

Hesham MeneisiSenior Data EngineerCREA
Dlaczego nie umiemy estymować czasu ukończenia oprogramowania
Sprawdź, co stoi za złym wyznaczaniem deadline’ów w projektach software’owych i jak można dokonać lepszej estymacji czasu ukończenia danego programu.
Pomówmy o statystycznym podejściu do źle wyznaczonych deadlinów w projektach inżynieryjnych. Niezależnie od tego, czy jesteś juniorem, seniorem, PMem, czy wysoko postawionym menedżerem z 20-letnim doświadczeniem, estymacja czasu ukończenia danego projektu nie jest prostym zadaniem. Nawet największy geniusz nie jest w stanie przewidzieć, kiedy oprogramowanie będzie gotowe.
Problem ten jest powszechny w inżynierii oprogramowania, ale w innych dziedzinach również ciężko jest sobie z tym poradzić. W tym artykule skupimy się na tworzeniu software’u, ale postawiona tutaj teza w jakimś stopniu odnosi się również do innych dziedzin.
Przyglądamy się problemowi
Przedstawimy tutaj ogólny zarys problemu, razem z konsekwencjami i podstawowymi przyczynami.
Problem
Projekty polegające na rozwoju oprogramowania rzadko kończą się przed deadlinem.
Konsekwencje
Praca marketingu pójdzie na marne, klienci będą niezadowoleni, zestresowani developerzy w pośpiechu będą pisać słaby kod, co może zaszkodzić produktowi i doprowadzić do anulowania projektu.
Przyczyny
- Nieprawidłowe oszacowanie czasu
- Niejasne wymagania na początku projektu oraz późniejsza ich zmiana
- Gold-plating- zbyt duże skupienie się na szczegółach, które nie są ważne dla projektu
- Zbyt mało czasu poświęcono na research i projekt architektury. Zaszkodzić tutaj też może poświęcenie na powyższe zbyt wiele czasu
- Niezwrócenie uwagi na potencjalne problemy, mogące wyniknąć z integracji narzędzi zewnętrznych
- Chęć zrobienia wszystkiego dobrze za pierwszym razem
- Praca nad innymi projektami, co skutkuje rozproszeniem
- Brak balansu między jakością a wydajnością
Zbytni optymizm, Efekt Dunninga-Krugera, niepewność losu, czy czysta matma?

Etap 5: Akceptacja
Łatwo jest bagatelizować problem zbytniego optymizmu, ponieważ developer, który nie mógł czegoś zrobić na czas, nie będzie raczej optymistą. Może się zdarzyć, że kierownictwo projektu nie ma backgroundu technicznego i ustalają terminy, nie wiedząc, co robią. Ten przypadek to temat na osobny artykuł.
Niektórzy przypisują nieprawidłowe oszacowanie czasu Efektowi Dunninga-Krugera, ale jeśli brak doświadczenia lub przecenienie swoich sił stoi za wyznaczeniem zbyt szybkiego deadline’u, to większe doświadczenie powinno tutaj pomóc, prawda? Największe firmy z niekończącymi się zasobami nadal mają wysoki współczynnik przedłużonych deadline’ów - większe doświadczenie niewiele więc tutaj pomoże.
Już nie wspomnę o tym, że każdy z nas tego kiedyś doświadczył - w takiej, czy innej formie. Doświadczenie rzadko pomaga w przypadku szacowania czasu. Większość developerów, zwłaszcza Ci bardziej doświadczeni, szybko dochodzą do wniosku, że za tym wszystkim stoi po prostu niepewność losu.
Można wtedy po prostu powiedzieć: „no tak to już w życiu jest”, postarać się sprostać oczekiwaniom klientów i mówić developerom, aby jakoś radzili sobie w trudnych sytuacjach. Wszyscy znamy ten stres, słaby kod i totalny chaos, który tworzy się przez taką filozofię.
Czy na to szaleństwo istnieje jakieś lekarstwo? Czy to naprawdę najlepszy sposób na kończenie rzeczy?
Osobiście nie wydawało mi się to prawdopodobne. Zacząłem wiec szukać racjonalnego wytłumaczenia, dlaczego tylu inteligentnych ludzi nie jest w stanie mniej więcej przewidzieć, kiedy skończą projekt.
Czysta matma
Pewnego dnia robiłem zadanie, które powinienem był skończyć w 10 minut… a zajęło mi 2 godziny. Zacząłem się zastanawiać, dlaczego to wszystko się tak rozciągnęło. Oto mój proces myślowy:
- Dokładnie wiedziałem, jaki kod mam do napisania - dlatego 10 minut
- I rzeczywiście - 7-10 minut i kod był gotowy. 2 godziny zajęła mi walka z błędem we frameworku, o którym nie wiedziałem.
