Co nowego w Pythonie 3.9

Po raz kolejny przyszło nam czekać na nową wersję Pythona. Obecnie znajduje się ona w wersji beta (3.9.0b3), ale już wkrótce będziemy się mogli cieszyć wydaniem 3.9. Niektóre z nowych funkcji są bardzo obiecujące, więc świetnie będzie je już niedługo zobaczyć w akcji. W tym artykule skupimy się na kilku istotnych nowościach i omówimy następujące kwestie:
- Operatory do sumowania słowników
- Type Hinting
- Dwie nowe metody String
- Nowy parser Pythona
Rzućmy okiem na nowe funkcje i zobaczmy, jak z nich korzystać.
Sumowanie słowników
Jeśli mamy dwa słowniki a i b, które musimy scalić, korzystamy teraz z operatorów unii. Mamy operator scalania |:
a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}
c = a | b
print(c)[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
Oraz operator aktualizacji |=, który aktualizuje oryginalny słownik:
a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}
a |= b
print(a)[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}Jeśli nasze słowniki mają wspólny klucz, to zostanie użyta para klucz-wartość w drugim słowniku:
a = {1: 'a', 2: 'b', 3: 'c', 6: 'in both'}
b = {4: 'd', 5: 'e', 6: 'but different'}
print(a | b)[Out]: {1: 'a', 2: 'b', 3: 'c', 6: 'but different', 4: 'd', 5: 'e'}Aktualizacja słownika z iterowalnym obiektem
Innym fajnym zachowaniem operatora |= jest możliwość aktualizacji słownika, dając mu tym samym nowe pary klucz-wartość z iterowalnego obiektu, takiego jak lista lub generator:
a = {'a': 'one', 'b': 'two'}
b = ((i, i**2) for i in range(3))
a |= b
print(a)[Out]: {'a': 'one', 'b': 'two', 0: 0, 1: 1, 2: 4}
Jeśli spróbujemy tego samego ze standardowym operatorem unii | to otrzymamy TypeError, ponieważ można go wywoływać tylko na dwóch obiektach typu dict.
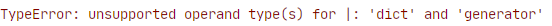
Metody string
W nowej wersji Pythona dodano dwie nowe metody ciągów znaków do usuwania prefiksów i sufiksów:
"Hello world".removeprefix("He")[Out]: "llo world"Hello world".removesuffix("ld")[Out]: "Hello wor"Nowy parser
Ta zmiana może nie wydawać się aż tak wyraźna, ale być może będzie jedną z najbardziej znaczących poprawek dla przyszłej ewolucji Pythona. Python obecnie używa głównie gramatyki opartej na LL(1). Może ona być z kolei analizowana przez parser LL(1), który bada kod z góry na dół i od lewej do prawej i czyta tylko jeden token do przodu.
Nie mam dogłębnej wiedzy, jeżeli chodzi o ten mechanizm, ale mogę podać kilka problemów, które występują w Pythonie ze względu na takie podejście:
- Python zawiera gramatykę inną niż LL(1). Z tego właśnie powodu niektóre części obecnej gramatyki muszą wykorzystywać różnego rodzaju obejścia, powodując niepotrzebną złożoność.
- LL(1) tworzy ograniczenia w składni Pythona (bez możliwości ich obejścia). Problem ten podkreśla fakt, że następującego kodu nie można po prostu zaimplementować przy użyciu bieżącego analizatora składni (dostaniemy błąd SyntaxError):
with (open("a_really_long_foo") as foo,
open("a_really_long_bar") as bar):
pass- LL(1) nie działa z lewostronną rekurencją. To oznacza, że istnieją przykłady rekurencyjnej składni, które tworzą nieskończoną pętlę w drzewie parsowania. Guido van Rossum, twórca Pythona, wyjaśnia to tutaj.
Wszystkie te czynniki (i wiele innych, których po prostu nie rozumiem) mają bardzo duży wpływ na Pythona i ograniczają ewolucję tego języka. Nowy parser, oparty na PEG, da programistom Pythona znacznie większą elastyczność, czyli coś, co pewnie bardziej zaczniemy odczuwać w Python 3.10.
To wszystko, czego możemy się spodziewać w nadchodzącym Pythonie 3.9. Jeśli naprawdę nie możesz się doczekać, to najnowsza wersja beta (3.9.0b3) jest dostępna tutaj.
Oryginał tekstu w języku angielskim przeczytasz tutaj.