GraphQL w akcji

Obecnie standardem definiowania API do wymiany informacji pomiędzy częścią serwerową a frontendową czy aplikacjami mobilnymi, jest styl architektoniczny REST. Świat się zmienia. Szczególnie świat informatyki. Treści online stają się coraz bogatsze, a wymagania użytkowników co do aplikacji internetowych rosną. Stajemy się również mniej cierpliwi – każda sekunda opóźnienia może nas zniechęcić do wybranej aplikacji. Szczególnie w dobie nieustannej konkurencji. Programiści, starając się nadążyć za rosnącymi wymaganiami, rozwijają kolejne techniki programowania.
Jak zapewne wszyscy wiemy, w technologii REST posługujemy się zasobami identyfikowanymi za pomocą adresów URL, na których możemy wykonywać pewne operacje. Wszystkich, którzy poczuli się urażeni spłyceniem ostatecznie dość zawiłego tematu, bardzo przepraszam.
Architektura oparta o REST, choć zapewne obecnie najbardziej popularna i wspierana przez największą liczbę frameworków we wszystkich możliwych językach, nie jest pozbawiona jednak pewnych wad.
Zalogujmy się na przykład do biura podróży. Zobaczmy, ile żądań do serwera musi zostać wykonane, aby wyświetliła się nam nasza spersonalizowana strona. Zobaczymy tu zapewne zapytania o nasze dane, rezerwacje, zakupione bilety, punkty lojalnościowe, korespondencję z biurem no i oczywiście specjalnie dla nas przygotowane rekomendacje przyszłych wakacji.
Każda z tych rzeczy to zapewne oddzielny zasób REST. Razem składa się to w całkiem pokaźną liczbę żądań pomiędzy przeglądarką a serwerem. A pamiętajmy, że przeglądarki mają ograniczenia na ilość jednoczesnych requestów, szczególnie na telefonach komórkowych – ok. 5 dla każdej strony. Wszystko to sprawia, że cenne milisekundy uciekają, a my zaczynamy się niecierpliwić.
I tutaj z pomocą przychodzi nam GraphQL!
Co to jest GraphQL?
Definicja mówi, że GraphQL jest językiem zapytań dla API oraz środowiskiem wykonawczym dla tychże zapytań po stronie serwera.
Znowu pisząc w największym skrócie, chodzi o to, że w jednym zapytaniu możemy poprosić serwer o wszystkie dane, które nas interesują. I co ważne, tylko o nie! Może przychodzi nam do głowy analogia do SQL? I słusznie, w tym przypadku również wykonujemy zapytania, które łączą dane z różnych tabel i zwracają tylko wybrane pola z danych.
GraphQL w akcji
Zobaczmy na przykładzie, jak GraphQL działa w praktyce. Na szczęście w Internecie możemy znaleźć kilka firm i instytucji, które publicznie udostępniają swoje API w formie GraphQL. Jedną z nich jest kolej niemiecka Deutsche Bahn. Pod tym adresem, znajdziemy przyjazny edytor zapytań, w którym od razu możemy je wykonywać. Dostępnych jest też kilka gotowych przykładów. Przeanalizujmy takie zapytanie.
Ale najpierw parę słów teorii. W sumie musimy pamiętać tylko o paru zasadach:
- W zapytaniu podajemy pola, które nas interesują.
- Pola mogą być zagnieżdżane.
- Pola mogą posiadać argumenty (przypominają wówczas funkcje).
- Poruszamy się w ramach zdefiniowanego schematu.
- Każde zapytanie zaczynamy od pól obiektu Query (czyli takiego wierzchołka naszego poszukiwania).
Wracając do pociągów, chcemy wyszukać wszystkie stacje, które znajdują się w odległości 2 km od zadanej współrzędnej geograficznej. Interesuje nas na razie tylko nazwa tej stacji. Zapytanie takie ma postać:
{
nearby(latitude: 50.11, longitude: 8.66, radius: 2000) {
stations(count: 5) {
name
}
}
}
W zapytaniu wyszukujemy pole nearby obiektu nadrzędnego Query (z przekazanymi parametrami), a w ramach tego obiektu interesuje nas pole stations i kolejno pole name obieku stations.
