5 rozwiązań skalowania bazy danych, które musisz znać!

Jeśli Twoja aplikacja doświadcza problemów z obciążeniem, czas wyciągnąć szampana! Twoja aplikacja musi być całkiem niezła, jeśli jest na tym etapie. Osiągnąłeś maksymalną liczbę użytkowników, którą Twoja aplikacja jest w stanie obsłużyć, aż tu nagle wszystko zaczyna zwalniać i się psuć. Żądania sieciowe przekraczają limit czasu, zapytania do bazy danych wykonują się długo, strony ładują się bardzo wolno.
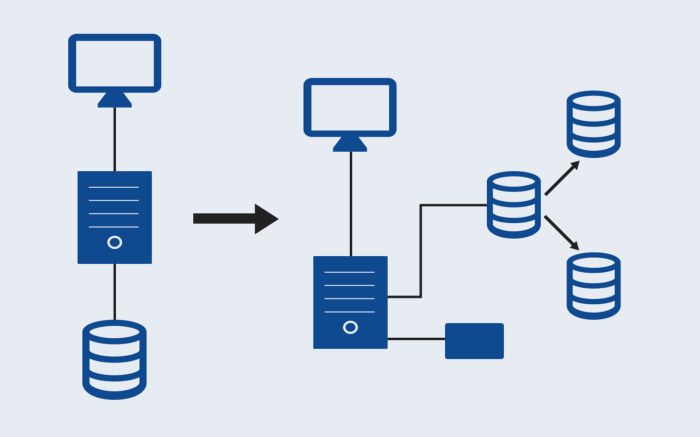
Gratulacje — Twoja aplikacja jest gotowa do skalowania! Odstaw jeszcze jednak na moment szampana... Musisz jeszcze poradzić sobie z kilkoma przeszkodami, zanim Twoi użytkownicy opuszczą Twoją aplikację na rzecz irytującego konkurenta, który skopiuje Twój pomysł.
Koszty skalowania
Zanim zaczniesz tworzyć kolejne partycje swojej bazy danych w sposób wertykalny, horyzontalny i inside-out*, powinieneś pamiętać o ważnej zasadzie. Nie powinieneś wdrażać przedwczesnych optymalizacji lub próbować skalować swojej aplikacji, zanim będzie to rzeczywiście potrzebne. Wdrażanie rozwiązań skalujących wiąże się z następującymi złożonościami:
- Dodawanie nowych funkcji trwa dłużej.
- System staje się bardziej złożony z większą liczbą elementów i zmiennych.
- Kod może być trudniejszy do przetestowania.
- Znalezienie i usunięcie bugów staje się trudniejsze.
Powinieneś zaakceptować powyższe dopiero wtedy, gdy Twoja aplikacja nie jest wystarczająco pojemna. Utrzymuj system prostym, nie wprowadzaj złożoności skalowania, jeśli nie jest to uzasadnione.
*sharding bazy danych inside-out nie jest prawdziwym rozwiązaniem. Istnieje spektrum rozwiązań skalowania, dlatego nie wdrażaj tego, jeśli nie jest to konieczne!

Znajdowanie wąskich gardeł za pomocą metryk
Każda aplikacja/system są inne! Aby określić, które rozwiązanie skalowania wdrożyć, musisz najpierw ustalić, gdzie znajduje się wąskie gardło. Czas sprawdzić system monitorowania zasobów lub stworzyć takowy, jeśli jeszcze tego nie zrobiłeś. Niezależnie od stosu, z którym pracujesz, będziesz mógł korzystać z narzędzia do monitorowania zasobów. Jeśli korzystasz z usług któregoś z wiodących dostawców IaaS (Infrastructure as a Service), takich jak AWS, Microsoft Azure i GCP, masz do wyboru świetne narzędzia do zarządzania wydajnością aplikacji.
Narzędzia te ilustrują wydajność Twoich zasobów za pomocą wykresów i innych metod wizualizacji danych. Skorzystaj z nich do szukania skoków lub płaskich szczytów. Zazwyczaj oznaczają one, że zasób został przeciążony lub wyczerpał swoje możliwości i nie był w stanie obsłużyć nowych operacji. Jeśli nie ma problemu z pojemnością, ale Twoja aplikacja wydaje się działać wolniej, spróbuj zastosować logi w najczęściej używanych operacjach.
Sprawdź logi pod kątem zasobów, które długo ładują się przez sieć, może to być inny serwer, np. API innej firmy lub Twój serwer bazy danych, który wprowadza opóźnienia. Powinieneś hostować swoją bazę danych na innym serwerze, a jeśli to tutaj pojawia się problem, to powinieneś również sprawdzić monitorowanie zasobów dla tej maszyny.