Niektórzy określają to mianem siły wyższej. Wydaje się Wam pewnie, że można to podciągnąć pod niepewność losu - i tak i nie. Przyjrzymy się temu dokładniej.
Niepewność losu jest tutaj podstawową przyczyną - nigdy bym nie zgadł, że we frameworku był taki błąd. Czy powinien się on jednak przyczynić się do opóźnień w całym projekcie?
Nie. Trzeba tutaj powiedzieć sobie jasno - jedno zadanie nie jest dobrą reprezentacją całego projektu (i vice versa).
Jak szacuje się czas w rozkładzie normalnym?
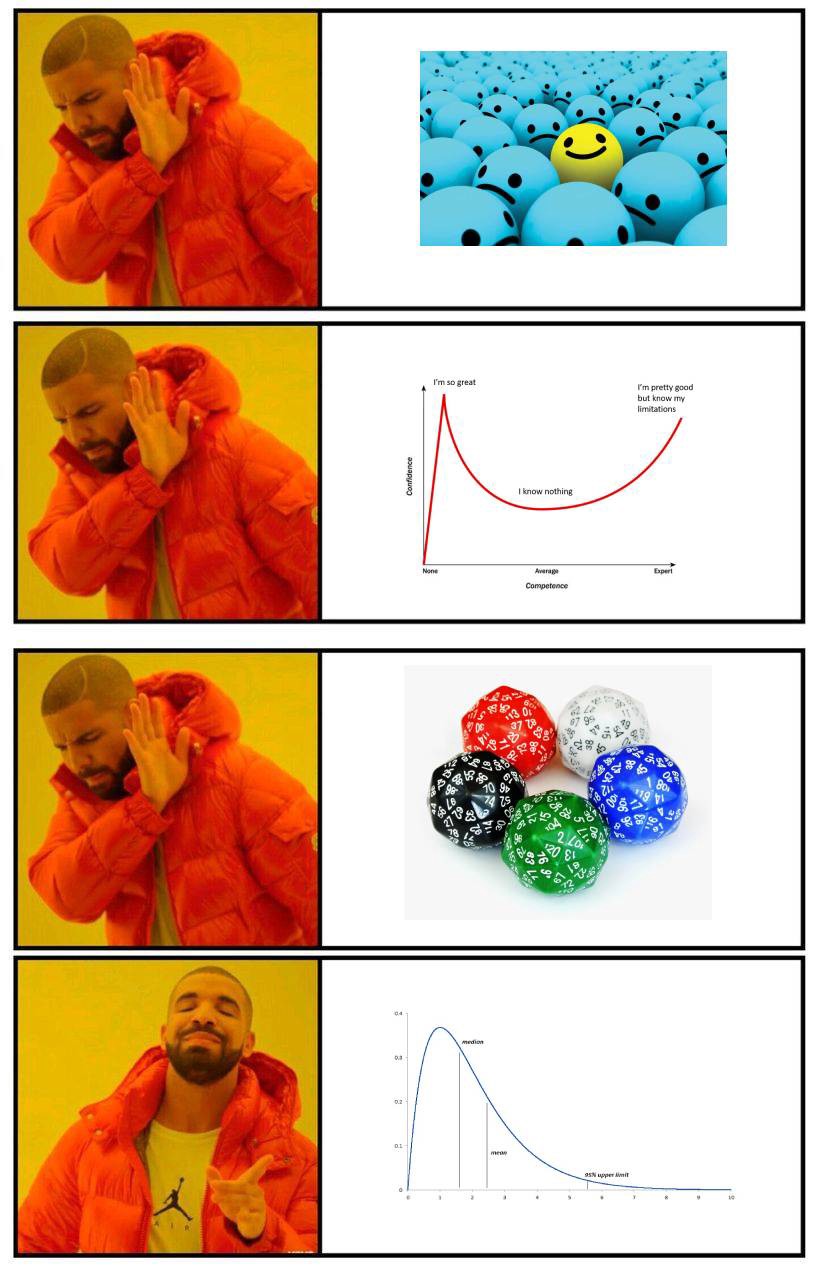
 Rozkład normalny (krzywa dzwonowa)
Rozkład normalny (krzywa dzwonowa)
Człowiek jest przyzwyczajony do rozkładu normalnego - bardzo dobrze idzie nam estymowanie rzeczy, które rozkładają się w naturze w sposób normalny. Tak właśnie zdobywa się doświadczenie - przez wystawienie się na jakąś sytuację.
