Jak skalujemy architekturę? Kilka słów o mikroserwisach

Architektura monolityczna to tradycyjny model projektowania systemów/aplikacji istniejący w branży IT od wielu lat. Jednak przy dużym tempie rozwoju i potrzebie skalowalności szybko okazuje się, że jest to rozwiązanie niewystarczające. Koszt rozbudowy i modernizacji monolitu z czasem zwiększa się do ogromnych wartości, przy których łatwiej jest zaprojektować nową aplikację od zera. W takiej sytuacji z pomocą przychodzą tzw. mikroserwisy.
W skrócie monolit polega na umieszczeniu wszystkich części systemu w jednej bazie kodu i wdrażaniu ich jako całości na jednym serwerze. Główną zaletą takiego systemu jest łatwość projektowania oraz niski początkowy koszt infrastruktury. Często aplikacje zaczynają swoje życie jako monolity, bo jest to łatwiejsze, tańsze i szybsze rozwiązanie.
Najważniejsze zalety i wady architektury monolitycznej
Zalety:
- niskie koszty projektowania oraz infrastruktury;
- niewielki stopień skomplikowania systemu;
- wysoka wydajność dla jednego procesu;
- większe bezpieczeństwo komunikacji między modułami – wszystko odbywa się w pamięci i nie opuszcza serwera;
- łatwiejsze testowanie i debugowanie.
Wady:
- model ten jest podatny na awarie, ponieważ wszystkie moduły nie działają jednocześnie;
- trudne i kosztowne wprowadzanie zmian;
- trudność z jednoczesną pracą wielu osób;
- bardzo ograniczona skalowalność (zazwyczaj możliwa jest tylko multiplikacja całych aplikacji, a nie pojedynczych modułów);
- często jeden błąd oddziałuje na całą aplikację. W przypadku błędu, który pochłania dużą ilość zasobów (CPU, RAM), ciężko jest stwierdzić, która część systemu za to odpowiada.
Monolity nadal są stosowane w przypadku mniejszych systemów lub bardzo starych, nierozwijanych od dawna aplikacji. Coraz częściej jednak to rozwiązanie wypierane jest przez mikroserwisy. Wszystko rozbija się o potrzeby danej firmy.
O jakiej skali działalności mówimy?
W Dealavo codziennie pobieramy informacje o cenach dla 250 milionów produktów. W tym celu wykonujemy ponad 150 milionów zapytań i pobieramy oraz procesujemy ponad 20 terabajtów danych. Warto zaznaczyć, że wartości te z dnia na dzień wzrastają. Jest to ilość danych wymagająca bezbłędnej i niezawodnej pracy systemu przez całą dobę. W jaki sposób jesteśmy w stanie to osiągać każdego dnia? Odpowiedzią jest skalowalna architektura systemu oparta o tzw. mikroserwisy.
Czym są mikroserwisy?
Mikroserwisy to obecnie jeden z najważniejszych trendów technologicznych. Jest to pojęcie opisujące sposób projektowania architektury systemu polegający na stworzeniu wielu połączonych ze sobą mniejszych modułów realizujących pojedyncze zadania i komunikujących się ze sobą poprzez rozmaite protokoły komunikacyjne.
Główne zalety takiego podejścia:
- wysoka wydajność i szybkość działania;
- wysoka skalowalność;
- odporność na awarie – łatwość zastępowania pojedynczych części systemu innymi;
- lepsza kontrola narastającego długu technologicznego – łatwiej jest modernizować mniejsze części systemu w oderwaniu od siebie;
- mniejsza zależność od konkretnego dostawcy usługi (łatwo jest uruchomić potrzebną część systemu np. na serwerze od innego dostawcy).
Jak każdy system, rozproszone podejście to posiada również wady:
- architektura jest bardziej skomplikowana i rozproszona;
- często efekt końcowy danej operacji przechodzi przez wiele modułów, co wpływa na trudność i pracochłonność debugowania;
- komunikacja między modułami odbywa się po sieci, z czego wynika większa praca potrzebna na zapewnienie bezpieczeństwa.