Myśląc o tym, jak Twoja aplikacja jest używana przez użytkowników i myśląc logicznie o błędach lub pęknięciach, które zaczynają się pojawiać, określenie, gdzie znajduje się wąskie gardło może być całkiem jasne. Weźmy na przykład Twittera, ta konkretna platforma jest używana głównie do czytania i pisania tweetów.
Jeśli usługi monitorowania Twittera wykazały duże obciążenie ich baz danych odnoszących się do tych działań, to byłoby sensowne dla ich zespołu, aby rozpocząć optymalizację tego obszaru platformy. W tym artykule, przyjrzymy się z bliska rozwiązaniom skalowania bazy danych, co jest zazwyczaj pierwszą możliwą awarią. Jeśli nie jesteś jeszcze zaznajomiony z designem systemów, mam dla Ciebie krótki artykuł, który wprowadzi Cię w ten temat. Zalecam zapoznanie się z designem systemów przed wdrożeniem rozwiązań skalujących.

Skalowanie aplikacji z lotu ptaka
Teraz, gdy mamy już dobre wyczucie tego, co/gdzie są problemy/wąskie gardła, możemy zacząć wdrażać rozwiązania, aby sprostać naszym problemom. Pamiętaj, prostota jest tutaj kluczowa, zawsze starajmy się unikać wprowadzania niepotrzebnych złożoności.
Wysoko postawionym celem rozwiązań skalujących jest, aby stos wykonywał mniej pracy dla najczęstszych żądań aplikacji lub efektywnie wyrównał obciążenia, którego nie można wyeliminować, na wiele zasobów. Sposób, w jaki działają techniki skalowania, przekłada się zwykle na jedno lub więcej z wymienionych poniżej:
- Ponowne wykorzystanie danych, które aplikacja już wyszukała.
- Eliminacja żądań klienta o dane, które aplikacja już posiada.
- Przechowywanie wyników typowych operacji w celu zmniejszenia liczby powtarzających się obliczeń.
- Unikanie skomplikowanych operacji w cyklu żądanie-odpowiedź.
Wiele technik skalowania sprowadza się do jakiejś formy cache’owania. W przeszłości pamięć była droga i ograniczona, obecnie dodawanie jej do serwerów jest niedrogie. Pamięć jest o wiele rzędów wielkości szybsza w dostępie do danych w porównaniu z dyskiem lub siecią; w obecnej erze, w której użytkownicy mają mnóstwo możliwości wyboru, w połączeniu z naszą minimalną uwagą, szybkość i wydajność to najważniejsze czynniki, aby Twoja aplikacja mogła przetrwać.
Rozwiązania skalowania bazy danych
Pamięć podręczna zapytań do bazy danych
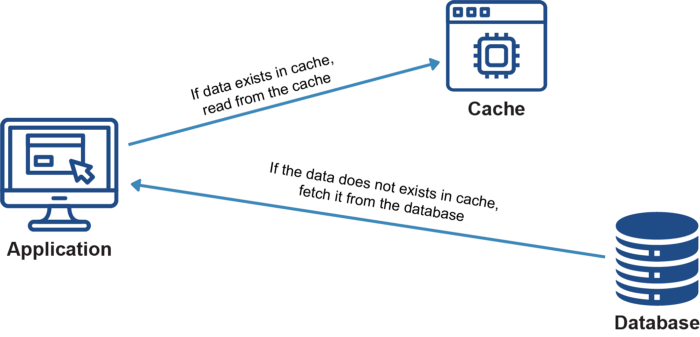
Cache’owanie zapytań do bazy danych jest jednym z najprostszych usprawnień, jakie można wprowadzić, aby poradzić sobie z obciążeniem bazy danych. Zazwyczaj aplikacja będzie posiadała kilka zapytań, które będą stanowiły większość tych wykonywanych. Zamiast odbywać za każdym razem podróż w obie strony przez sieć po te dane, mogą one być po prostu buforowane w pamięci na serwerze internetowym.
Pierwsze żądanie pobiera dane z bazy danych i buforuje wyniki na serwerze, następne żądania po prostu odczytują z pamięci podręcznej. Powoduje to zwiększenie wydajności, ponieważ danym zajmuje mniej czasu podróżowanie przez sieć i są bliżej klienta. Powoduje to również, że więcej zasobów serwera bazy danych jest dostępnych, ponieważ znaczne obciążenie rozkłada się na system pamięci podręcznej.
