Jak stworzyć konfigurowalny pipeline w Jenkinsie

Zastanawialiście się kiedyś, jak wdrożyć praktyki CI/CD w heterogenicznym systemie, do którego wiele zespołów niezależnie i w różnym czasie dostarcza swoje produkty? Nasz zespół stanął przed takim wyzwaniem. Musieliśmy stworzyć jenkinsowy pipeline, który umożliwia zespołom, które testują, instalowanie naszego systemu w różnych konfiguracjach. Na podstawie naszych doświadczeń powstał pomysł na napisanie tego artykułu i podzielenia się z Wami pomysłami na to, jak to zrobić.
Jak, korzystając z systemu kontrolowania wersji, stworzyć jeden pipeline do instalacji systemów w różnej konfiguracji
Jak zatem podejść do tematu, jakim jest stworzenie uniwersalnego pipeline’u, używanego przez wiele zespołów, gdy każdy z nich potrzebuje dostosować go do własnych potrzeb i posiadać niezależną konfigurację? Najprostszym rozwiązaniem są pliki konfiguracyjne, które są wczytywane przez nasz pipeline. Na ich podstawie możemy dostosować działanie naszego produktu do indywidualnych potrzeb klienta, jednocześnie oddając mu odpowiedzialność za zarządzanie konfiguracją.
Tu z pomocą przychodzą systemy wersjonowania. W moim zespole zdecydowaliśmy się na Gita. Na jego podstawie chciałbym pokazać, jak to zrealizować. Zastosowanie systemu wersjonowania daje nam także możliwość weryfikacji zmian wprowadzanych przez właścicieli konfiguracji, wymagając, aby zmiany były wdrażane przy wykorzystaniu mechanizmu pull requestów.
Dla każdego zespołu tworzymy osobną gałąź w naszym systemie wersjonowania:
team_ateam_b
Każda z gałęzi zawiera plik konfiguracyjny naszego pipeline’u. Osobiście preferuję format YAML jako najbardziej dla mnie czytelny.
system_configuration.yaml
Każdy z zespołów posiada niezależną konfigurację:
team_a:
system_version: 3.0
system_type: 2team_b:
system_version: 5.0
system_type: 4
Mając tak przygotowane pliki, możemy zaimplementować ich użycie w naszym pipeline. W tym celu należy ściągnąć żądaną gałąź z naszego repozytorium. Właściwą gałąź określamy np. na podstawie przekazywanego parametru przy uruchamianiu.
dir (<configuration_directory>) {
checkout([$class: 'GitSCM', branches: [[name: '*/${params.team}']],
userRemoteConfigs: [[url: 'http://git-server/user/repository.git']]])
}
Pozostało nam jeszcze wczytanie pliku konfiguracyjnego.
configFile = readYaml(file: "${env.WORKSPACE}/<configuration_directory>/system_configuration.yaml")
Tak oto mamy dostępną konfigurację przechowywaną na naszym systemie wersjonowania. Możemy więc użyć jej do instalacji i konfiguracji systemu zgodnie z wymaganiami.
stage('System installation') {
steps {
script {
installSystem(configFile.system_version)
}
}
}
stage('System configuration') {
steps {
script {
configureSystem(configFile.system_type)
}
}
}
Założę się, że wielu z Was pomyśli, że to przerost formy, przecież można przekazać to samo, używając jenkinsowych parametrów. Oczywiście, że tak, jednak nasz plik konfiguracyjny można wykorzystać do ciekawszych zastosowań i tak właśnie dochodzimy do kolejnego zagadnienia.
Jak włączać/wyłączać wykonywanie poszczególnych etapów (ang. stages) na podstawie pliku konfiguracyjnego
Tak jak wcześniej ustaliliśmy, chcemy stworzyć coś bardzo uniwersalnego. Dlaczego więc nie dać możliwości wyłączania i włączania poszczególnych etapów? Dzięki temu zespoły, które nie potrzebują instalować dodatkowego oprogramowania, mogą ten krok pominąć. Mając nasz plik konfiguracyjny, nic nie stoi na przeszkodzie, aby to zrobić.
