Generowanie raportów w aplikacjach - jak uporządkować kod

Obsługa generowania raportów jest powszechnie obecna w wielu systemach i aplikacjach. Większość programistów miało choć raz styczność z kodem odpowiedzialnym za tworzenie zbiorczych zestawień w Excelu czy zrzutów danych do pliku CSV. Jednocześnie, zdarzało się zapewne, że kod który zastaliśmy (lub też stworzyliśmy), był nieczytelny, łamał zasady SOLID lub DRY, czy też pozbawiony był jakichkolwiek wzorców obiektowych.
Przyczyna takiego stanu rzeczy zazwyczaj tkwi w założeniach projektowych. W projekcie - już na jego początku - powstaje zapotrzebowanie na wygenerowanie jednego lub kilku raportów. Na tym etapie powinno nastąpić planowanie kodu - w jaki sposób obsłużyć wiele raportów w przyszłości (nie tylko tych, które musimy dodać w tej chwili), a zatem jaką warstwę abstrakcji utworzyć, aby zostawić po sobie kod czytelny, przejrzysty i łatwy w utrzymaniu.
Zwykle jednak (z wielu różnych przyczyn, mniej lub bardziej zasadnych) decydujemy się na rozwiązanie “na szybko”, wrzucając logikę w jedną klasę wywoływaną asynchronicznie przez joba/workera, tym samym tworząc (już na samym starcie!) dług technologiczny. W tym artykule postaram się przedstawić uniwersalne rozwiązanie, by ułatwić zapanowanie nad raportami, zarówno w projektach istniejących, jak i na początku ich biegu.
Przykładowy problem w projekcie
Dobrym case study na przeprowadzenie refaktoryzacji był jeden z projektów, przy którym pracowałem. Aplikacja była rozwijana przez 9 lat, głównie hobbystycznie i przez osoby początkujące. Raporty były dla klienta bardzo istotne, jednak przy ich tworzeniu często występowały błędy (głównie przez braki w danych), a modyfikacja ich zawartości wiązała się z wieloma godzinami analizowania starego i nieczytelnego kodu. Zamiast jednak dodawać kolejne linijki do nieczytelnego kodu, postanowiliśmy zrefaktoryzować raporty i przy okazji wychwycić wszelkie błędy.
Każdy raport wyglądał podobnie w swej konstrukcji, różnił się jednak poziomem skomplikowania i ilością zagnieżdżeń. Wybierając dość prosty przykład:
class SomeCSVWorker
include Sidekiq::Worker
sidekiq_options queue: 'package_import'
def perform(id)
# poprzednio zaimplementowana klasa do zapisywania raportów
export = Export.find(id)
require 'csv'
csv_file = ''
# logika do generowania CSV
# przypisanie nagłówków
csv_file << CSV.generate_line(%w[ID Some Attributes])
# generowanie danych z przykładowej tabeli
SomeResource.where('created_at >= ?', Time.now - 1.month).each do |res|
csv_file << CSV.generate_line([res.id, res.some. res.attributes])
end
# generowanie pliku tymczasowego
file_name = Rails.root.join('tmp', 'resource-name_timestamp.csv')
File.open(file_name, 'wb') do |file|
file.puts csv
end
# upload pliku na S3
s3 = Aws::S3.new
key = File.basename(file_name)
file = s3.buckets['bucket-name'].objects["csvs/#{key}"].write(file: file_name)
file.acl = :public_read
# zapisanie ścieżki do pliku raportu w bazie danych
export.update(file_path: key)
end
end
Jak możemy zauważyć, cała logika generowania raportu odbywa się w kodzie workera Sidekiq. Niesie to za sobą kilka konsekwencji:
- Zasada DRY (Don’t Repeat Yourself) jest tutaj naruszona kilka razy - mamy powtarzalny kod odpowiedzialny za dodanie raportu na bucket S3, wygenerowanie go czy zaktualizowanie instancji w ActiveRecord
- Podobnie jest z zasadą pojedynczej odpowiedzialności (Single responsibility principle) - worker powinien być odpowiedzialny tylko za wykonanie pewnej czynności asynchronicznie, nie zaś definiować logikę tego działania
- Zasada otwarty-zamknięty (open-closed) także jest naruszona - logika raportów jest otwarta na modyfikacje
Z powyższych kwestii wynika pierwszy podstawowy problem - zmiana pojedynczego kroku algorytmu powoduje ogromne zmiany we wszystkich plikach. Przykładowo, implementacja innego sposobu na generowanie pliku CSV (taka jak przejście na inną bibliotekę), wymaga od programisty zmiany tych samych linijek we wszystkich plikach z raportami. Co więcej, załóżmy że zmienimy w jakiś sposób tabelę Export, np. Kolumnę file_path - ponownie, zmiana musi dotyczyć dużej ilości plików, a co za tym idzie - mamy większe szanse na zepsucie czegoś po drodze.
