Co trzeba umieć na stanowisku Data Scientist w 2023

Obecnie na rynku pracy IT można zauważyć coraz więcej ofert w dziedzinie analizy danych. Dziś skupimy się na “naukowcach od danych”, czyli Data Scientists. Znajdą oni zatrudnienie w różnych sektorach gospodarki, od finansów i marketingu, po medycynę i nauki społeczne.
Data Science to interdyscyplinarna i aktualnie bardzo dynamicznie rozwijająca się dziedzina. Dane zalewają świat. Codziennie są zbierane i przetwarzane niezliczone ich ilości, a proces ten z dnia na dzień przyspiesza, wraz z rozwojem AI. Nic nie wskazuje na to, że coś zatrzyma ten pędzący pociąg; wszystko-że rozwinie on co najmniej prędkość światła.
Zadaniem Data Scientist jest wyciąganie wartościowych informacji z dużych zbiorów danych oraz ich interpretacja. Ale to nie wszystko. Osoba pracująca na tym stanowisku jest następnie odpowiedzialna za prezentację wyników swoich badań i wyodrębnionych trendów przełożonym (klientom). To następnie jest podstawą do podejmowania trafnych decyzji biznesowych. Dlatego w roli Data Scientist idealnie sprawdzi się ktoś, kto posiada zarówno bogaty wachlarz kompetencji twardych (programistycznych), jak i miękkich (biznesowych).
Jak pracuje Data Scientist?
Główną kompetencją Data Scientist jest umiejętność odkrywania trendów i wzorców w danych, które mogą być użyteczne dla biznesu. Aby osoba pełniąca tę funkcję mogła dostarczyć maksymalną wartość dla firmy, to musi brać ona udział we wszystkich etapach cyklu życia oprogramowania (SDLC). Dlatego Data Scientist powinien mieć przynajmniej podstawową wiedzę na temat tworzenia potoków danych, analizy danych, uczenia maszynowego, matematyki, statystyki, inżynierii danych, chmury obliczeniowej i inżynierii oprogramowania.
Poza tym powinien mieć łatwość komunikacji i współpracy z innymi zespołami, takimi jak programiści, analitycy biznesowi, projektanci i osoby decyzyjne (zarząd, klienci). A także, być swobodnym w tworzeniu wizualizacji i prezentacji wyników analiz, tak, aby były one zrozumiałe i przejrzyste.
Zadania osoby na tym stanowisku obejmują m.in.: analizę i wyciąganie informacji z dużych zbiorów danych, projektowanie modeli prognostycznych i algorytmów uczenia maszynowego, ocena jakości danych i oczyszczanie ich z błędów. W tym celu używa takich technik jak: machine learning, analiza statystyczna, uczenie nadzorowane, deep learning, uczenie nienadzorowane, NLP i inne (dane na podstawie Badania Społeczności IT 2023 dla obszaru Data Science).

Wykształcenie czy doświadczenie?
Zdecydowanie doświadczenie. Choć w dużej części ogłoszeń o pracę dla Data Scientist, pracodawcy zaznaczają konieczność posiadania wykształcenia wyższego, a nawet doktoratu w dziedzinach takich jak informatyka, matematyka, ekonomia, ekonometria, statystyka, badania operacyjne lub data science. Poza tym nie da się ukryć, że osoby zainteresowane pracą na tym stanowisku są generalnie specjalistami bardzo dobrze wykształconymi (tudzież wyszkolonymi).
Wystarczy spojrzeć na Raport Szczegółowy z Badania Społeczności IT 2023 dla obszaru Data Science, gdzie praktycznie nie odnotowaliśmy pracowników bez wykształcenia wyższego (poza tymi którzy są w trakcie studiów). Większość, bo aż 51%, posiada tytuł magistra/magistra inżyniera, a 10% - doktorat.