Jako wynik otrzymujemy obiekt json, zawierający żądane nazwy stacji kolejowych:
{
"data": {
"nearby": {
"stations": [
{
"name": "Frankfurt (Main) Hbf"
},
{
"name": "Frankfurt (Main) Taunusanlage"
},
{
"name": "Frankfurt (Main) Galluswarte"
}
]
}
}
}
Wzbogacimy teraz nasze wyszukiwanie o kilka szczegółów. Dodajmy do zapytania dodatkowe pola hasParking, oraz picture z podpolem url. Jak się łatwo domyślić, chcemy sprawdzić, czy dana stacja posiada parking i zobaczyć zdjęcie tej stacji.
{
"data": {
"nearby": {
"stations": [
{
"name": "Frankfurt (Main) Hbf",
"hasParking": true,
"picture": {
"url": "https://api.railway-stations.org/photos/de/1866.jpg"
}
},
{
"name": "Frankfurt (Main) Taunusanlage",
"hasParking": false,
"picture": {
"url": "https://api.railway-stations.org/photos/de/1857_1.jpg"
}
}
]
}
}
}
Po wykonaniu zapytania dostajemy dokładnie te informacje, o które poprosiliśmy. Możemy skopiować zwrócony link zdjęcia do przeglądarki i zobaczyć stację na własne oczy.
Kilka słów o schemacie danych
Naturalne pytanie, jakie zapewne wielu z nas sobie już postawiło, to skąd wiadomo, jakich pól możemy używać w naszych zapytaniach?
Otóż każde API zdefiniowane za pomocą GraphQL, musi posiadać swój schemat, który opisuje jego strukturę. Jest to nic innego, jak zbiór typów, które całkowicie opisują te dane, które mogą być pobrane z serwisu.
GraphQL udostępnia kilka wbudowanych typów prostych takich jak: liczby całkowite, zmiennoprzecinkowe, łańcuchy czy typ logiczny. Umożliwia też zdefiniowanie takich konstrukcji jak interfejsy, typy wyliczeniowe oraz własne obiekty. Język opisujący schemat jest bardzo prosty i po paru minutach eksperymentów można z łatwością się nim posługiwać.
Musimy tylko pamiętać, że nasz schemat powinien definiować typ Query. Jest to jeden wyróżniony typ, który definiuje pola, od których zaczyna się nasze zapytanie.
Zobaczmy, jak wygląda to w przypadku kolei niemieckich.
Po prawej stronie edytora, w którym wykonywaliśmy zapytania, znajduje się przycisk „Docs”, za pomocą którego możemy otworzyć panel z dokumentacją schematu.
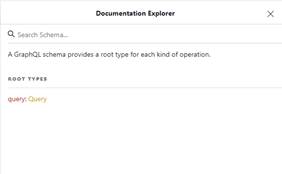
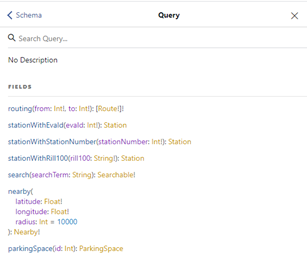
Przeglądając dokumentację, widzimy, że zapytanie może zawierać kilka pól, między innymi wykorzystane przez nas pole nearby. Klikając w kolejne typy, poznajemy ich strukturę. Zatem możemy zobaczyć, jakie pola mogą być wykorzystane przy opisie stacji kolejowej albo parkingów. Zachęcam wszystkich do samodzielnej zabawy i budowania sowich zapytań.
To nie wszystko...
W tym wpisie zostały poruszone tylko podstawowe tematy, których celem jest zainteresowanie Was techniką GraphQL. Jej możliwości są daleko szersze, może być wykorzystywana również do modyfikacji danych (zwanych mutacjami).
GraphQL rozwiązuje też kilka problemów, na które natrafiamy przy API REST, szczególnie w rozproszonym świecie mikroserwisów. API może stopniowo ewoluować, mogą dochodzić nowe pola, a docelowy system zawsze dostanie to, co potrzebuje. Dane zwrócone w ramach jednego zapytania może być także agregowane z wielu mikroserwisów.
O tym, jak ważny i popularny staje się GraphQL, może świadczyć wpis dostępny w momencie publikacji tego artykułu na głównej stronie najbardziej uznanego radaru technologicznego ThoughtWorks. Technika ta została polecona do wdrażania przez zespoły programistyczne.
A więc do dzieła!