Jak efektywnie skalować aplikację internetową?

Niemal wszystkie aplikacje zaczynają od jednego uniwersalnego celu — zbudowania bazy użytkowników i udowodnienia, że istnieje rynek dla danej aplikacji. Wraz ze wzrostem liczby użytkowników wzrasta ruch, a wzrost ruchu prowadzi do większego obciążenia infrastruktury Twojej aplikacji. Podczas gdy powinieneś cieszyć się z takiego sukcesu, to jednak najlepiej odłożyć bąbelki jeszcze na jakiś czas i poradzić sobie z kilkoma przeszkodami. W przeciwnym razie, szybko uświadomisz sobie, że Twoja aplikacja ma słabą wydajność, a to szybko prowadzi do frustracji jej użytkownika. Jeśli tak się stanie, nie będziesz już potrzebował skalowania, ponieważ Twoi użytkownicy już opuścili Cię dla konkurencji.
Zauważyłem, że przewodniki na temat skalowania aplikacji internetowej albo nie zawierają ważnych wzorców skalowania, albo, co równie ważne, nie obejmują procesów myślowych związanych z wyborem rozwiązań skalujących. Nie się nie martw, ten przewodnik ma wszystko pod kontrolą i zaraz dowiesz się o co chodzi!
Ogólnie rzecz biorąc, baza danych jest pierwszym komponentem, który wykazuje oznaki przeciążenia. W tym artykule skupimy się natomiast na skalowaniu Twojego serwera WWW.
Zanim przejdziemy do rozwiązań skalowania dla serwera WWW, istnieje kilka bardzo ważnych aspektów do rozważenia: Koszty skalowania i skalowanie aplikacji z wykorzystaniem metryk. Te aspekty skalowania są równie ważne, jeśli nie ważniejsze, niż same wzorce skalowania. Poruszyliśmy już te aspekty w części 1 tej serii, więc jeśli jeszcze nie czytałeś, to zdecydowanie polecam, abyś mógł wyposażyć się w zrozumienie tych integralnych procesów efektywnego skalowania aplikacji internetowych. A więc bez zbędnego zastanawiania się, zobaczmy dalej o co chodzi!
Rozwiązania do skalowania serwera
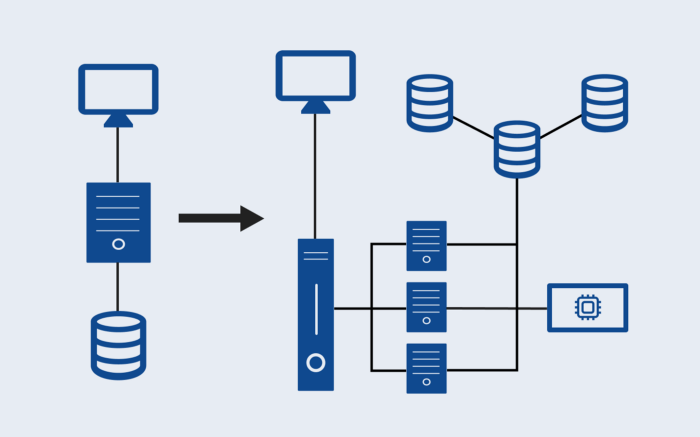
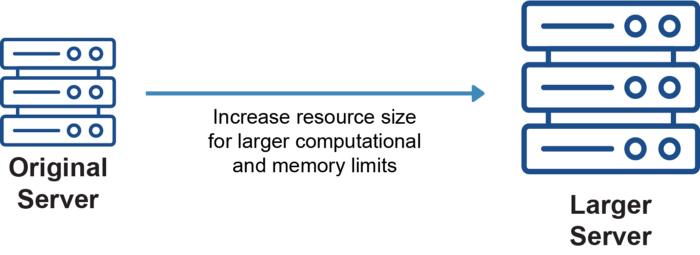
Skalowanie wertykalne (Scaling Up)
Wraz z powiększaniem się naszej bazy użytkowników, rośnie też liczba klientów łączących się jednocześnie z jednym serwerem. Serwerowi w końcu zabraknie pamięci RAM i CPU, co spowoduje spowolnienie działania aplikacji, wyrzucony błąd lub awarię. Zapewne zapytasz czy możemy po prostu zwiększyć ilość RAM-u i liczbę CPU? Tak, możemy. Jest to skalowanie wertykalne, znane również jako scaling up. Jest to po prostu metoda dodania zasobów do istniejącego serwera lub zastąpienia istniejącego serwera bardziej wydajnym serwerem; wzorzec architektoniczny pozostaje taki sam.