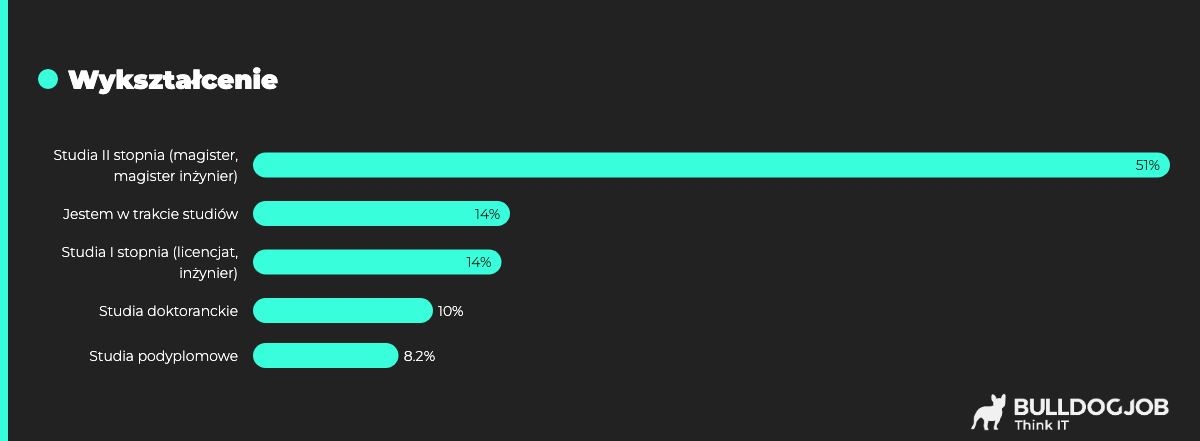
Jednak mimo to, studia wyższe nie w każdym wypadku są niezbędne do podjęcia pracy na stanowisku Data Scientist. Odnosząc się do treści przykładowych ofert pracy dla tego stanowiska, widzimy, że zdarza się, iż konieczność ukończenia studiów pojawia się jako “nice to have”, a nie jako niezbędna kwalifikacja.
Nie da się tego samego powiedzieć o doświadczeniu. Tutaj pracodawcy wymagają nawet 4-5 lat doświadczenia w pracy z danymi w różnym zakresie. Choć to też oczywiście zależy od konkretnego ogłoszenia, a co za tym idzie, od specyfiki pracy w danej firmie i branży.
Można więc powiedzieć, że większość wartość mają osoby doświadczone i z odpowiednimi kompetencjami (choćby nawet bez dyplomu), aniżeli ktoś świeżo po studiach o kierunku Data Science, ale bez praktyki.
Programowanie? Jak najbardziej - Python, R, SQL, NoSQL
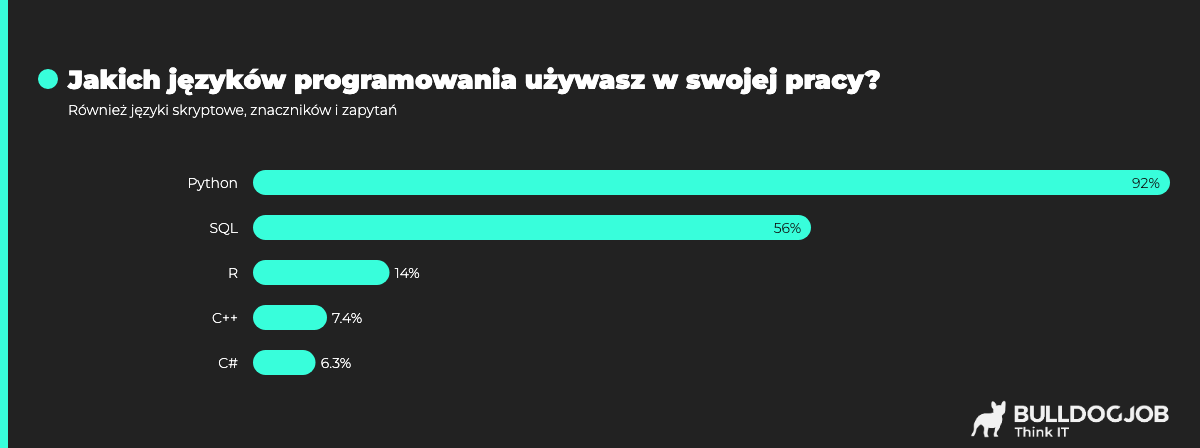
Mimo że Data Scientist nie jest programistą, to często korzysta on z języków programowania, takich jak Python, R czy SQL.
Jeżeli, wiec myślisz o karierze jako Data Scientist, a nie masz jeszcze żadnych podstaw programistycznych (np. w R, C++, C#) to koniecznie zacznij od nauki Pythona.
Dlaczego Python?
Ponieważ jest jednym z najpopularniejszych języków programowania wykorzystywanych przez specjalistów związanych z analizą danych, uczeniem maszynowym i Big Data. Poza tym jest stosunkowo “prosty”, elastyczny, łatwy użyciu oraz posiada bogate biblioteki i frameworki.
Dla osób na stanowisku Data Scientist pomocne będą przede wszystkim biblioteki takie jak NumPy, Pandas, SciPy i Matplotlib, które są często wykorzystywane do eksploracyjnej analizy danych, wizualizacji danych oraz przetwarzania danych. Poza tym Python ma wiele bibliotek ML takich jak Scikit-learn, TensorFlow, Keras i PyTorch, które umożliwiają tworzenie modeli uczenia maszynowego i ich trening na dużych zbiorach danych. Dostępnych jest także wiele bibliotek do przetwarzania Big Data, takich jak PySpark, Dask i Apache Arrow, a także posiada biblioteki umożliwiające przetwarzanie tekstu i języka naturalnego (NLTK, Spacy i Gensim). Więcej o przydatnych narzędziach do ML w Pythonie, przeczytasz w tym artykule.
