

Grzegorz GwardysLead Data ScientistPromity
Data Thinking - dużo szumu o nic, czy konieczność?
Dowiedz się, czy Data Thinking jest koniecznością, dlaczego 85% przedsięwzięć opartych na AI kończy się niepowodzeniem oraz jak zwiększyć prawdopodobieństwo sukcesu w tym temacie.
Można się spotkać z wieloma dyskusjami na temat definicji AI, np. w tym wątku na Quora można się spotkać z takimi stwierdzeniami jak: “Cool things that computers can't do", czy “Anything that is both artificial and intelligent”. Pole do rozważań jest szerokie, a rozwiązanie tego sporu z pewnością pomoże w odpowiedzi na pytanie czemu 85% projektów AI kończy się niepowodzeniem - może zwyczajnie nie mówimy o AI i współczynnik porażek jest znacznie niższy? A może z 15% sukcesów, 14% nie ma nic wspólnego z “cool things” i porażek jest 99%?
Temat definicji sukcesu i porażki jest ciekawy sam w sobie, niemniej w tym artykule chciałbym poruszyć temat sposobu na zwiększenie prawdopodobieństwa tego zamieszkującego krainę Oz sukcesu, czyli na wokandę wchodzi Data Thinking, zróbmy trochę szumu!
Rozwiązanie czy populizm?
O definicję populizmu jest łatwiej niż ma to miejsce w przypadku AI, niemniej posłużę się swoim rozumieniem tego terminu: populizm utożsamiam z osiągnięciem celu (np. sprzedażowego) poprzez schlebianie np. klientom i poprzez składanie nierealnych obietnic. W przypadku naszych 85% porażek AI, też widzimy bardzo dużo obietnic, nierealnych w tym sensie, że wystarczy “tylko” zadbać o:
- Data Quality
- Zastąpienie Data silo przez Data lake
- Pozyskanie TOP-PhD AI Talentów (czy to w ramach rekrutacji, czy jako outsourcing firmy)
- Metodykę prowadzenia projektów innowacyjnych
I już można się witać z gąską i znaleźć się w zaszczytnym gronie 15%. Niestety, ale tak jak sama obniżka podatków lub wprowadzenie nowych nie jest wystarczające, aby odpowiedzieć na wszystkie wyzwania publiczne, tak wybierając pojedynczą tabletkę z wymienionych wyżej, z dużym prawdopodobieństwem nie uzdrowimy naszej sytuacji na tyle, by móc trafić do elitarnego klubu 15%. Oczywiście marketing rządzi się swoimi prawami, specjaliści tej dziedziny sprzedają marzenia i nie ma tu się o co gniewać. Niemniej, musimy być świadomi zasady “no silver bullet” i tego, że przedsięwzięcia AI potrafią być skomplikowane na wielu polach.
Dlatego, tak jak wszystko inne, Data Thinking o którym nie zostało jeszcze nic napisane mimo ponad 2 tys. znaków, nie jest rozwiązaniem wszystkich trosk i bolączek. W artykule dochodzi do lokowania produktu, ale ten odcinek nie opowiada o Super Bohaterze, co o pomocnym sąsiedzie zza ściany.
Data Thinking, narodziny Frankensteina
Chyba lubimy jako gatunek dokonywać syntezy, widać to w muzyce, filmie, sportach walki, Smartfonie pełniącym rolę telefonu, telewizora, komputera i konsoli do gier.
Jeśli jest coś lepszego niż hype na Data Science (znów, jeśli ktoś sobie życzy zdefiniowanego pojęcia zapraszam na ten wątek na Quora, można nawet zobaczyć stosowny diagram Venna), to dodanie do niego innego hype związanego z Design Thinking - osiągamy wtedy podwójny hype i nowy buzzword - Data Thinking.
Oczywiście, nie sposób jest streścić Design Thinking w jednym artykule, skoro tak jak o innych metodykach, zostały napisane całe książki jak np. Zmiana przez design: jak design thinking zmienia organizacje i pobudza innowacyjność autorstwa Tima Browna. Można też obejrzeć kilkuminutowe wideo (po 3:10 jest już reklama Stanforda).
