Jak sprawić, aby mikroserwisy się ze sobą porozumiewały?

Na pewno chcecie budować skalowalne aplikacje, prawda? Bo któżby nie chciał? Jeśli tak jest, to na pewno zetknęliście się z terminem „Cloud-Native”. To podejście może pomóc rozwiązać większość wyzwań ze skalowaniem. Czym zatem jest cloud-native?
Cloud-native to podejście używane do budowania aplikacji, które jest w stanie ujarzmić wszystkie możliwości chmury. Tak jest, to podejście, a nie framework. I właśnie z tego powodu istnieje milion podejść do tego, jak w ogóle wejść w cloud-native i odnaleźć tego Świętego Graala Chmury.
Jednym z kluczowych składników cloud-native są mikroserwisy. Są to małe (ale czasem i większe) moduły, które mogą pracować niezależnie od siebie. Mogą być zależne od innych mikroserwisów lub warstw dostępu do danych, czyli np. od baz danych. Kluczem jest tutaj jednak używanie luźnych powiązań. Mikroserwisy koordynują przez „komunikację”. Oznacza to, że każdy mikroserwis znajduje się w innym repozytorium i jest wdrażany niezależnie. Jeżeli chodzi o DevOpsów, to istnieje niezależna i ciągła linia dostarczania dla każdego mikroserwisu.
Muszę jednak zadać niezwykle ważne pytanie: jak możemy sprawić, że mikroserwisy zaczną ze sobą rozmawiać? Pomijając trudności w wyborze dla nich API kompatybilnego w przód, nauczenie ich komunikacji nie jest takie łatwe. Istnieje kilka czynników, które należy wziąć pod uwagę: przepustowość, opóźnienia i skalowalność.
Istnieje wiele sposobów na sklasyfikowanie kanałów komunikacyjnych. Synchroniczne (blokujące) i asynchroniczne (nieblokujące) to dość często używane przymiotniki, ale mam wrażenie, że bardziej opisują język programowania. Dam sobie również spokój z pół-duplexem i pełnym duplexem, ponieważ dzisiaj bardzo łatwo jest używać obu w większości chmurowych architektur.
Zajmijmy się naszym tematem.
Architektura bez brokera
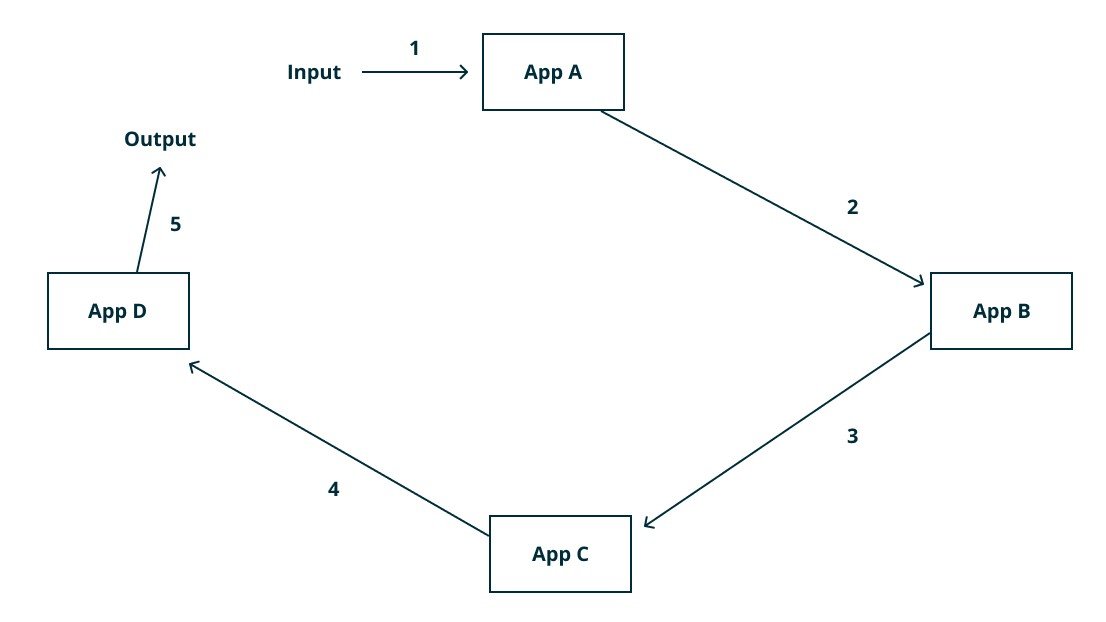
O co tutaj chodzi: nasze mikroserwisy rozmawiają ze sobą bezpośrednio. Możesz użyć HTTP dla tradycyjnego żądanie-odpowiedź albo websocketów (lub HTTP2) dla streamingu. Nie ma żadnych pośrednich węzłów (poza routerami i load balancerami) pomiędzy dwoma lub więcej mikroserwisami. Możesz się bezpośrednio połączyć z każdą usługą, o ile znasz adres i API, którego dana usługa używa.