Oprócz zwiększonej dostępności, jeśli baza danych jest niedostępna, pamięć podręczna może nadal zapewniać stałą obsługę aplikacji, dzięki czemu system jest bardziej odporny na awarie. Istnieje wiele narzędzi, które można wykorzystać do przeprowadzenia analizy logów zapytań do bazy danych, dzięki czemu można zobaczyć, które zapytania trwają najdłużej i które są uruchamiane najczęściej.
Oczywiście, dane, które są buforowane mogą stać się “nieświeże” lub nieaktualne dość szybko. Będziesz musiał zwrócić szczególną uwagę na to, które dane zdecydujesz się buforować i jak długo. Dla przykładu gazeta online będzie miała nową gazetę codzienną co 24 godziny. Zamiast więc żądać tych danych z bazy danych za każdym razem, gdy użytkownik wejdzie na stronę, mogą buforować te dane na serwerze internetowym przez 24 godziny i serwować je bezpośrednio z serwera. Wymagania produktowe lub biznesowe będą dyktować, co może, a co nie może być buforowane.
Indeksy baz danych
Indeksowanie bazy danych jest techniką, która poprawia szybkość operacji wyszukiwania danych w tabeli bazy danych. Indeksy używane są do szybkiego odnajdywania danych bez konieczności przeszukiwania każdego wiersza tabeli z każdym jej otwarciem. Zazwyczaj strukturą danych dla indeksu bazy danych jest binarne drzewo poszukiwań. Pozwala to na obniżenie złożoności czasowej dostępu do danych z czasu liniowego O(n) do czasu logarytmicznego Olog(n).
W zależności od liczby wierszy w tabeli może to zaoszczędzić znaczną ilość czasu w zapytaniach, które używają indeksowanej kolumny. Na przykład, jeśli masz 10 000 użytkowników, a Twoja aplikacja posiada strony profilowe, które wyszukują użytkowników po ich nazwie użytkownika, nieindeksowane zapytanie będzie sprawdzać każdy wiersz w tabeli users, aż znajdzie profil, który pasuje do nazwy użytkownika przekazanej w zapytaniu.
Może to zająć do 10 000 badanych rzędów O(n). Tworząc indeks dla kolumny “nazwa użytkownika”, baza danych może wyciągnąć ten wiersz z logarytmiczną złożonością czasową (Olog(n)). W tym przypadku maksymalna liczba badanych wierszy wynosiłaby 14, a nie 10 000!
Efektywne indeksowanie zmniejsza obciążenie bazy danych poprzez zwiększenie wydajności, co również zapewnia znaczący wzrost wydajności, prowadząc do lepszego UX. Tworzenie indeksu powoduje dodanie kolejnego zestawu danych do przechowywania w bazie danych, dlatego należy zachować ostrożność przy podejmowaniu decyzji, które pola mają być indeksowane. Nawet przy istniejącej przestrzeni pamięci, indeksowanie jest warte zachodu, szczególnie we współczesnym developmencie, gdzie pamięć jest tania, a wydajność jest niezbędna do przetrwania.
Złożoność czasowa i struktury danych zostały krótko wspomniane w powyższym fragmencie, ale nie zostały dokładnie wyjaśnione. Jeśli jesteś tym zainteresowany i chcesz pogłębić swoją wiedzę na temat złożoności czasowej i struktur danych, załączone artykuły będą bardzo dobrymi źródłami!
Przechowywanie sesji
Wiele aplikacji nadal obsługuje sesje, przechowując identyfikator sesji w pliku cookie, a następnie przechowując rzeczywiste dane, dla pary klucz/wartość każdej sesji, w tabeli w bazie danych. Może to być ogromna ilość czytania i pisania dla Twojej bazy danych. Jeśli Twoja baza jest przeciążona danymi sesji, warto przemyśleć, jak i gdzie przechowujesz te dane.
Dobrym rozwiązaniem może być przeniesienie danych sesji do narzędzia buforowania w pamięci, takiego jak Redis lub memcached. Pozwoli to na odciążenie bazy danych od danych sesji, a także zwiększy szybkość dostępu, ponieważ in-memory jest szybsze niż trwałe przechowywanie danych na dysku, którego używa większość baz danych.
Ponieważ jednak in-memory jest pamięcią nietrwałą, istnieje ryzyko utraty wszystkich danych sesji, jeśli system buforowania przestanie działać. Ponadto, ponieważ rozwiązanie to przechowuje dane użytkownika wykorzystując pamięć serwera, ma ograniczony potencjał skalowania, ponieważ pamięć jest zasobem dość ograniczonym.