Sam Design Thinking wydaje się prosty jak budowa cepa. To dobrze, bo tworzenie innowacyjnych produktów nastręcza wystarczających trudności. Oczywiście, możemy dyskutować o tym, czy Design Thinking działa, czy nie jest tak jak Pani Jen stwierdziła, że to bullsh*t, lub przeczytać artykuł, że i owszem ale to nie szkodzi: Yes, Design Thinking Is Bullshit…And We Should Promote It Anyway. Wracając do skomplikowanej budowy, fazy Design Thinking przedstawiają się następująco:
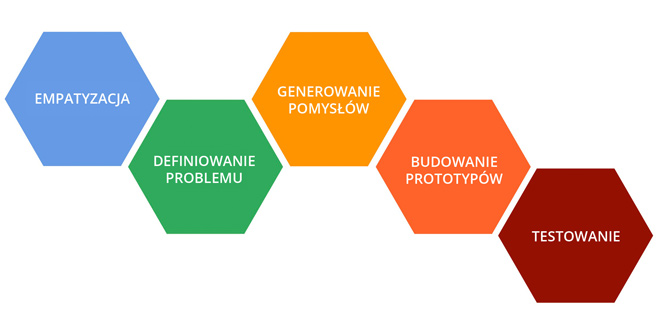 Fazy Design Thinking
Fazy Design Thinking
Uzupełnimy rysunek o kilka uwag:
- Za każdą fazą stoi zaplecze narzędzi, np. za generowaniem pomysłów kryją się rozmaite techniki burzy mózgów (m.in. 6 kapeluszy)
- O ile w Lean Start-Up mamy jakąś hipotezę, którą chcemy jak najszybciej zweryfikować, o tyle w Design Thinking mamy jeszcze fazę Empatyzacji - skoro przyszło to od Designerów, to nie dziwi jak bardzo jest to User-Centric i jaką wagę mają wywiady z użytkownikami, obserwowanie ich zachowania, tworzenie tzw. map empatii czy person

Przykład persony
- Bardzo podchwytliwa może okazać się terminologia, gdyż to co dla jednego jest prototypem rozumianym jako PoC (ang. Proof of Concept), w Design Thinking może być choćby posklejanym pudłem, byle miało to użyteczność weryfikacji hipotezy
 Budowanie prototypu, żródło
Budowanie prototypu, żródło
Może po omacku, ale dochodzimy do idei Data Science + Design Thinking = Data Thinking. Chcemy, by Użytkownik był w centrum. Chcemy wytworzyć rozwiązanie wychodząc od trosk Użytkownika, a nie zaczynamy z technicznym prototypem. Chcemy wypracować prototyp od początku do końca (nawet jeśli to tektura), zwracając uwagę na cały “Customer Journey”.
W końcu (i to może jest najważniejsze!) chcemy usiąść do stołu w interdyscyplinarnym zespole, gdzie każdy jest profesjonalistą, ale mówiącym w swoim, hermetycznym, języku. Cały proces Design Thinking ma pomóc w komunikacji i wzajemnym zrozumieniu. Nie, nie jest to bilet do klubu 15%, ale może nam pozwolić na stosunkowo szybkie określenie, których czynników selekcji nie spełniamy.
Niemniej, Design Thinking != Data Thinking, w przypadku tego drugiego mówimy o Data Product, czyli właściwie od początku procesu musimy kłaść olbrzymi nacisk na dane, a następnie na algorytmy Machine Learning. W kontekście interdyscyplinarności zespołu i członków nietechnicznych jest to jeszcze większe wyzwanie.
Data Thinking dzisiaj
Pytanie, które może się nasunąć, to czy w przypadku Data Thinking nie jest tak jak było kiedyś z Big Data, czy każdym innym buzzword - odnoszę się tutaj do osławionej analogii do seksu nastolatków: wszyscy o tym mówią, nikt nie wie jak to robić, wszyscy myślą że wszyscy inni to robią, więc wszyscy chwalą się 10-letnim stażem. I odpowiedź wydaje się pozytywna co najmniej z kilku powodów.
Pierwszym aspektem jest krzywa wejścia - ta metodyka ma wesprzeć osoby nietechniczne, lub techniczne ale mniej zorientowane na dane, aby mogły współtworzyć rozwiązania AI. Oczywiście łatwiej, gdy ktoś jest tym słynnym Jednorożcem, co po zwycięstwie w konkursie rozpoznawania obrazów na Kaggle przystępuje do projektowania UI/UX kolejnej aplikacji, niemniej podobnie do Design Thinking, w Data Thinking zakłada profesjonalizm w jednej dziedzinie.