Przykład architektury opartej na mikroserwisach
Jak można zrealizować rozproszony system do pobierania i przetwarzania danych? Oto uproszczony przykład obrazujący schemat pobierania jednego źródła danych w oparciu o mikroserwisy.
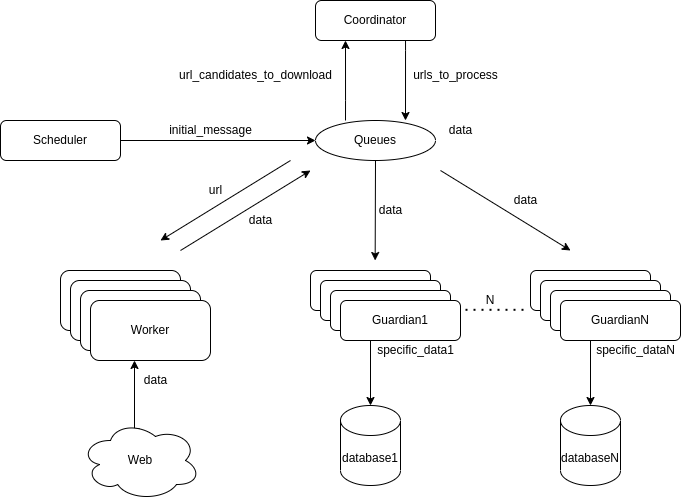
Podstawą komunikacji w tym przypadku jest system kolejek, do których są wysyłane i odbierane różnego rodzaju wiadomości zawierające zarówno parametry wejściowe dla modułów, jak i rezultaty ich działania. Może to być dowolny system. Dobrym przykładem będzie RabbitMQ. Jeden serwer kolejek może przeprocesować kilkadziesiąt tysięcy wiadomości na sekundę.
Dzięki temu możliwe jest wyodrębnienie pojedynczych modułów realizujących konkretne zadania:
- Scheduler– moduł inicjujący flow, zlecający np. pobranie konkretnego źródła danych. Wysyła inicjującą informację do odpowiedniej kolejki.
- Queues– system imiennych kolejek, np. RabbitMQ.
- Coordinator– moduł koordynujący pracę workerów. Analizuje i wybiera kolejne adresy URL do pobrania przez workery i zbiera statystyki.
- Workery– grupa prostych i jednakowych modułów, których zadaniem jest pobranie URL-a z kolejki, pobranie zawartości strony internetowej, przetworzenie danych oraz zwrócenie rezultatu do osobnej kolejki.
- Guardiany– grupa modułów, których zadaniem jest odebranie wyników prac workerów oraz wydajne i poprawne zapisanie ich do odpowiedniej bazy danych.
Takie podejście jest łatwo skalowalne – jeżeli potrzebujemy pobierać i przetwarzać więcej danych, wystarczy zwiększyć liczbę workerów oraz guardianów. Ze względu na jeden ogólny system komunikacji każdy moduł może być stworzony w innej technologii oraz uruchomiony na osobnym serwerze. Ponadto każda część systemu może być rozwijana przez inny zespół programistów. W przypadku awarii któregoś z serwerów łatwo jest uruchomić odpowiednie moduły na innym serwerze, gwarantując tym samym ciągłość pracy i niezawodność systemu.
Podsumowanie
Rozproszona architektura w oparciu o mikroserwisy to rozwiązanie bardziej skomplikowane niż monolit i wymagające większej ilości pracy i uwagi (zarówno na etapie projektowania, jak i wdrażania). Zapewnia jednak wysoką skalowalność oraz odporność na awarie. Z pewnością jest to dobre rozwiązanie dla firm, które szybko potrzebują wdrażać nowe zmiany, skalować swój biznes i pozwolić na autonomiczny, równoległy rozwój wielu jego gałęzi. Jeżeli jednak istnieje potrzeba szybkiego i tańszego uruchomienia mniej skomplikowanego projektu, to monolit nadal jest opcją do rozważenia.