Nie jest to jednak stała poprawka i generalnie nie jest to najlepszy wzorzec skalowania do początkowego wdrożenia. Istnieje granica skalowania wertykalnego, ponieważ w końcu osiągniesz pojemność zasobów dla maszyny, której używasz. Droższe jest również posiadanie jednego serwera o zwiększonej wielkości, powiedzmy 128 GB RAM, niż posiadanie czterech serwerów 32 GB RAM odpowiadających 128 GB RAM — przyrost pojemności jest mniejszy w porównaniu do wydanych pieniędzy.
Inną pułapką tego wzorca skalowania jest to, że nadal zachowuje problem pojedynczego punktu podatności na awarię (SPOF) — jeśli coś pójdzie nie tak z serwerem, Twoja aplikacja ulegnie awarii, ponieważ nie ma redundancji lub rezerwy awaryjnej.
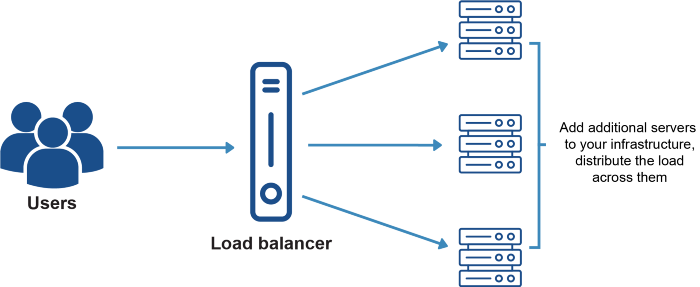
Skalowanie horyzontalne (Scaling Out)
Sytuacja wygląda tak, że przyjrzeliśmy się skalowaniu wertykalnemu naszego serwera, ale nie znaleźliśmy trwałego rozwiązania, a także nie mamy infrastruktury odpornej na błędy. Witaj więc w skalowaniu horyzontalnym — jest to wzorzec architektury rozproszonej, w którym dodajemy kolejne serwery służące do tego samego celu.
Skalowanie horyzontalne jest nieskończone w swojej naturze, ponieważ serwery skalują się od 1 do ‘n’, i nie ma żadnego ograniczenia. Wbudowuje odporność w infrastrukturę aplikacji, ponieważ istnieje niezliczona ilość serwerów, na których można się oprzeć w przypadku awarii jednego z nich. Jest to również tańsze niż skalowanie wertykalne, wraz z powiększającą się liczbą skalowania.
Jedną ze złożoności, którą wprowadza skalowanie horyzontalne, jest dystrybucja ruchu. Aby równomiernie rozłożyć ruch pomiędzy serwerami używamy load balancer. Load balancer działa jako pośrednik między klientami a serwerami. Zna adres IP serwerów i dzięki temu jest w stanie kierować ruch z klientów do serwerów.
Posiadanie tylko jednego load balancera podnosi kwestię pojedynczego punktu podatności na awarię ponownie. Aby poradzić sobie z tym problemem, dwa lub trzy load balancery są skonfigurowane, kiedy jeden aktywnie sprawdza trasę ruchu, a inne są tam jako redundancja.
W dzisiejszych czasach dostawcy usług w chmurze, tacy jak AWS, GCP i Azure, wykonują ciężką pracę, aby wdrożyć takie rzeczy jak równoważenie obciążenia, skalowanie horyzontalne i skalowanie wertykalne. Jako inżynierowie musimy tylko coś ustawić i zarządzać konfiguracją, wiele złożoności zostało już wyeliminowanych.