Czyli sam początek może przypominać chodzenie po omacku, ale nie można tego porównywać do uczenia się Java/Scala, zestawiania klastra Hadoop czy przedzierania się przez gąszcze dostawców rozwiązań chmurowych - jesteśmy w świecie burz mózgów i klejenia kartonów.
Kolejnym aspektem jest nasza codzienna aktywność zawodowa - trudno, byśmy nie mówili w IT o testach, a w Marketingu o tworzeniu person. Burza mózgów sięga 1939 i wydaje się być powszechnie znanym narzędziem do generowania pomysłów. Krótko mówiąc, pracujemy, napotykamy podobne problemy i próbujemy je rozwiązać, dochodząc poprzez metodę prób i błędów do naszych własnych sposobów na robienie produktów. Wysoce prawdopodobne, że ktoś z czytających sam stosuje Data Thinking tylko tego nie nazwał, nie sformalizował.
Są grupy, które mocniej pochyliły się nad tematem łączenia Design Thinking i Data Science, czasem nazywając to Data Thinking, a czasem nadając inną nazwę, niemniej intencja pozostaje podobna. Zespół z Futurice zaproponował The Intelligence Augmentation Design Toolkit. Autorzy zwrócili uwagę na różnicę między AI, a Intelligence Augmentation, które w założeniu ma wspierać Użytkownika, a nie go zastępować, jak np. w przypadku self-driving cars. Toolkit ma na celu ułatwienie osobom nietechnicznym projektowanie usługi wzbogaconej o Machine Learning.
Paczka jest do ściągnięcia za darmo na licencji CC i zawiera podręcznik omawiający metodę, karty i kanwy. Dzięki kartom interakcji i kartom kanałów łatwiej jest uświadomić osoby nietechniczne o możliwościach AI wspierając początek prac koncepcyjnych. Również bardzo dobrym pomysłem jest wprowadzenie kart “unexpected bug”, sprowadzając rozpalone umysły na ziemię, wskazując potencjalne problemy.
Grupa Futurice wskazuje w podręczniku jak ważne jest rozpatrzenie problemu błędnej predykcji algorytmu Machine Learning. Jak słusznie wskazują, błąd błędowi nierówny: brak rekomendacji filmu który by się Użytkownikowi spodobał jest mniejszym problemem niż zła rekomendacja (brak rekomendacji jest dla Użytkownika niewidoczny).
Zaproponowanym tu narzędziem jest kanwa “Confusion Matrix”. Drugą kanwą jest “Smart Service Storyline”, które pełni rolę wizualnego streszczenia naszego produktu. Wśród kolumn można zobaczyć potrzebę klienta, wartość dodaną poprzez Machine Learning, czy kluczowy “Touchpoint”, podczas którego Użytkownik korzysta z naszego rozwiązania. Zarówno w kanwie, jak i w podręczniku pojawił się temat dot. pętli uczenia. Nie musi to być w kontekście naszego produktu coś złego, ale należy mieć na uwadze, że jeśli interakcje użytkowników stanowią zbiór treningowy dla naszych algorytmów Machine Learning, to dochodzimy do problemu bańki - skoro Użytkownik polubił artykuł o danej narracji politycznej, to po dotrenowaniu algorytmu Machine Learning, jeszcze więcej podobnych artykułów będzie rekomendowanych temu użytkownikowi, powodując przeświadczenie kompletnej racji.
W razie diagnozy takiego zjawiska na warsztacie, można już podjąć wstępne kroki mitygujące te ryzyko i główny aspekt ująć na kanwie “Smart Service Storyline”.
Autorzy The Intelligence Augmentation Design Toolkit nigdzie nie piszą o Data Thinking, niemniej z mojej perspektywy jest to jak najbardziej właściwy przykład tej filozofii. Mimo wszystko jest kilka brakujących aspektów. Nie znajdziemy w podręczniku konkretnych faz procesu - mamy zestaw narzędzi, które umiejętnie wykorzystane mogą nam bardzo pomóc, ale jeśli ktoś chce mieć jasną granicę kiedy co robić, to tutaj brak jest twardych (jak i krępujących) wytycznych. Jeszcze większym wyłomem jest założenie nietechniczności zespołu - Data Thinking, tak jak i Design Thinking, ma na celu wspólną pracę zróżnicowanego kompetencyjnie zespołu, a nie rugowanie czy to specjalistów AI, czy projektantów.
