BERT – czyli jak bohater Ulicy Sezamkowej zmienia wyszukiwarki

Pod koniec 2019 roku firma Google zaktualizowała algorytm, który poprawi wyniki wyszukiwania o 10% pod nazwą Google BERT (stąd powiązanie z muppetem Bertem). Google opisuje BERT-a jako największą zmianę w systemie wyszukiwania od czasu wprowadzenia prawie pięć lat temu RankBraina, a nawet jedną z największych zmian algorytmicznych w historii wyszukiwania. Algorytm BERT jest obecnie wdrażany na całym świecie.
Wykorzystywany może być zarówno w miejscach przechowywania produktów, jak wielopowierzchniowe i wielopoziomowe magazyny, aby sprawdzić, czy produkt podobny posiadamy już swojej ofercie, ale także do rozwoju inteligentnej automatyzacji procesów biznesowych, np. OCR (ang. Optical Character Recognition). Algorytm ten jest w stanie porównywać ze sobą nazwy produktów na pozór się różniących, czasem ze skutecznością porównania lepszą od osoby z wieloletnim doświadczeniem w danej branży. Omówimy tutaj jeden z praktycznych przykładów wykorzystania tego algorytmu.
Inteligentne porównywanie produktów
Jeżeli wprowadzamy na rynek nowy produkt, to nie wiemy, jak będzie się sprzedawać. Pojawia się problem związany z tym, gdzie powinien zostać ulokowany w magazynie. Wówczas z pomocą przychodzi inteligentna porównywarka, która może znacznie skrócić czas poświęcony na logistykę. Pozwala ona odnaleźć produkty podobne do aktualnie rozważanego i dzięki temu ustalić optymalne położenie towaru. Zbudowana jest ona w oparciu o dwa algorytmy uczenia maszynowego: klasteryzację metodą k-średnich oraz algorytm o nazwie RoBERTa.
Algorytm RoBERTa – co to jest?
RoBERTa (ang. A Robustly Optimized BERT Pretraining Approach) jest to pre-trenowana sieć neuronowa wykorzystywana do problemów związanych z przetwarzaniem języka naturalnego (NLP). Jest to zoptymalizowany algorytm BERT (ang. Bidirectional Encoder Representations from Transformers). Oba te algorytmy cechują się umiejętnością wyciągania kontekstu ze zdania. Jest to skutek tego, że RoBERTa, czy też sam BERT, nie interpretują słów jedno po drugim.
W odróżnieniu od większości modeli językowych, algorytmy te otrzymują tzw. reprezentację wektorową danego słowa (Embedding) poprzez równoczesne odniesienie się zarówno do tego, co występuje przed tym słowem, jak i po nim. W ten sposób algorytm „widzi” różnicę pomiędzy słowem „zamek” użytym w odniesieniu do zamka błyskawicznego, a użytym w odniesieniu np. do budynku.
Podstawą algorytmów BERT oraz RoBERTa jest głęboka sieć neuronowa o nazwie Transformer. Służy ona do zamiany jednej sekwencji w inną. Odbywa się to z wykorzystaniem tzw. Enkoderów i Dekoderów, które na ogół odpowiadają za przekształcenie wejściowej sekwencji w pojedynczy wektor (Enkoder) i pojedynczego wektora w sekwencję wyjściową (Dekoder).
W Transformersach Enkodery i Dekodery działają jako dwa osobne mechanizmy. Pierwszy z nich odpowiada za zrozumienie tekstu przez maszynę. Ich wejściem jest tekst zamieniony na wektor. Dodatkowo dodaje się informację na temat położenia każdego słowa. Następnie jest to przetwarzane przez kolejne warstwy sieci tak, aby otrzymać reprezentację wektorową wprowadzonego tekstu, która jest w stanie przechowywać nauczone informacje.
Dekoder odpowiada z kolei za predykcję prawdopodobieństwa wystąpienia danego słowa. Mając na przykład zdanie „I am fine”, Dekoder analizuje je słowo po słowie. Za każdym razem maskuje kolejne słowo i próbuje je przewidywać. Próbując przewidzieć słowo „fine” Dekoder widzi „I am _”. Jego celem jest możliwie najtrafniej przewidzieć brakujące słowo.