Na ten moment wiemy więc, że istnieje kilka fragmentów kodu, które możemy przenieść do wyższych warstw abstrakcji, a także należałoby przenieść logikę raportów do osobnej klasy, np. umieścić ją w serwisie.
Zaplanowanie refaktoryzacji
Wykorzystując poprzednie rozważania, zastanówmy się, jak mógłby wyglądać serwis odpowiedzialny za generowanie raportów. Na razie, rozważamy tylko raporty CSV (do wyższej abstrakcji dotrzemy później), więc użyjmy klasy:
# frozen_string_literal: true
class CsvReportGeneratorService
def initialize(export:)
@export = export
end
def generate
write_to_csv_file
upload_report_to_s3
update_export_path
end
private
attr_accessor :export
def write_to_csv_file; end
def upload_report_to_s3; end
def update_export_path; end
end
To pozwala nam na utworzenie testu:
describe CsvReportGeneratorService do
# W projektach używamy VCR do obsługi S3 w środowisku testowym
# niemniej jednak, możemy też używać połączenia mocków z RSpec
# i predefiniowanych danych w pliku
describe '#generate', :vcr do
# Kod poniżej ma raczej charakter poglądowy
let(:export) { create :export }
let(:csv_generator) { CsvReportGeneratorService.new(export: export) }
let(:client) { Aws::S3::Client.new }
let(:report_file) { client.get_object export.file_path }