Dlatego w Promity o ile wspieramy się elementami omówionego wyżej Toolkita, o tyle bliżej nam w sesjach Data Thinking do procesu przedstawionego w "Data Thinking: A Canvas for Data-Driven Ideation Workshops.". Kanwa “Data Innovation Board” obrazuje konkretny proces, w którym zaproponowano trzy fazy z bardzo konkretnymi granicami - chcesz przejść do fazy generowania pomysłów (ang. ideate), odpowiedz najpierw na pytanie jak mapują się zidentyfikowane potrzeby Użytkownika, na posiadane dane (How might we match the identified user needs with the existing data?).

Data Innovation Board, źródło: Data Thinking: A Canvas for Data-Driven Ideation Workshops.".
W przedstawionej kanwie widać, jak olbrzymi nacisk kładziony jest na dane, na stan ich posiadania w fazie “Explore” oraz na to jakie dane będą wykorzystane z tych będących w posiadaniu, a jakie należy pozyskać (oraz jak pozyskać!) w fazie “Ideate”. Mimo innych faz w stosunku do Design Thinking, oczywistym jest obecność tej filozofii w całym procesie, a faza “Explore” to w istocie faza Empatyzacji z dodatkiem aspektu stanu danych.
Faza “Evaluate” jest bardzo nastawiona na cel. Oczywiście, sam proces jest iteracyjny, ale musimy wiedzieć co i jak testujemy. Podobnie jak w przypadku The Intelligence Augmentation Design Toolkit i kanwy “Smart Service Storyline”, poświęcono całą kolumnę na “Touchpoints” - Użytkownik jest zawsze w centrum! Kolejnym podobieństwem jest kolumna “Channels”, którą można uogólnić tak jak ma to miejsce w Toolkicie, na “Discoverability”.
Również tak jak w Design Thinking, chętnie sobie pożyczymy różne narzędzia w trakcie pracy. Będą to zarówno stare i sprawdzone techniki, jak matryca 2x2 do nadania priorytetu pomysłom, jak i elementy innych współczesnych metodyk jak np. karty zapożyczone z Toolkitu. Również w Toolkicie bardziej szczegółowo rozbito kwestie ryzyk (bias, learning loop) i nikt podczas workshopu nie broni nam wydzielać bardziej szczegółowych kolumn.
W istocie do każdej kolumny można przygotowywać kolejne narzędzia usprawniające prace, czego przykładem jest Data Collection Map: A Canvas for Shared Data Awareness in Data-Driven Innovation Projects, która ma na celu facylitacje warsztatów i rozpisanie danych, które posiadamy lub możemy pozyskać z podziałem na ich rodzaj (biometryczne, geograficzne, master data itd.).
Podsumowanie
Sami autorzy Data Thinking: A Canvas for Data-Driven Ideation Workshops." piszą “Additional workshops shall be conducted in order to further improve the canvas.”. Twórcy The Intelligence Augmentation Design Toolkit mówią o początku drogi. W artykule tylko wstępnie zarysowałem krajobraz, umieszczając na nim dwa podejścia. Nijak to nie wyczerpuje zagadnienia, wiele firm proponuje własne metodyki Data Thinking, AI Design, czy Human-Centered AI Product, wszystkie skupiające się na podobnych wartościach.
Przykładowo Google proponuje The People + AI Guidebook mający wiele wspólnego z przedstawionymi podejściami, ale też wskazujący na bardziej techniczne narzędzia np. what-if-tool pozwalający na wizualne badanie zachowania wyszkolonych modeli Machine Learning przy minimalnym kodowaniu. Również definiowanie sukcesu, temat od którego świadomie uciekłem w tym artykule, jest podjęte w pierwszym rozdziale User Needs + Defining Success.
Uważam, że Data Thinking jest koniecznością: musimy projektować rozwiązania AI w interdyscyplinarnych zespołach, musimy myśleć o rozwiązaniach w sposób “end-to-end”, musimy wychodzić od trosk Użytkowników, musimy się rozumieć - jest to praca domowa do odrobienia przez nas, a Data Thinking ma być tu wspierającym nas narzędziem. Możliwe, że w trakcie warsztatów okaże się, że potrzebna jest technologia chmurowa, poprawa jakości danych, lub uzupełnienie zespołu o brakujące kompetencje, ale to wszystko ma służyć celowi, który my musimy rozumieć.
Zainteresował Cię ten artykuł? Sprawdź poniżej, jakie szkolenia z zakresu Deep Learning, Data Science oraz AI oferuje firma Promity ???