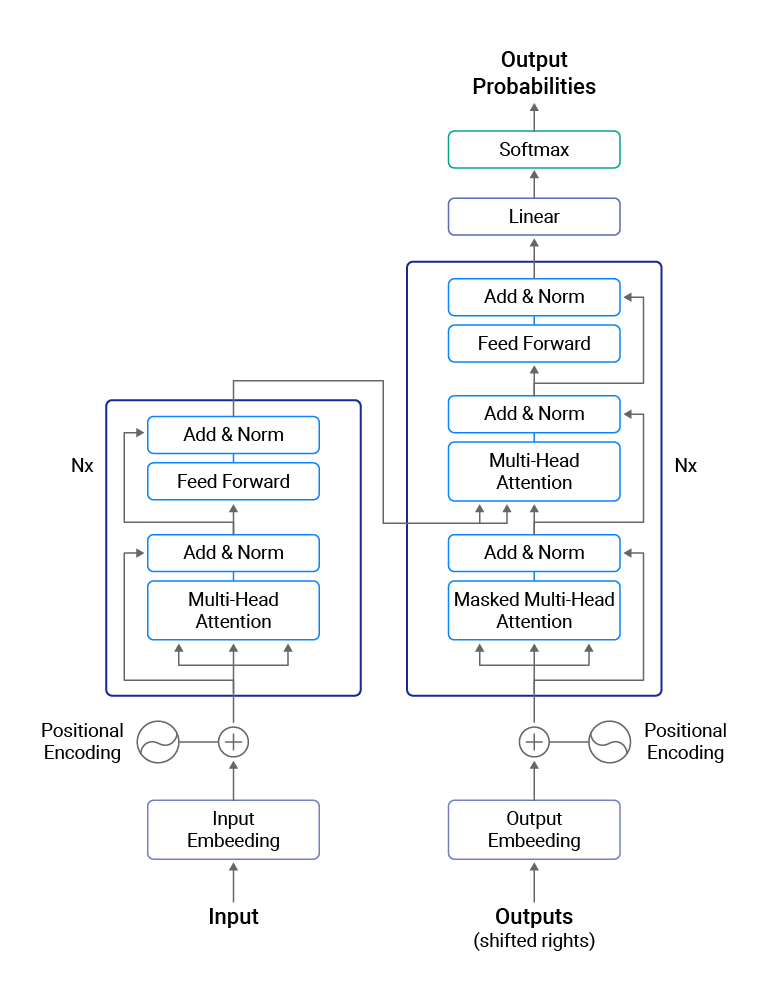 Architektura modelu Transformer. Po lewej Enkoder i po prawej Dekoder
Architektura modelu Transformer. Po lewej Enkoder i po prawej Dekoder
Algorytm BERT wykorzystuje z Transformersów jedynie Enkodery. To właśnie dzięki nim jest w stanie odczytać całą sekwencję słów jednocześnie.
Tworzenie inteligentnego porównywania produktów
Ten mechanizm wykorzystuje kilka aspektów podobieństwa pomiędzy produktami. Z jednej strony są to podobieństwa fizyczne. Z drugiej jednak strony tego typu informacje nie są wystarczające, aby jednoznacznie uznać, że produkty są podobne. Np. biały porcelanowy kubek ma cechy fizyczne bardzo podobne do białej porcelanowej miski, jednak nie są to produkty podobne. Dlatego warto również porównywać nazwy. Nie chodzi tu jednak o to, że owe nazwy mają brzmieć podobnie, a o to, aby nazwy na pozór różne, ale odnoszące się do tego samego, były uznane za podobne (np. żakiet i marynarka).
Ograniczenie liczby produktów
Zostało wcześniej wspomniane, że wyszukiwarka wykorzystuje również podobieństwo fizyczne. Właśnie takie podobieństwo pomaga wybrać produkty potencjalnie podobne. Chcemy, aby porównywarka produktów oparta o algorytm BERT działała w określonych kategoriach tak, by uniknąć porównywania np. niebieskich spodni dresowych z żółtą blachodachówką, gdyż takie porównanie nic nie wnosi – są to produkty bardzo od siebie się różniące i potrzebujemy ich porównywać
Porównując ze sobą wybrane cechy fizyczne rozważanego towaru a wszystkich pozostałych produktów, otrzymujemy fizyczne podobieństwo w skali 0-100 (można to traktować jako fizyczne podobieństwo produktów wyrażone w procentach) i ograniczamy się do 100 najbardziej podobnych produktów.