Brzmi banalnie, prawda? Bo takie jest. Istnieją wspaniałe protokoły pokroju GRPC, aby życie było łatwiejsze.
Zalety:
- Niska latencja: podejście to daje najniższą możliwą latencję. Szybko i bez pośredników. Problemy mogą wynikać ze słabej implementacji API. Jednak, narzędzia takie jak GRPC sprawiają, że otrzymujesz maksymalną wydajność na warstwie API.
- Łatwa implementacja: architektura brokerless jest łatwy do zwizualizowania i implementacji.
- Łatwe debugowanie: znajdowanie błędów to ważna rzecz, jeśli chodzi o rozproszone systemy. Staje się jeszcze ważniejsze, kiedy wydajesz update’y kilka razy w ciągu dnia.
- Wysoka wydajność: CPU jest poświęcone na faktyczną pracę, a nie na routing. Nie ma więc nic dziwnego w tym, że większość API bazy danych używa bezpośrednich połączeń.
Wady:
- Service discovery ma tutaj kluczowe znaczenie. Mechanizm ten musi być wystarczająco responsywny i skalowalny, aby odzwierciedlić najświeższy stan klastra.
- Koszmar połączeniowy: wyobraźcie sobie, że wszystkie mikroserwisy muszą być ze sobą połączone. Większość połączeń jest bezczynna. W rezultacie wiele zasobów się marnuje.
- Silne powiązania: naturalne jest to, że użycie bezpośrednich połączeń między serwisami tworzy między nimi silne powiązania. Wyobraźcie sobie, że wasz mikroserwis przetwarza płatności internetowe. Potrzebujecie teraz kolejnego mikroserwisu, będzie w czasie rzeczywistym pokazywać liczbę płatności na minutę. Będzie to wymagało modyfikacji w wielu mikroserwisach, a to jest niepożądane.
Brokerless design może w wielu przypadkach nie działać. Często trzeba opublikować wiadomość raz i sprawić, że wielu subskrybentów ją odbierze. W tym przypadku lepsza będzie architektura z brokerem wiadomości.
Messaging Bus (Broker) Design
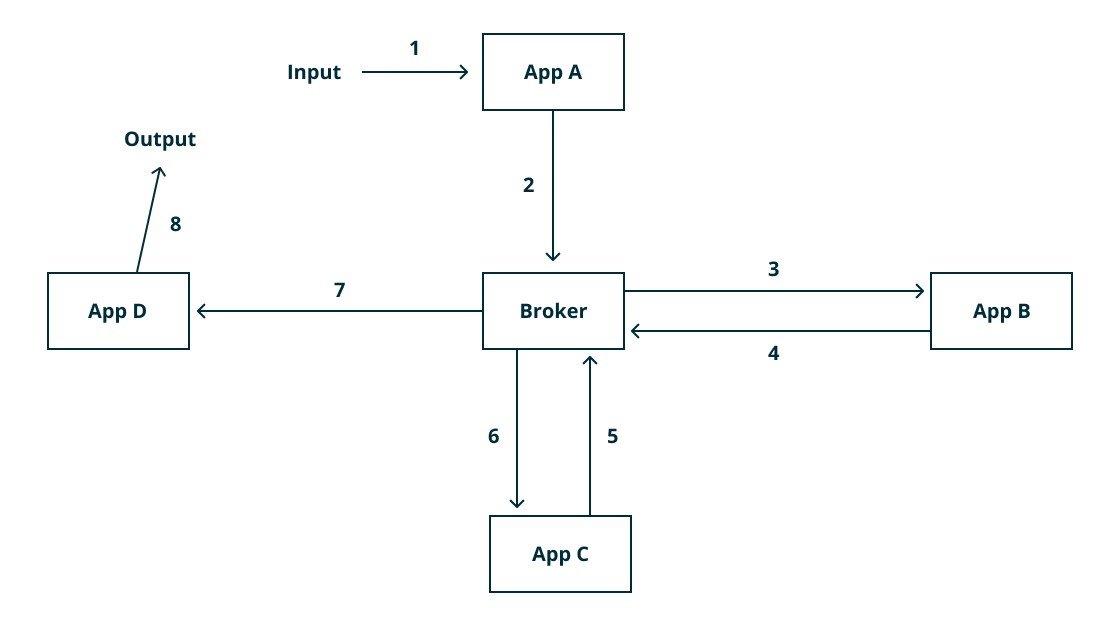
W tej architekturze cała komunikacja jest przekierowana przez grupę brokerów. Są to programy, które działają w oparciu o dość zaawansowane algorytmy routingu. Każdy mikroserwis jest podłączony do brokera. Mikroserwis może wysyłać i otrzymywać wiadomości przez to samo połączenie. Serwis wysyłający informacje to wydawca (publisher) a odbiorcę określa się mianem subskrybenta (subscriber). Wiadomości są publikowane w konkretnym „temacie”. Subskrybent otrzymuje takie wiadomości w tematach, które subskrybował.
