą częścią firmy. Jeśli API nie są wydajne, ci będą musieli czekać. Czekanie oznacza irytację i rezygnację z aplikacji. Możesz stracić część aktywnych użytkowników, co zmniejszy zyski Twojej firmy.
UX nawet dla nerdowskiego inżyniera backendu, powinien być oczkiem w głowie codziennych działań. Nie chciałem wizualizować sobie, jak wściekły klient krzyczy nad moją głową. Zrobiłem sobie więc kawę i zacząłem zastanawiać się, jak rozwiązać ten problem.
Pracowałem z mikrousługami, które działały na klastrze Kubernetesa. Z pewnością mogliśmy skalować horyzontalnie, zwiększając tym samym liczbę podów. Czy to mogło rozwiązać problem? Na dwoje babka wróżyła.
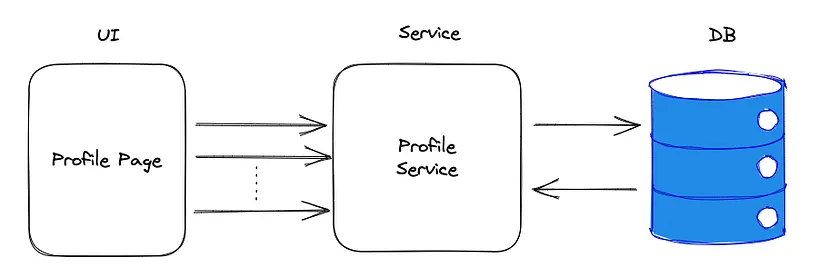
W istocie można dodać więcej podów, ale zwiększa to liczbę połączeń, które trzeba utworzyć z bazą danych. Z kolei instancja bazy danych ma swoje własne ograniczenia i może nie być w stanie obsłużyć wszystkich żądań.
Gdy coś nie jest nieograniczone, możemy przejść w tryb kolejkowania. Niektóre procesy mogą czekać, aż zostaną wykonane, zwiększając tym samym czasy odpowiedzi API. Potrzebowałem alternatywy. Zacząłem przyglądać się naszym pięknym dashboardom, monitorującym działanie API.
Wykresy wyraźnie pokazywały: doświadczyliśmy ogromnego obciążenia w punkcie końcowym, który tworzył nowe profile w naszej bazie danych. Zamiast tego punkt końcowy, który pobierał informacje o profilu, nie wykazywał niczego nowego: ruch był taki sam jak dzień wcześniej.
Czas odpowiedzi nie był taki sam. Podrapałem się po głowie. Punkt końcowy do tworzenia profili miał nadzwyczaj duży ruch, co powodowało spadek wydajności odczytu. Tak! Wiedziałem, jak rozwiązać ten problem.
CQRS (Command Query Responsibility Segregation)
Istnieje wzorzec znany jako CQRS i to nie jest jakaś wielka filozofia. W tym żargonie moduł poleceń jest odpowiedzialny za tworzenie i aktualizowanie danych. Moduł zapytań jest odpowiedzialny za odczytanie tego fragmentu danych. W skrócie: Wzorzec CQRS mówi, że należy oddzielić moduł, który coś zapisuje, od modułu, który coś odczytuje.
W tym przypadku mieszaliśmy (po stronie backendu) zapisy i odczyty z bazy danych usługi. Dużo zapisów w bazie, które są zazwyczaj wolniejsze niż odczyty, spowodowały wydłużenie czasu odpowiedzi punktu końcowego odczytu tylko dlatego, że musiał czekać na zakończenie nieoczekiwanej ilości zapisów.