Innym rozwiązaniem jest rozważenie zmiany implementacji uwierzytelniania na przechowywanie informacji o sesji w samym pliku cookie, co spowoduje przeniesienie środków pozwalających na utrzymywanie stanu sesji z serwera na klienta. JWT jest najpopularniejszą implementacją uwierzytelniania opartego na tokenach. To ulży Twojej bazie danych od wszystkich danych sesji i usunie zależność od sesji po stronie serwera, chociaż wprowadza własne zestawy wyzwań.
Replikacja bazy danych
Jeśli Twoja baza danych jest nadal zbyt obciążona odczytami, nawet po buforowaniu typowych zapytań, utworzeniu wydajnych indeksów i obsłudze przechowywania sesji, replikacja może być następnym najlepszym rozwiązaniem.
W przypadku replikacji odczytu masz jedną bazę danych, do której zapisujesz. Jest ona klonowana do kilku (tylu, ile potrzebujesz) replik baz danych, z których odczytujesz dane, przy czym każda replika bazy danych znajduje się na innej maszynie (spójrz na poniższy schemat). Zdejmuje to obciążenie odczytu z głównej bazy danych i rozkłada je na wiele serwerów. Model ten poprawia również wydajność zapisu, ponieważ główna baza danych jest dedykowana do zapisu, jednocześnie radykalnie zwiększając prędkość odczytu i zmniejszając opóźnienia, ponieważ repliki baz danych są rozproszone w różnych regionach.
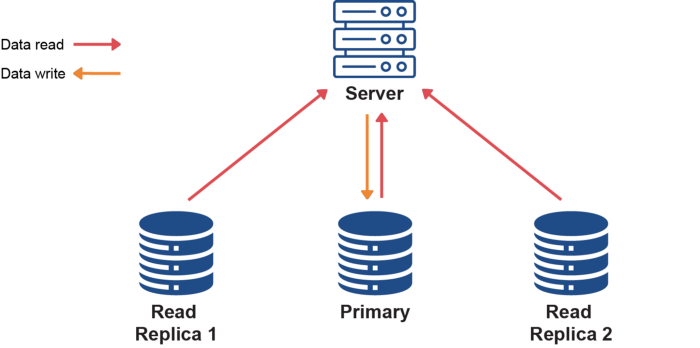
Ponieważ każda replika bazy danych znajduje się w innej maszynie, zapisy do głównej bazy danych muszą być rozpowszechniane przez repliki, co może prowadzić do niespójności danych. Jeśli potrzebujesz natychmiast odczytać dane zapisane w bazie danych — przykładowo aktualizujesz profil i chcesz, aby został on natychmiast wyświetlony — możesz wybrać odczyt z głównej bazy danych. Replikacja odczytu jest niezwykle wydajnym rozwiązaniem w zakresie skalowania, ale wiąże się z nią wiele złożoności. Dobrze byłoby wdrożyć to rozwiązanie po wyczerpaniu prostszych rozwiązań i zapewnieniu skutecznej optymalizacji wewnątrz aplikacji.
Ten wzór architektoniczny jest tradycyjnie znany jako replikacja danych master-slave, ale jest to termin, który spotkał się z krytyką na przestrzeni lat i jest w trakcie wymiany w społeczności technologicznej. Obecnie jest to najczęściej określane jako replikacja odczytu.
Sharding w bazach danych
Większość z dotychczasowych rozwiązań skalowania skupiała się na zmniejszeniu obciążenia poprzez zarządzanie odczytami w bazie danych. Sharding w bazach danych jest rozwiązaniem skalowania horyzontalnego (horizontal scaling), które pozwala zarządzać obciążeniem poprzez zarządzanie odczytami i zapisami w bazie danych. Jest to wzorzec architektoniczny polegający na procesie dzielenia (partycjonowania) głównej bazy danych (master) na wiele baz danych (shards), które są szybsze i łatwiejsze w zarządzaniu.