let(:csv_file_data) { CSV.parse report_file }
let(:csv_expected_data) { [] } ## Tutaj możemy zdefiniowac, jakie konkretne dane są oczekiwane
before { csv_generator.generate }
it 'generates report' do
expect(report_file).not_to be_nil
expect(csv_file_data).to eq csv_expected_data
end
end
endDzięki temu, nasz Worker może zostać zrefaktoryzowany do kodu:
class CsvReportGeneratorWorker
include Sidekiq::Worker
sidekiq_options queue: 'reports'
def perform(id)
export = Export.find(id)
csv_generator = CsvReportGeneratorService.new(export: export)
csv_generator.generate
end
endDo którego możemy napisać test:
describe CsvReportGeneratorWorker do
describe 'worker queueing' do
let(:report_generator_worker) { CsvReportGeneratorWorker.perform_async }
it 'enqueues the job' do
expect { report_generator_worker }.to change(CsvReportGeneratorWorker.jobs, :size).by 1
end
end
endZastanówmy się przez chwilę nad dalszą implementacją. To, jak miałaby wyglądać docelowa struktura, możemy pokazać na schemacie poniżej:
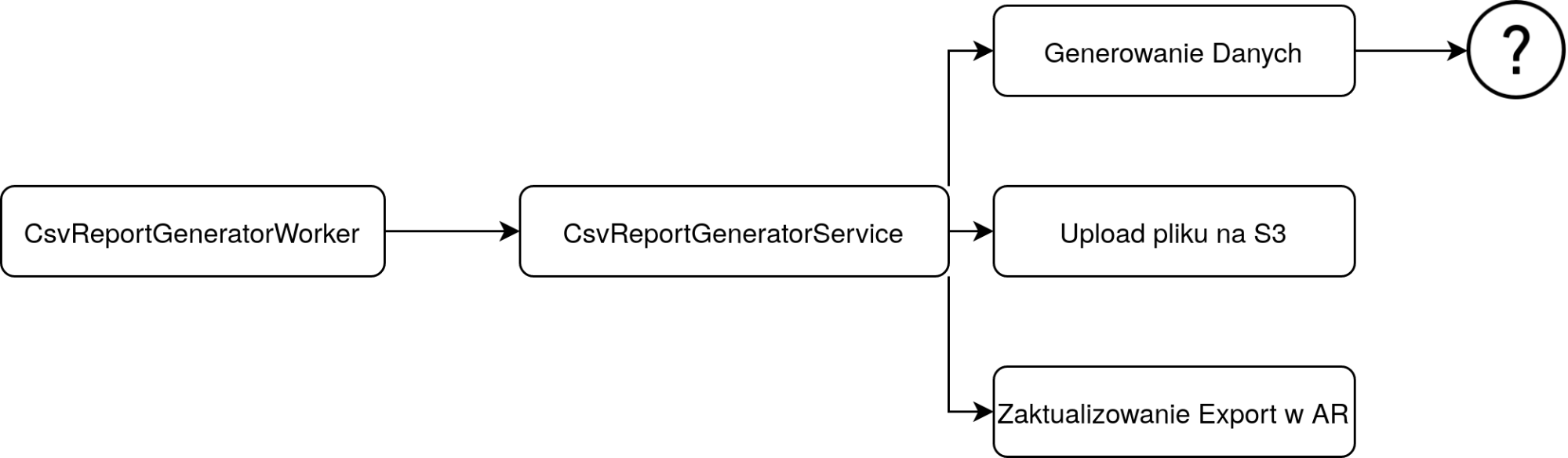