Weźmy pod uwagę taki scenariusz: chodzisz do najbliższej Żabki jakieś 20 razy w miesiącu i za każdym razem zajmuje Ci to 5 minut, pomijając ten jeden raz, kiedy zepsuła się winda i jeden, kiedy lało jak z cebra.
Myślisz, że ile czasu zajmie Ci dotarcie tam kolejnym razem? 5 minut? 15 minut też ma sens, ale to raczej mało prawdopodobne. 7 może być, no, chyba że pada.
Jeśli 18 razy z tych 20 razy dotarło się do Żabki w 5 minut, to istnieje bardzo duża szansa, że dojście do tego sklepu zajmie nam właśnie te 5 minut i kolejnym razem (mediana) - 90% szansy (bez wchodzenia w bardziej złożone obliczenia).
Chodzi o pochylenie
Bycie dobrym w szacowaniu czasu wykonania projektu, nie oznacza, że będziemy mieli rację. Wbrew pozorom możemy się nawet bardziej mylić. Ci, którzy interesują się matmą (ewentualnie data science/statystyką), być może już zauważyli, że graf na poprzednim memie to rozkład normalny pochylony w prawo. Dla wyjaśnienia:
Mediana jest bardziej prawdopodobna, niż średnia, jeśli mówimy o pojedynczym zadaniu. Gdybyście odgadli wartość dominanty, która ma największe prawdopodobieństwo, to pomylilibyście się jeszcze bardziej i to na większą skalę.
Widzicie, co może pójść nie tak?
Nasze „naturalne” przypuszczenie opiera się na medianie, która maksymalizuje prawdopodobieństwo, jednak rzeczywista liczba, gdy nasze „zdarzenie” wystąpi wystarczająco dużo razy, zawsze będzie zbliżać się do średniej. Innymi słowy: im więcej wykonujesz podobnych zadań, tym łatwiej przy estymacji.
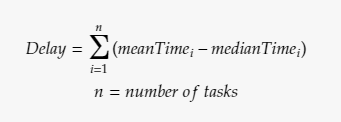
Równanie opóźnienia, według naszej powyższej hipotezy
Zadania programistyczne w projekcie są z reguły do siebie podobne, albo pogrupowane w kilka podobnych grup. Powyższe równanie implikuje, że ten problem skaluje się wraz ze wzrostem liczby zadań. Kiedy chcemy, aby wszystko się dobrze skalowało, to takie problemy nie są mile widziane.
Jak wykorzystać tę wiedzę?
Będąc całkowicie szczerym, nie chciałem tutaj dawać żadnych instrukcji. Miała to być po prostu analiza problemu, a hipotezę mogliście wysunąć sami.
Wielu z Was byłoby pewnie zawiedzionych takim obrotem spraw, więc poniżej przedstawiam sposoby na możliwie jak najlepszą estymację deadline’ów.
- Łatwiej jest stwierdzić, czy zadanie X zajmie więcej/mniej czasu, zestawiając je z zadaniem Y - nie starajcie się dokładnie określać czasu, w którym możecie skończyć oba zadania. A to dlatego, że porównywanie median da podobne rezultaty do porównywania średnich, jeśli pochylenie krzywych jest mniej więcej takie samo (tak właśnie jest w przypadku podobnych zadań).
- Szacuję nieunikniony błąd (średnia-mediana) jako procent czasu wykonania zadania, który rośnie/maleje w zależności od tego, jak dobrze czuję się w środowisku deweloperskim (czy dany język/framework mi się podoba? (40%), czy mam dobre narzędzia do debugowania (30%) i dobrą obsługę IDE (25%) itd.)
- Zacząłem dzielić sprinty na zadania o jednakowej wielkości, aby uzyskać pewną jednolitość w procesie szacowania czasu. Pozwala mi to czerpać korzyści z punktu 1. Być może będziemy mogli łatwo stwierdzić, czy na dwóch zadaniach spędzimy mniej więcej tyle samo czasu. Sprawia to również, że zadania są jeszcze bardziej podobne, dzięki czemu moja hipoteza ma jeszcze lepsze zastosowanie, a rzeczy stają się bardziej przewidywalne.
- Po zastosowaniu powyższych zasad możesz przeprowadzić „jazdę próbną” - jeśli masz odpowiednie zasoby. Na przykład, jeśli w ciągu X1 dni z programistami Y1 ukończono Z1 podobnych zadań, to możemy skończyć je w X2 (dni), biorąc pod uwagę, że znamy Y2 (dostępni programiści) i Z2 (całkowita liczba zadań, które mamy jeszcze do zrobienia).
Mam nadzieję, że powyższy artykuł Wam pomoże. Dziękuję za uwagę!
Oryginał tekstu w języku angielskim możesz przeczytać tutaj.