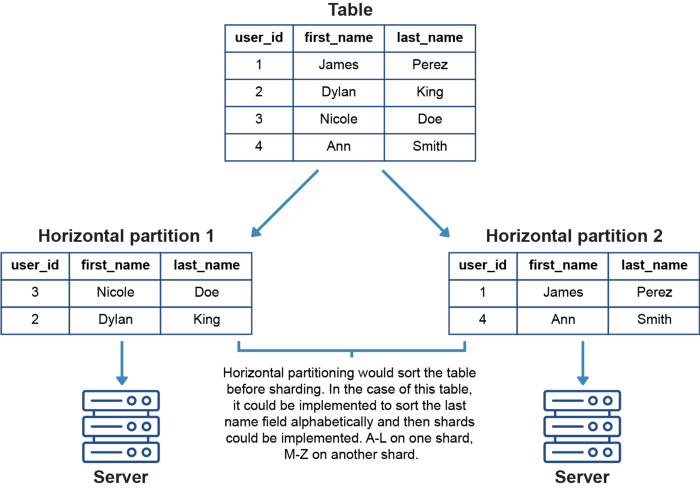
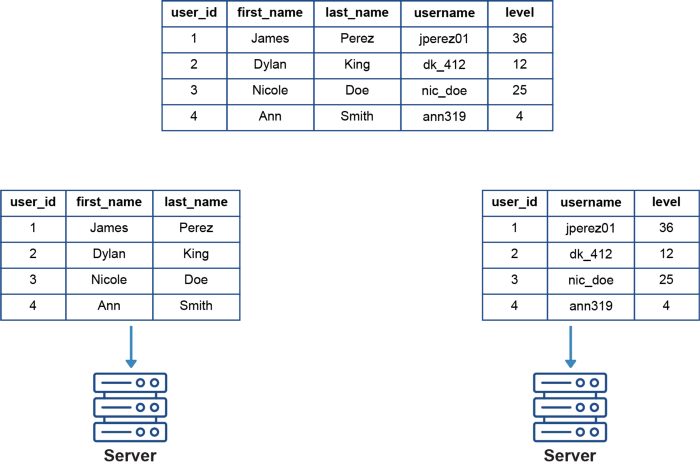
Istnieją dwa rodzaje technik shardingu bazy danych — horyzontalny i wertykalny (spójrz na poniższe schematy). Obie te techniki działają tak samo jak wertykalne i horyzontalne partycjonowanie tabel, kluczową różnicą jest to, że sharding bierze rozbite dane i rozkłada je na wiele węzłów/serwerów.
Przy partycjonowaniu horyzontalnym tabele są pobierane i umieszczane na różnych maszynach, przy czym każda tabela ma identyczne kolumny, ale różne wiersze. Partycjonowanie wertykalne jest bardziej złożone i polega na rozdzieleniu jednej tabeli na wiele maszyn. Tabela jest rozdzielana i umieszczana w nowych, odrębnych tabelach. Dane przechowywane w jednej partycji wertykalnej są niezależne od danych we wszystkich innych, każda tabela zawiera zarówno odrębne wiersze jak i kolumny.
Obie techniki shardingu ułatwiają skalowanie horyzontalne, co umożliwia dodawanie kolejnych maszyn do systemu w celu rozłożenia obciążenia. Skalowanie horyzontalne jest często przeciwstawiane skalowaniu wertykalnemu, które polega na modernizacji sprzętu istniejącego serwera. Skalowanie wertykalne bazy danych jest stosunkowo proste, chociaż każda nierozpowszechniona baza danych będzie miała swoje ograniczenia pod względem mocy obliczeniowej i pamięci masowej, więc swoboda skalowania czyni system znacznie bardziej elastycznym.
Shardowana architektura bazy danych może również znacząco zwiększyć szybkość zapytań Twojej aplikacji, jak również zapewnić zwiększoną odporność na awarie. Podczas składania zapytania do nieshardowanej bazy danych, może być konieczne przeszukanie każdego wiersza w tabeli, co może być bardzo wolne.
Alternatywnie, poprzez sharding jednej tabeli na wiele tabel, zapytania muszą przejść przez znacznie mniejszą liczbę rekordów, aby zwrócić wyniki. Ponieważ każda z tych tabel znajduje się na osobnym serwerze, wpływ niedostępności serwera jest umiarkowany. W przypadku shardowanej bazy danych wpływ awarii prawdopodobnie dotknie tylko pojedynczego sharda, w porównaniu z nieshardowaną bazą danych, gdzie awaria może potencjalnie uczynić całą aplikację niedostępną.
Shardowana architektura bazy danych zapewnia dość duże korzyści, jednak jest bardzo złożona i wiąże się z wysokimi kosztami wdrożenia i utrzymania. Zdecydowanie jest to opcja, którą chcesz rozważyć po wyczerpaniu innych rozwiązań skalowania, ponieważ konsekwencje nieefektywnego wdrożenia mogą być bardzo poważne.
Wnioski
Gratulacje, Twoja aplikacja ma teraz odpowiednie rozwiązania, aby efektywnie obsługiwać obciążenie bazy danych i skalować, dzięki czemu Twoja aplikacja odniesie sukces! Nie czas jednak na świętowanie... Efektywnie skalowany serwer jest integralną częścią wydajnej i niezawodnej aplikacji. Jeśli chcesz zatrzymać swoich użytkowników na dłużej musisz działać z prędkością błyskawicy.
Oryginał tekstu w języku angielskim przeczytasz tutaj.