Wrzucenie pliku na S3 oraz aktualizacja rekordu Export będzie wyglądać tak samo dla każdego z raportów - możemy więc uznać, że logika odpowiedzialna za wykonanie tych funkcji będzie współdzielona. Natomiast oczywistym jest, że raporty będą na ogół generowały inne dane (a także po innych filtrach) i to będzie przedmiotem dalszych rozważań.
Aby napisać kod odpowiedzialny za generowanie danych do raportu, wybrałem trzy wzorce projektowe, które mogą w tym pomóc.
Metoda szablonowa
Metoda Szablonowa jest bardzo często spotykana w języku Ruby i umożliwia hermetyzację części kodu, zgodnie z zasadą DRY. Wzorzec ten pozwala zdefiniować szkielet algorytmu (klasa nadrzędna) i pozostawić implementację poszczególnych kroków klasom dziedziczącym.
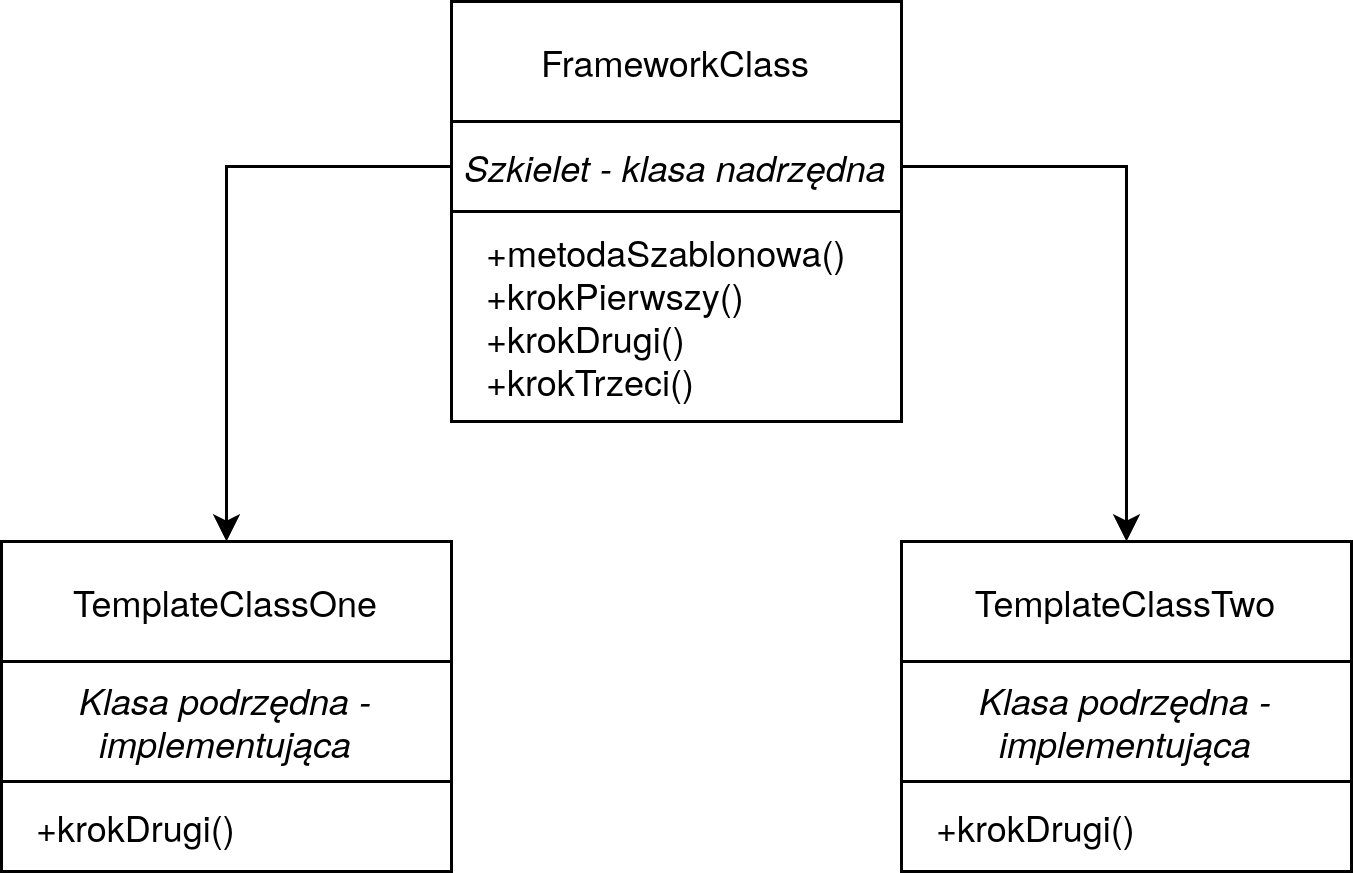
Z perspektywy refaktoryzacji raportów, metoda ta pozwoli na zhermetyzowanie części odpowiedzialnej za generowanie danych do CSV.
Fabrykacja
Fabrykacja to wzorzec kreacyjny pozwalający na tworzenie obiektów różnych klas za pomocą zdefiniowanego interfejsu bez ujawniania ich logiki. Innymi słowy, za pomocą jednej klasy bazowej mamy możliwość tworzenia poszczególnych klas implementujących dany krok/algorytm - w tym przypadku, będzie to kod odpowiedzialny za generowanie danych.
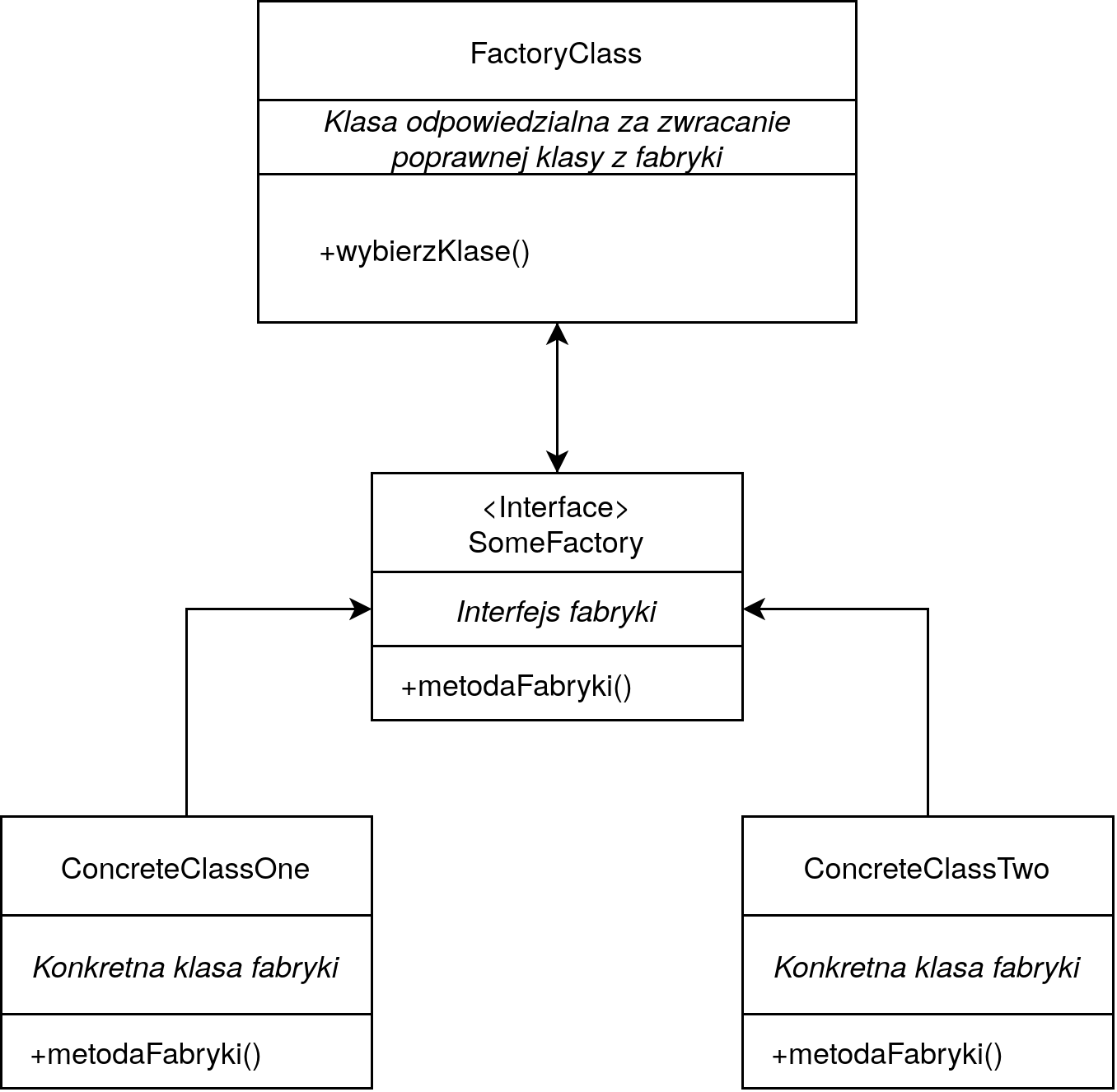
Wzorzec strategii