Dlaczego SQL i NoSQL?
Mówiąc o danych, myślimy o bazach danych, po których Data Scientist powinien się bardzo swobodnie poruszać.
Jeśli chodzi o SQL, stworzony do zarządzania relacyjnymi bazami danych, to jego znajomość jest nadal bardzo ważna, mimo że powstał w latach 70. Aż 56% naszych ankietowanych pracujących w obszarze Data Science, używa SQL w 2023. Dzięki SQL można w łatwy sposób pozyskiwać dane z tabelarycznych baz danych.
Natomiast warto zauważyć, że firmy zwracają się w stronę tzw. Baz NoSQL, (np. Google Cloud Bigtable czy Amazon DynamoDB), które nie przechowują danych jako tabel relacyjnych. Bazy NoSQL stanowią uzupełnienie czy też alternatywę dla tradycyjnego modelu danych. Ich rozwój jest związany ze wzrostem ilości gromadzonych danych oraz wykorzystywaniem danych niestrukturyzowanych w modelach uczenia maszynowego.
Chmury-AWS, Google Cloud Platform, Microsoft Azure
Wykorzystanie chmury w przetwarzaniu i analizie danych jest coraz bardziej powszechne. Aby zwiększyć skalowalność i efektywność swoich usług coraz więcej firm przenosi dane do chmury (np. do platform takich jak AWS, Azure, Google Cloud itp.). Dlatego też umiejętność korzystania z tych platform i zrozumienie, jak przetwarzać i analizować dane w chmurze jest dla Data Scientist kluczową kompetencją.
Nie wspominając o tym, że dostępnych jest wiele narzędzi i usług chmurowych dla analizy danych (takich jak usługi Big Data, uczenie maszynowe i analiza predykcyjna), które ułatwiają pracę Data Scientist. Chmura umożliwia efektywne skalowanie infrastruktury, co pozwala na przetwarzanie dużych zbiorów danych i szybsze wdrażanie modeli uczenia maszynowego. Dlatego, jeśli poważnie myślisz o pracy jako Data Scientist, nie przechodź obojętnie obok technologii związanych z pracą w chmurze.
Apache Airflow
Kandydat na Data Scientist powinien znać Apache Airflow. Jest to popularne narzędzie open-source do zarządzania przepływami pracy (workflow) w analizie danych i uczeniu maszynowym. Pozwala na tworzenie, harmonogramowanie i monitorowanie złożonych przepływów danych, które obejmują etapy od pozyskiwania danych, poprzez ich obróbkę, aż do szkolenia i wdrażania modeli.
Apache Airflow ułatwia pracę z danymi, ponieważ pozwala na automatyzację powtarzalnych zadań, takich jak pobieranie danych z różnych źródeł i ich przetwarzanie. Można w łatwy sposób uruchamiać skrypty, które zajmują się przetwarzaniem danych i trenowaniem modeli.
Jest to cenne narzędzie dla Data Scientists, Używa go wiele dużych firm technologicznych, takich jak Google i Slack. Oczywiście Airflow ma swoje ograniczenia, ale mimo to jest popularnym narzędziem do zarządzania procesami ETL i potokami uczenia maszynowego.
Inżynieria oprogramowania
Znajomość inżynierii oprogramowania jest bardzo ważna dla pracy Data Scientist. Pierwotny kod tworzony przez Data Scientistów nie jest czytelny ani dobrze przetestowany i zgodny z konwencjami stylu. Oczywiście taki kod może być przydatny przy eksploracji danych i szybkich analizach, ale jeśli zaistnieje potrzeba wprowadzenia modeli uczenia maszynowego na produkcję, to należy już stosować zasady inżynierii oprogramowania.
Dlatego ważne jest, aby nauczyć się: konwencji formatowania kodu, testów jednostkowych, kontroli wersji np. na GitHubie, funkcjonowania zależności i środowisk wirtualnymi oraz kontenerów.
Podsumowując
W artykule wymieniliśmy wybrane techniczne obszary, jakich warto się uczyć, by zdobyć pracę jako Data Scientist. Oczywiste jest, że różne firmy mają swoje wymagania. Czasem jest to pozycja bardziej biznesowa, a czasem bardziej programistyczna. W niektórych ogłoszeniach pojawia się znajomość systemu Linux/Unix. Pracodawcy wymagają rzecz jasna znajomości języka angielskiego, co jest standardem w branży IT, ale warto o tym przypomnieć.
Jeśli interesujesz się analizą danych i trendów, to nigdy nie marnuj okazji na zbieranie zarówno wiedzy, jak i doświadczenia w obszarze data science, bo jest bardzo przyszłościową dziedziną. Zajrzyj na nasze oferty pracy, a może się okazać, że dołączysz do grona Data Scientists już niebawem.