Dodajemy odpowiednie wpisy w naszym pliku:
stages:
System installation:
enabled: true
System configuration:
enables: true
Install additional software:
enabled: false
Implementujemy warunkowe uruchamianie w naszym kodzie na podstawie wczytanego pliku YAML:
stage('Install additional software') {
when {
expression {
configFile.stages[STAGE_NAME].enabled
}
}
steps {
script {
InstalladditionalSoftware()
}
}
}
W zależności od ustawień w pliku przebieg naszego pipeline’u będzie różny. Poniżej mamy efekt naszej konfiguracji. Użycie składni declarative daje nam wizualny efekt pominięcia wykonywania. Zespół wie, że dany etap jest wyłączony.
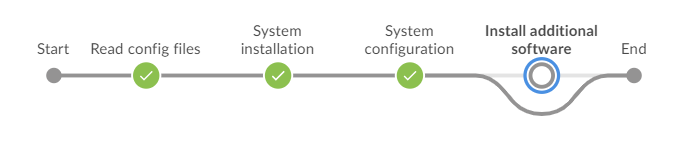
Jak ignorować rezultaty wykonywania etapów (ang. stages) Jenkinsowych na podstawie przygotowanej konfiguracji
Możemy już dowolnie zarządzać wykonywaniem poszczególnych etapów, jednak zespoły mogą potrzebować czegoś więcej. Wyobraźmy sobie sytuację, że instalacja naszego systemu to są godziny, a nie minuty. Jeden z naszych zespołów chciałby włączyć instalację dodatkowego oprogramowania, ale jednocześnie nie chce, aby zostało przerwane wykonywanie całego pipeline’u, jeżeli ta instalacja się nie powiedzie.
Oczywiście możemy to wyłączyć dla wszystkich zespołów. Ustaliliśmy jednak, że zachowanie pipeline’u musi być w pełni konfigurowalne. Dodaję więc do naszego pliku opcję określającą, czy rezultat wykonania danego etapu ma dla nas znaczenie. Używam do tego celu klucza ignore_stage_error.
Install additional software:
enabled: false
ignore_stage_error: true
Przykładowa implementacja może wyglądać następująco:
stage('Install additional software') {
when { expression { configFile.stages[STAGE_NAME].enabled } }
steps {
script {
try {
installAdditionalSoftware()
} catch (error) {
if (configFile.stages[STAGE_NAME].ignore_stage_error) {
markStageUnstable()
} else {
throw new Exception("Stage \"${STAGE_NAME}\" has failed")
}
}
}
}
}
def markStageUnstable() {
catchError(buildResult: 'SUCCESS', stageResult: 'UNSTABLE') {
error("Mark stage unstable")
}
}
Powyższy kod umożliwia zignorowanie ewentualnych błędów i jest możliwy do zdefiniowania poprzez plik konfiguracyjny. Metoda markStageUnstable() oznacza etap jako “UNSTABLE”. Niestabilny etap jest widoczny w Jenkinsie. W związku z tym widać, że nie wszystko przebiegło prawidłowo. Efekt możemy zobaczyć poniżej.

Jak generować równoległe etapy w Jenkinsie na podstawie pliku konfiguracyjnego
Wyobraźmy sobie, że mamy w naszym pipeline równoległe etapy do instalacji np. serwerów, które generują nam ruch potrzebny do testów wydajnościowych. Każdy z zespołów, którym udostępnimy nasz produkt, ma różną ich ilość i w różnej konfiguracji. Zdefiniujmy w naszym pliku YAML serwery do instalacji wraz z informacją o wersji i konfiguracji.
dynamic_server_installation:
Server 1:
disabled: false
server_version: 1.2
configuration_version: 3
Server 2:
disabled: true
server_version: 2.2
configuration_version: 7
Server 3:
server_version: 4.1
configuration_version: 8
Server 4:
disabled: false
server_version: 2.5
configuration_version: 3
Server 5:
disabled: false
server_version: 4.0
configuration_version: 3
Dodaliśmy także możliwość wyłączania instalacji serwerów poprzez ustawienie disabled na True. Jest to o tyle wygodne, że kiedy nie chcemy instalować serwera, nie musimy usuwać (czy komentować) jego definicji z pliku.