Jeśli programujesz w Ruby on Rails, być może miałeś do czynienia z gemem Pundit do zarządzania uprawnieniami w aplikacji. Do tworzenia uprawnień wykorzystywany jest właśnie wzorzec strategii (Strategy Pattern lub też Policy Pattern), który bazuje na kompozycji. Umożliwia on kapsułkowanie (zamknięcie) algorytmu w danych klasach, zwanych strategiami. Poszczególne strategie mogą być wywołane za pomocą kontekstu.
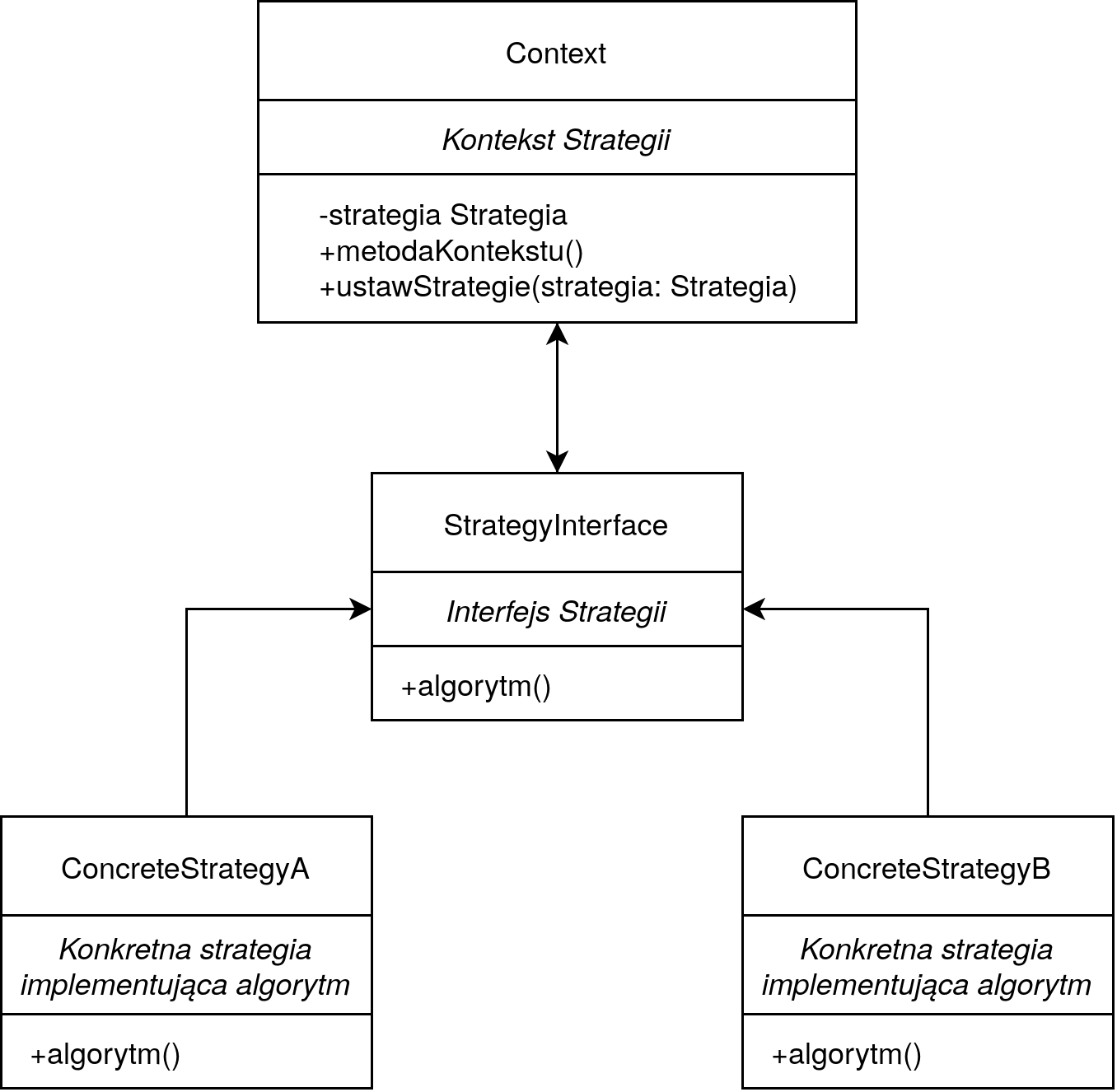
Różne typy raportów mogą stanowić konkretne strategie i implementować generowanie danych do raportu.
Wdrażanie rozwiązania
Warianty rozwiązań.
Metoda szablonowa
Zacznijmy od napisania testu, który na koniec powinien wykonać się poprawnie:
describe SomeReport do
describe '#generate_report' do
let(:csv_data) { [] } # mozemy podać dane do CSV jako pustą tablicę
# Zakładamy, że nasz raport będzie miał za zadanie generować poniższe dane
let(:expected_data) { [['headers'], ['report_body']] }
let(:report_class) { SomeReport.new(csv_data) }
before { report_class.generate_report }
it 'generates correct data' do
expect(csv_data).to eq expected_data
end
end
endOczekujemy, że klasa SomeReport ostatecznie zwróci dane w expected_data które będziemy mogli zapisać do raportu. Zdefiniujmy zatem szablon:
class TemplateClassCsv
def initialize(csv)