 Przykład otrzymanego podobieństwa fizycznego do produktu A
Przykład otrzymanego podobieństwa fizycznego do produktu A
Fakt, że ograniczamy się do 100 najbardziej podobnych produktów, jest efektem testów, które pokazały, że taka liczba produktów potencjalnie podobnych jest wystarczająco duża, aby odnaleźć produkty rzeczywiście podobne (o ile istnieją) oraz wystarczająco mała, aby tylko w wyjątkowych sytuacjach otrzymać błędną informację nt. podobieństwa produktów.
Wykorzystanie algorytmu RoBERTa
Mając ograniczoną liczbę potencjalnie podobnych produktów, można zająć się wyznaczaniem podobieństwa pomiędzy nazwami towarów. W tej części najpierw za pomocą algorytmu RoBERTa każdą nazwę należy zamienić na reprezentację wektorową. W ten sposób nazwa każdego produktu jest przedstawiona jako wektor.
Drugim etapem jest wyznaczenie podobieństwa pomiędzy otrzymanymi wektorami. Odbywa się to za pomocą metryki BERTScore. Wyniki zwrócone za pomocą tej miary odległości są bliższe ludzkiej ocenie, niż w przypadku innych standardowo wykorzystywanych metryk (jak np. odległość cosinusowa). Ma ona jednak wadę taką, że zwrócone podobieństwo (w skali 0-1) jest stosunkowo bardzo wysokie, co mogłoby się czasem okazać mylące. Dlatego też w kolejnym kroku najpierw sprawdza się, czy otrzymany wynik BERTScore chociaż w jednym spośród tych 100 produktów przekracza 0.9 – jeżeli nie to można przyjąć, że nie ma produktów podobnych. W przeciwnym razie robi się grupowanie na 2 klastry ze względu na otrzymane podobieństwo nazw, które otrzymuje się za pomocą algorytmu RoBERTa.
Takie zastosowanie wcześniej nauczonego modelu do innego problemu nazywane jest Transfer Learningiem. Dzięki temu spośród rozważanych 100 produktów potencjalnie podobnych, można ograniczyć się do znacznie mniejszej liczby. Zazwyczaj jest to od 5 do 30 produktów. Jeżeli jednak po tym etapie mamy powyżej 30 towarów, to są dwie możliwości – albo wśród potencjalnie podobnych produktów nadal znajdują się takie, które jednak nie są podobne, albo podobnych produktów jest tak dużo, że spokojnie te najmniej podobne można odrzucić. Wówczas ponownie następuje klasteryzacja na 2 grupy, tym razem jednak ze względu na ogólne podobieństwo tj. średnią z podobieństwa fizycznego i podobieństwa zwróconego przez BERTScore.
Opisany powyżej etap jest już ostatnim w wyznaczaniu produktów podobnych. Wówczas wśród nich na ogół zostają już tylko produkty rzeczywiście podobne do rozważanego oraz liczba znalezionych towarów znajduje się pomiędzy 0 a 30 w zdecydowanej większości przypadków.
Podsumowanie
Przedstawiona porównywarka może w dużym stopniu usprawnić pracę związaną z zarządzaniem magazynem, ale również ma wiele innych zastosowań, gdzie mamy dużo danych tekstowych i chcielibyśmy dowiedzieć się, jak są do siebie podobne. Ma to również zastosowanie wszędzie tam, gdzie istnieje potrzeba tzw. inteligentnej automatyzacji procesów biznesowych.
Tego typu innowacyjne projekty i wiele innych w oparciu o najnowsze technologie realizowane są podczas wakacyjnych staży w Comarch. Jeżeli zaciekawiło Cię działanie BERT-a i chciał(a)byś je poznać na przykładach praktycznych, to nasza oferta stażu AI/ML jest skierowana właśnie dla Ciebie.
Podczas stażu:
- poznasz również wiele innych ciekawych rozwiązań
- będziesz mieć możliwość rozwiązania praktycznego problemu
- poznasz zasady budowania systemów opartych o algorytmy sztucznej inteligencji
- będziesz mieć wpływ na to, jak dane rozwiązanie AI będzie funkcjonować
Nie zastanawiaj się, jeżeli chcesz w przyszłości pracować z najnowszymi technologiami i rozwiązaniami!
Autorzy

Michał Więtczak - Manager i Architekt Rozwiązań w Centrum Sztucznej Inteligencji w Comarch
Kinga Głąbińska - Inżynier Uczenia Maszynowego w Centrum Sztucznej Inteligencji w Comarch