Postanowiłem zastosować wzorzec CQRS w moim backendzie. Po pierwsze, utworzyłem replikę bazy danych. Jest to bardzo łatwa operacja, jeśli korzystasz z dostawcy usług w chmurze, takiego jak AWS. Umożliwiają oni utworzenie i utrzymanie repliki instancji bazy danych za pomocą kilku kliknięć. Przekształciłem więc moją architekturę backendu w coś takiego:
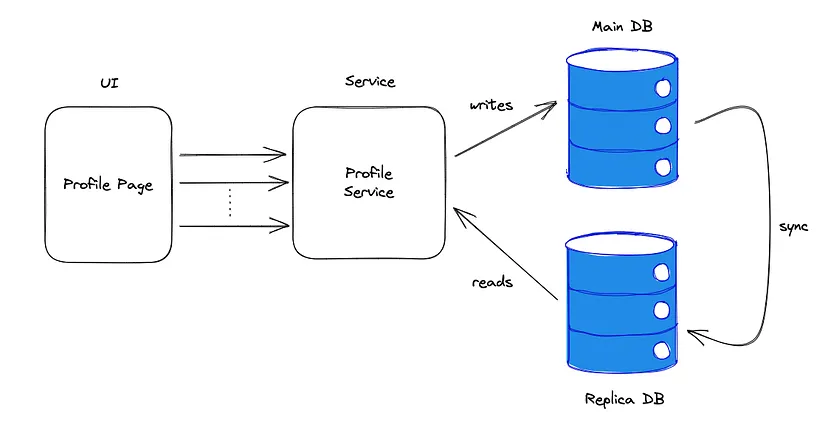
Jak widać, na tym etapie moja usługa nadal była reprezentowana jako mały monolit, ale operacje zapisów nie kolidowały już z odczytami. Najtrudniejszą częścią jest strzałka synchronizacji po prawej stronie.
Synchronizacja danych między systemami nie jest trywialna. Istnieje wiele technik, które można wykorzystać, aby to osiągnąć, ale to temat na inny artykuł. Na razie wróćmy do tej historii.
W kolejnym kroku podzieliłem usługę profilu na dwie usługi. Można się domyślić, że nazwy tych dwóch modułów to:
- Usługa Profile Command
- Usługa Profile Query
Usługa Profile Command była odpowiedzialna za tworzenie i aktualizowanie informacji o profilu użytkownika. Profile Query była odpowiedzialna za ich pobieranie. Przekształciłem więc mój system w coś takiego:
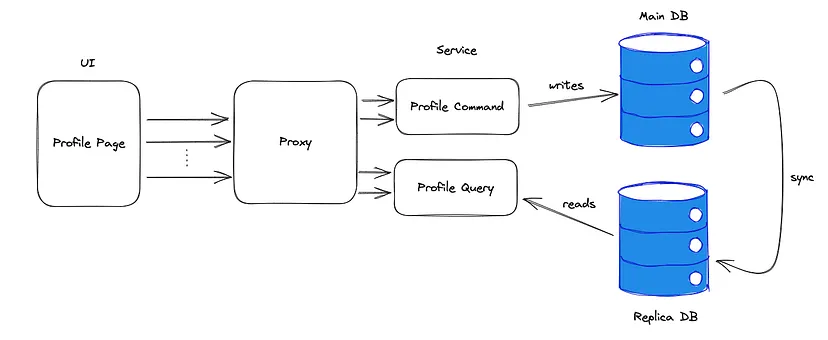
Na tym obrazku zdecydowałem się pokazać również Reverse Proxy celem kierowania żądań interfejsu użytkownika do właściwej usługi, ale było to obecne wcześniej, jak to w mikroserwisach. To rozdzielenie pozwoliło mi na niezależne skalowanie usług.
Zwiększony ruch związany z tworzeniem/aktualizacją informacji o profilu będzie obsługiwany automatycznie, zwiększając liczbę instancji usługi Profile Command bez wpływu na odczyty, które będą wykonywane w innym procesie z inną bazą danych. Czas reakcji wrócił do normy. Teraz nasi użytkownicy są bardziej zadowoleni niż kiedykolwiek wcześniej i nigdy nie mieliśmy problemów z czasem reakcji w przypadku tej konkretnej usługi.
Podsumowanie
Nauczyłem się, jak radzić sobie ze wzmożonym ruchem, który z kolei wiąże się z operacjami na systemie pamięci masowej. Chciałem podzielić się z wami tym, jak prosty jest wzorzec CQRS jako koncepcja i jednocześnie jak ogromne ma on możliwości, gdy zastosuje się go do projektowania architektur backendowych.
W rzeczywistości interesujący nie jest sam wzorzec CQRS, ale decyzje architektoniczne, które można podjąć, mając go na uwadze. Byłem (i nadal jestem) zdumiony wpływem, jaki ta prosta koncepcja wywarła na wydajność mojego backendu.
Oryginał tekstu w języku angielskim przeczytasz tutaj.