@csv = csv
end
def generate_report
add_headers
add_report_rows
end
private
attr_accessor :csv
def add_headers
raise NotImplementedError
end
def add_report_rows
raise NotImplementedError
end
endZgodnie ze wzorcem szablonu, każda klasa dziedzicząca po TemplateClassCsv będzie implementować swoje nagłówki i zawartość raportu (może docelowo również implementować swoją metodę generate_report). Dla naszego przykładowego raportu otrzymujemy:
class SomeReport < TemplateClassCsv
private
def add_headers
csv << ['headers']
end
def add_report_rows
csv << ['report_body']
end
end
W tym momencie nasz test jest “zielony”, a każdy kolejny raport możemy oddawać w analogiczny sposób. Warto zaznaczyć, że aby w tym momencie użyć klasy w naszym serwisie mamy dwie opcje:
- Dodać logikę odpowiedzialną za tworzenie raportu i upload na bucket S3 do
TemplateClassCsv, a następnie dany raport wywoływać za pomocą klasy dziedziczącej, co wykona kroki algorytmu w poprawny sposób, ale jednocześnie naruszy zasadę pojedynczej odpowiedzialności - Dodać mapper, który na podstawie klucza raportu (
report_key) wywoła odpowiednią klasę dziedziczącą, co natomiast można również osiągnąć przy pomocy fabrykacji w bardziej - moim zdaniem - czytelny sposób.