Przykładowa implementacja poniżej:
stage('Dynamic server installation') {
steps {
script {
def parallelStages = [:]
configFile.dynamic_server_installation.each { stageName, stageValues ->
if (!stageValues.disabled) {
parallelStages[stageName] = {
stage(stageName) {
installServer(stageValues.server_version)
configureServer(stageValues.configuration_version)
}
}
}
}
parallel parallelStages
}
}
}
Wprowadzenie nowych opcji powoduje, że pipeline wygląda następująco:

Jak uzależnić uruchamianie Jenskinsowych etapów od efektów działania skryptów zewnętrznych
Ostatnim tematem, jaki chciałbym poruszyć, jest zarządzanie uruchamianiem etapów, w zależności od wyników działania zewnętrznych skryptów. Skrypt analizuje dane z zewnętrznego źródła i na podstawie wyników przekazuje, co powinno być uruchomione w naszym pipeline. Zakładamy, że czas analizy danych jest bardzo długi, chcemy zatem wykonać go tylko raz i na podstawie przekazanych informacji uruchomić etapy znajdujące się w różnych miejscach naszego pipeline’u.
Skrypt napisany w Pythonie przekazuje nam na standardowe wyjście (lub do pliku) zmienną, którą wczytamy i która posłuży nam do sprawdzenia, czy powinniśmy uruchomić etap. Fragment kodu w Pythonie:
print("stages_to_execute = [:]")
print("stages_to_execute .'{}' = {}".format("Stage to skip", "false"))
print("stages_to_execute .'{}' = {}".format("Stage to execute", "true"))
Pozostaje nam wczytać dane do wykorzystania przy decyzji, czy dany etap ma być uruchomiony:
stage('Analyze external data source') {
steps {
script {
evaluate(sh(label: 'Analyze data', returnStdout: true, script:"python data_analyzer.py").trim())
}
}
}
Definiujemy etapy, które uruchamiają się w zależności od zmiennej przekazanej przez skrypt:
stage('Stage to skip') {
when {
expression {
stages_to_execute."${STAGE_NAME}"
}
}
steps {
script {
print("Stage to skip")
}
}
}
stage('Stage to execute') {
when {
expression {
stages_to_execute."${STAGE_NAME}"
}
}
steps {
script {
print("Stage to execute")
}
}
}
Po wdrożeniu zmian, nasz pipeline wygląda następująco:
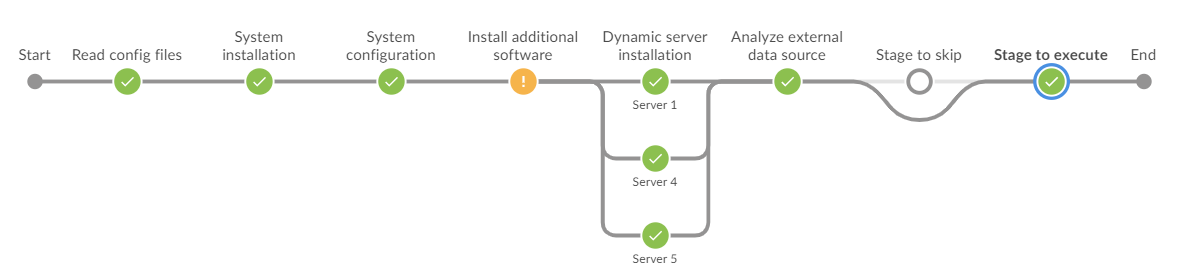
To już ostatnie zagadnienie, które chciałem poruszyć z tematu, jak stworzyć konfigurowalny pipeline i jak w pełni kontrolować jego przebieg, w zależności od wymaganej konfiguracji. Mam nadzieję, że pomysły zawarte w artykule będą dla Was pomocne przy czekających Was wyzwaniach związanych z CI/CD, a może nie tylko.