Zalety:
- Load balancing: większość brokerów przekazujących wiadomości wspiera load balancing bez potrzeby instalacji jakiegokolwiek dodatkowego składnika (out of the box). Sprawia to, że dana architektura jest o wiele prostsza i bardziej skalowalna. Niektóre brokery (np. RabbitMQ) mają wbudowane ponowne ponawianie dostarczenia i inne mechanizmy, które zwiększają niezawodność komunikacji.
- Service discovery: nie jest wymagane, by poszczególne serwisy wiedziały o sobie. Wszystkie mikroserwisy zachowują się jak klienci. Jedyny serwis, który musi zostać wykryty to broker przekazujący wiadomości.
- Fan In oraz Fan Out: użycie messagingu ułatwia dystrybucję zadań i zebranie wyniku. Najlepsze jest to, że dodawanie kolejnych mikroserwisów nie wpływa często na inne serwisy i nie wymaga ich aktualizacji.
Architektura oparta o strumienie: takie podejście to początek koncepcji strumieni. Każdy temat to tak naprawdę strumień wiadomości. Każdy subskrybent może użyć danych ze strumienia, kiedy zachodzi taka potrzeba. Możliwości modelowania systemu przy pomocy strumieni są nieograniczone.
Wady:
- Skalowanie brokerów: podczas gdy zalety są obiecujące, skalowanie brokerów to nie lada wyzwanie dla mocno rozproszonych systemów. Jest to po prostu kolejna rzecz do utrzymania.
- Wysokie opóźnienie: użycie magistrali komunikacyjnej zwiększa całościowe opóźnienie. Jest to szczególnie adekwatne w przykładach użycia RPC. W aplikacjach, które muszą dobrze działać, można tego użyć, jednak nie jest to zalecane.
- Większe zużycie zasobów: broker potrzebuje procesora, pamięci i przestrzeni dyskowej, aby działał. Zasoby te mogłyby być użyte przez inne mikroserwisy. Ogólny koszt związany z wykorzystaniem brokera może być za duży dla małego klastra.
Świadomość wad i zalet niektórych architektur to nie wszystko. Ważne jest też to, żeby wiedzieć, kiedy ich używać.
Brokerless design powinno być Twoją domyślną architekturą. Zmień ją, jeśli potrzebujesz elastyczności zapewnianej przez strumienie albo użycie modelu pub-sub. Jednak jeśli dopiero zaczynasz, to zacznij od tradycyjnej architektury, a potem przestaw się, jeżeli zachodzi taka potrzeba. Nie trzeba korzystać z jednej, można użyć obu. Przy rozwoju naszego narzędzia używamy broker design do implementacji calli RPC. Komunikacja z naszą bazą danych jest bezbrokerowa, aby zapewnić niskie opóźnienie.
Jeśli zależy Ci na architekturze opartej na mikroserwisach, polecam podejście event-driven. Na architekturę event-driven można spojrzeć, jak na coś, co w centrum posiada zaawansowanego brokera, który ma mnóstwo możliwości (jak np. planowanie zadań).
Podsumowanie
Używanie odpowiedniego podejścia w pracy jest ważne. Wybór trybu komunikacji to podstawa i trzeba do tego podejść rozsądnie i ostrożnie.
Jest wiele opcji. Trzymanie się popularnych frameworków jest prawie zawsze bardziej sensowne niż robienie czegoś od zera. Dla brokerów wiadomości można użyć RabbitMQ, Nats, Kafka itd., ponieważ każdy z nich jest dopasowany do konkretnej semantyki. Kolejnym niesamowitym sposobem jest użycie Backend as a Service jak Space Cloud. Automatyzuje on cały backend związany z mikroserwisami tak, aby można było się skupić na logice biznesowej, a nie na projektowaniu architektury chmury.
Oryginał tekstu możesz przeczytać tutaj.