Fabrykacja
Ponownie, rozpoczynamy od napisania testu. Wzorzec fabrykacji wymaga abyśmy rozpoczęli implementację od stworzenia fabryki, odpowiedzialnej za tworzenie konkretnych klas raportów. Aby zachować czytelność kodu, uznajmy, że docelowo metoda odpowiedzialna za tworzenie klasy na podstawie klucza raportu będzie nosić nazwę for:
describe CsvReportFactory do
describe '.for' do
context 'some_report' do
let(:report_key) { :some_report }
let(:expected_report_class) { SomeReport }
it 'returns correct class' do
expect(CsvReportFactory.for(:some_report)).to eq SomeReport
end
end
end
end
Należy również przetestować samą funkcjonalność raportu, jednak możemy do tego użyć poprzedniego testu - nasza fabryka zwraca klasę SomeReport, która również będzie generować raport za pomocą metody generate_report. Implementacja fabryki jest natomiast bardzo prosta:
class CsvReportFactory
# poniższe mozemy docelowo przeniesc do innej klasy, np CsvReportErrors
# i zmienic dziedziczenie na CsvReportErrors < StandardError oraz
# NoReportKeyProvided < CsvReportErrors
class NoReportKeyProvided < StandardError; end
def self.for(key)
raise NoReportKeyProvided if key.blank?
key.classify.constantize
end
endKlasa SomeReport może być teraz wywołana w serwisie za pomocą:
class CsvReportGeneratorService
def initialize(export:)
@export = export
end
def generate
write_to_csv_file
upload_report_to_s3
update_export_path
end
private
attr_accessor :export
def write_to_csv_file
CSV.generate do |csv|
report_generator_class = CsvReportFactory.for(export.key).new(csv)
report_generator_class.generate_report
end
end
def upload_report_to_s3; end
def update_export_path; end
endWzorzec strategii
Na drodze refaktoryzacji kodu, napotkałem się również ze wcześniej wspomnianym wzorcem strategii, który również może posłużyć do obsługi raportów. Implementację również rozpoczynamy od testów - tym razem potrzebujemy kontekstu obsługującego dobór odpowiedniej strategii oraz konkretnej strategii wykonującej nasz raport:
describe CsvReportContext do
describe '#determine_strategy' do
context 'some_report' do
let(:report_key) { :some_report }
let(:csv_report_context) { CsvReportContext.new(report_key) }
let(:strategy_class) { csv_report_context.determine_strategy }
it 'returns correct strategy class' do
expect(strategy_class).to eq SomeReportStrategy
end
end
end
end
describe SomeReportStrategy
describe '.generate_report' do
let(:csv_data) { [] }
let(:expected_data) { [['headers'], ['report_body']] }
before { SomeReportStrategy.generate_report(csv_data) }
it 'generates correct data' do
expect(csv_data).to eq expected_data
end
end
endPo architekturze rozwiązania oczekujemy, że kontekst na podstawie klucza raportu zwróci odpowiednią strategię implementującą metodę generate_report, która jako argument pobiera tablicę i wpisuje do niej dane. Rozpoczynając od kontekstu:
class CsvReportContext
def initialize(report_key)
@report_key = report_key
end
def determine_strategy
report_key_based_strategy
end
private
attr_accessor :report_key
def report_key_based_strategy
raise NoReportKeyProvided if report_key.blank?