Nadal jednak trzeba wiedzieć, co dzieje się pod maską, aby skutecznie ustawić rzeczy i zarządzać wszystkim, ale uwierz mi, jest to o wiele łatwiejsze niż kiedyś. Na przykład, coraz więcej usług jest wydawanych z funkcjami autoskalowania, takimi jak AWS Fargate; nie musisz ręcznie wdrażać skalowania horyzontalnego, ani nawet konfigurować lub wiedzieć kiedy i jak skalować; wszystko jest robione automatycznie, o co zadbało AWS.
Po prostu konfigurujesz swój stos AWS Fargate i to wszystko — Tak więc… to dobry czas, aby być inżynierem! Zapewne są chwile, kiedy chciałbyś mieć więcej kontroli, ale chodzi o to, że istnieje spektrum opcji, począwszy od wdrożenia wszystkiego samemu, aż po zadbanie o wszystko przez dostawców IaaS (Infrastructure as a Service).
Przechowywanie sesji
Jeśli Twoja aplikacja używa sesji do identyfikacji użytkowników, a nie uwierzytelniania opartego na tokenach, to posiadanie wielu serwerów spowoduje problemy, ponieważ sesje są przechowywane w pamięci na serwerach. Na przykład, gdy użytkownik loguje się, może to robić za pośrednictwem serwera 1, na którym przechowywane są dane sesji, przy następnym żądaniu użytkownik/klient może zostać przekierowany na serwer 2, gdzie będzie musiał zalogować się ponownie, ponieważ ten serwer nie posiada informacji o sesji.
Aby rozwiązać ten problem, informacje o sesji mogą zostać odłączone do osobnego miejsca przechowywania, takiego jak magazyn struktur danych in-memory, np. serwer Redis. W ten sposób wszystkie serwery będą wysyłały i odbierały wszystkie swoje sesje do i z serwera Redis. A więc jeszcze raz... wystąpiłby problem pojedynczego punktu podatności na awarię, możemy dodać redundancję dla serwera Redis, aby zwiększyć odporność naszej aplikacji i wyeliminować ten potencjalny problem.
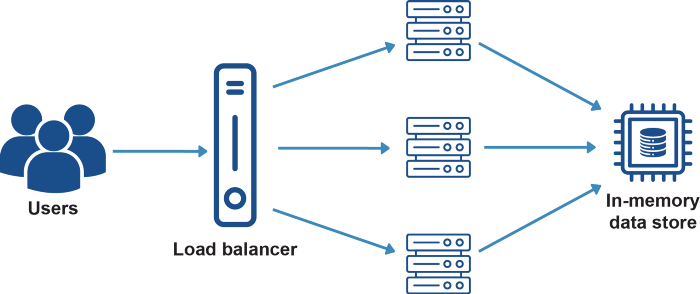
Jeśli na serwerach muszą być przechowywane jakiekolwiek inne dane, powinny one zostać odłączone do własnego rozwiązania pamięci masowej, a wszystkie serwery powinny mieć dostęp do lokalizacji tej pamięci.
Innym rozwiązaniem do rozwiązania problemu przechowywania sesji jest zmiana implementacji uwierzytelniania na opartą na tokenach, co przenosi obciążenie sesji z serwera na klienta. Rozwiązanie to jest nieskończenie skalowalne, ponieważ dane sesji użytkownika przechowywane są na ich kliencie, podczas gdy przechowywanie wszystkich sesji w pamięci serwera może wyczerpać pamięć serwera, jeśli baza użytkowników jest wystarczająco duża.