case report_key
when :some_report then SomeReportStrategy
when :other_report then OtherReportStrategy
else raise InvalidReportKey
end
end
endMożemy przejść do implementacji strategii:
class SomeReportStrategy
# autor celowo używa metod klasowych zamiast instancyjnych
# żeby lepiej pokazac zamiary wzorca strategii
# natomiast używanie metod instancyjnych i konstruktora jak
# najbardziej funkcjonowałoby poprawnie
def self.generate_report(csv)
add_headers(csv)
add_report_rows(csv)
end
def self.add_headers(csv)
csv << ['headers']
end
def self.add_report_rows(csv)
csv << ['report_body']
end
endPowyższy kod w serwisie wygląda następująco:
class CsvReportGeneratorService
def initialize(export:)
@export = export
end
def generate
write_to_csv_file
upload_report_to_s3
update_export_path
end
private
attr_accessor :export
def write_to_csv_file
CSV.generate do |csv|
report_strategy = CsvReportContext.new(export.key).determine_strategy
report_strategy.generate_report(csv)
end
end
def upload_report_to_s3; end
def update_export_path; end
endOstatecznie, w projekcie został zastosowany wariant z fabrykacją, co było wymuszone przez zaplanowaną przez zespół architekturę docelową (raporty o różnych rozszerzeniach w jednym serwisie). Na ten moment, uzyskaliśmy czytelny serwis do obsługi raportów CSV:
class CsvReportGeneratorService
def initialize(export:)
@export = export
end
def generate
write_to_csv_file
upload_report_to_s3
update_export_path
end
private
attr_accessor :export, :path, :csv
def write_to_csv_file
CSV.generate do |csv|
report_generator_class = CsvReportFactory.for(export.key).new(csv)
report_generator_class.generate_report
@csv = csv
end
end
def upload_report_to_s3
# uploader został zrefaktoryzowany również, docelowo zwraca klucz
# pliku na buckecie S3
s3_uploader = CsvReportGeneratorService::S3Uploader.new(csv)
@path = s3_uploader.upload_file_to_s3
end
def update_export_path
# na czas refaktoryzacji, klucz do S3 był przypisywany do instancji
# Export i przekazywany w kontrolerze do linku do pobrania
# Następnym krokiem było wprowadzenie domyślnego uploadu za pomocą
# paperclipa
export.update(status: :finished, file_path: path)
end
endKod stał się uniwersalny i czytelny, natomiast ilość workerów została ograniczona do jednego, utworzonego na samym początku naszej refaktoryzacji - odpowiadający mu test świeci się na zielono, a refaktoryzacja jest zakończona. Na razie.
Podsumowanie
Dzięki refaktoryzacji uzyskaliśmy:
- Uniwersalne zastosowanie - powyższą logikę stosować można w różnych projektach i na różnym etapie ich żywotności
- Czytelność kodu i trzymanie się dobrych praktyk - nasz serwis ma około 50 linii kodu, trzymanych w jednym (a nie kilkunastu) pliku.
- Plan na przyszłość - dzięki podejściu krok po kroku wiemy, jak refaktoryzować kod raportu na różnych etapach projektu, dla różnych rozmiarów kodu
- Proste rozwiązanie kolejkowania - niezależnie czy używamy Resque czy Sidekiqa, nasz główny worker i dziedziczące po nim workery (dla poszczególnych raportów) mogą wyglądać następująco:
class ReportGeneratorWorker
include Sidekiq::Worker
def perform(id)
# warto odnotować, że do tej pory operowaliśmy na tabeli Export
# aby uniknąć modyfikowania Active Record
# kolejnym krokiem powinna być zmiana nazwy klasy Export i tabeli exports
# na bardziej powiązaną z raportami i zaktualizowanie serwisu.
report = Export.find(id)
csv_generator = CsvReportGeneratorService.new(export: export)
csv_generator.generate
end
end- Dowolność implementacji przy zachowaniu abstrakcji i zasady otwarty-zamknięty - każda z klas może być modyfikowana dowolnie (w zakresie funkcjonalności danej biblioteki dla danego rozszerzenia raportu), nie wpływając na implementacje i funkcjonowanie innych klas
- Możliwość implementacji widoków SQL (często zapomnianych) - które pozwalają przyspieszyć generowanie raportów (w naszym przypadku trzymanie indeksowanych widoków pomogło skrócić czas generowania o ok. 20% przy dużych raportach)
- Niski próg wejścia, a co za tym idzie, niższe koszty dla klienta - programista rozpoczynający pracę nad raportami (po zapoznaniu się z ich implementacją) przy dodawaniu nowego raportu musi jedynie dopisać swoją klasę odpowiedzialną za generowanie danych, po uprzednim przygotowaniu odpowiedniego testu.
O autorze
Michał Zynek programuje komercyjnie w Ruby on Rails od niemal 4lat, choć ma za sobą także rok doświadczenia jako VB.NET Developer. Tworzył projekty dla wielu branż, między innymi finansowej czy e-commerce. Oprócz zainteresowania backendem stale zdobywa nowe skille w technologiach frontendowych (głównie React.js).