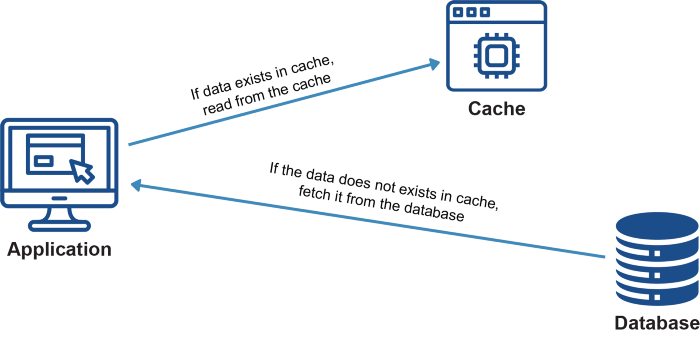
Pamięć podręczna zapytań do bazy danych
To rozwiązanie skalowania zostało już omówione w części 1 tej serii. Wspominam o nim ponownie, ponieważ cache’owanie zapytań do bazy danych jest nie tylko jednym z najprostszych sposobów na skalowanie bazy danych, ale ma również duży wpływ na skalowanie serwera lub serwerów. Jak wcześniej wspomniałem: „Wysoko postawionym celem rozwiązań skalujących jest, aby stos wykonywał mniej pracy dla najczęstszych żądań aplikacji lub efektywnie wyrównał obciążenia, którego nie można wyeliminować, na wiele zasobów”.
Cache’owanie zapytań do bazy danych właśnie to robi — eliminuje całą masę pracy ze stosu. Poniżej znajduje się link do części 1 tej serii, gdzie będziesz lepiej mógł zrozumieć, dlaczego buforowanie jest tak ważne i jak skutecznie je wdrożyć.
Aktywa statyczne serwera poprzez Content Delivery Network
Aktywa statyczne to obiekty, które wysyłasz do użytkownika, a których serwer nie zmienia. Niektóre aktywa statyczne, takie jak strony HTML i pliki JavaScript są stosunkowo lekkie. Inne statyczne aktywa, takie jak obrazy i filmy są dużymi plikami, które bardzo obciążają serwer podczas wysyłania ich przez sieć do klienta za każdym razem, gdy użytkownik zażąda strony. Jeśli Twoja aplikacja jest obciążona statycznymi aktywami, powinieneś zdjąć obciążenie serwowania statycznych aktywów z Twojego serwera/serwerów i przenieść je na CDN jako pierwsze rozwiązanie skalujące.
Content Delivery Network (CDN) to geograficznie rozproszona sieć serwerów, które współpracują ze sobą w celu zapewnienia szybkiego dostarczania statycznych treści. Zawartość jest serwowana z pamięci podręcznej in-memory, z najbliższego serwera w sieci do klienta żądającego zawartości.
Korzystanie z usług dostawców usług w chmurze, takich jak AWS S3 i Cloudfront, czyni to o wiele łatwiejszym. Wystarczy prosta konfiguracja, a nie tylko obciążenie serwera zostanie zmniejszone, ale również statyczne treści będą serwowane znacznie szybciej, dając Twojej aplikacji solidny zastrzyk wydajności, z którego użytkownicy będą zadowoleni.
Wnioski
Skalowanie aplikacji jest dzisiaj bardzo proste dzięki dostawcom IaaS, takim jak AWS. Oczywiście nadal mamy możliwość ręcznego wdrożenia rozwiązań skalujących, ale dla większości scenariuszy, sensowne jest, aby zespół programistów był tym odciążony, dzięki czemu będzie mógł skupić się na warstwie aplikacji.
Gratulacje, Twoja aplikacja ma teraz odpowiednie rozwiązania, aby efektywnie radzić sobie z obciążeniem serwera i bazy danych. Jednak to jeszcze nie czas na świętowanie... my, ludzie, odznaczamy się minimalnym czasem skupienia; prędkość o skali błyskawicy i wydajność są koniecznością, jeśli nie chcesz stracić swoich ciężko zarobionych klientów na rzecz tego paskudnego kopisty, który nie mógł wymyślić własnego pomysłu. Dzięki za przeczytanie!
Oryginał tekstu w języku angielskim można przeczytać tutaj.