3 typy rekurencyjnych sieci neuronowych
Rekurencyjne sieci neuronowe to struktura neuronalna zaprojektowana dla danych sekwencyjnych. Dane sekwencyjne to wszelkie dane, które występują w formie, w której wcześniejsze punkty danych wpływają na późniejsze punkty danych.
Rekurencyjne sieci neuronowe można stosować do danych obrazu, szeregów czasowych, a także najbardziej popularnych, danych językowych. W tym artykule omówimy trzy najbardziej znane typy rekurencyjnych sieci neuronowych oraz sprawdzimy jak zaimplementować je w Keras i TensorFlow.
3 typy rekurencyjnych sieci neuronowych
Trzy najbardziej znane typy rekurencyjnych sieci neuronowych to prosta rekurencyjna sieć neuronowa (RNN), Long Short-Term Memory Neural Network (LSTM) i Gated Recurrent Unit (GRU).
Architekturę RNN przypisuje się pracy Davida Rumelharta z 1986 roku. Ponad dziesięć lat później, w 1997 roku, w pracy Hochreitera i Schmidhubera wykazano, że komórka z długą pamięcią krótkotrwałą ma korzystny wpływ na dokładność. Niemal dwie dekady później KyungHyun Cho i in. wykazali poprawę w przypadku pewnych typów danych dzięki zastosowaniu sieci typu GRU.
Proste rekurencyjne sieci neuronowe
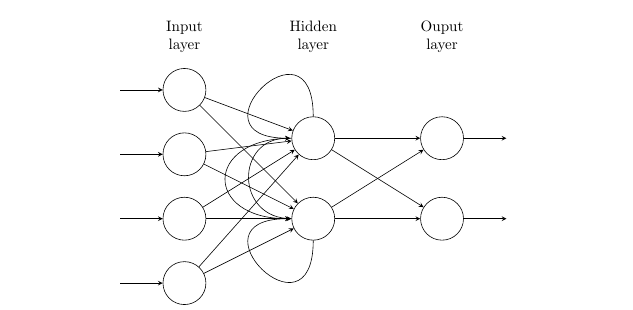
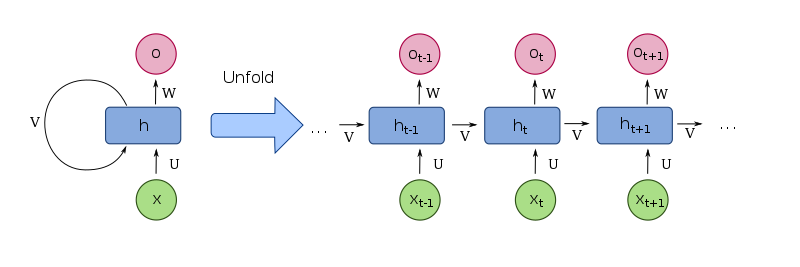
Pierwszym typem RNN, któremu się przyjrzymy, jest „prosta” rekurencyjna sieć neuronowa. Prosta oznacza, że węzły (lub komórki) sieci nie są modyfikowane.
W większości przypadków oznacza to również, że jako architektury bazowej używamy standardowej, w pełni połączonej sieci neuronowej typu feed-forward. Sieci RNN są rozszerzane w stosunku do podstawowej sieci neuronowej typu feed-forward przez dodanie pętli „sprzężenia zwrotnego” dla co najmniej jednej warstwy neuronów.
Ta pętla sprzężenia zwrotnego tworzy „powtarzalność” rekurencyjnych sieci neuronowych i jest funkcją, która sprawia, że sieci RNN są idealne dla danych sekwencyjnych. Dzięki takiemu ustawieniu pojedynczy przebieg przez sieć z wykorzystaniem jednego punktu danych może wykorzystywać wyniki z ostatniego przebiegu.
Sieci neuronowe LSTM
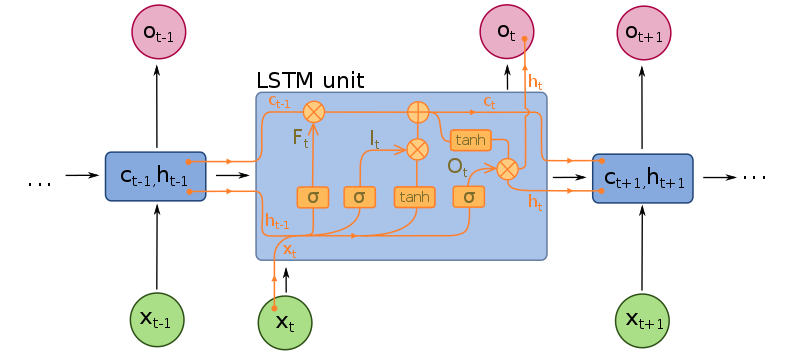
Długa pamięć krótkotrwała odnosi się właściwie do typu komórki w sieci RNN. Architektura całej sieci pozostaje bez zmian. Zmiany mogą dotyczyć także architektury, ale główną innowacją jest typ komórki. Komórki LSTM wprowadzają do komórki dodatkowe trzy „bramki”.
Są to bramka wejściowa, bramka wyjściowa i bramka „zapomnij”. Wprowadzenie tych bramek tworzy bardziej wyrafinowaną metodę określania, czy powinniśmy korzystać z danych rekurencyjnych, czy też nie.
Jest to szczególnie przydatne w przypadku danych sekwencyjnych nienormalnych, takich jak obrazy, filmy czy słowa. Wykazano, że sieci LSTM osiągają znacznie wyższą dokładność w przypadku danych wideo, danych audio i wykrywania anomalii.
Jednym z problemów sieci RNN, które rozwiązują sieci LSTM jest problem znikającego gradientu. Wraz z kolejnymi iteracjami gradient, który informuje sieć o tym, jak duży błąd popełniła, maleje wykładniczo. Sieć LSTM rozwiązuje ten problem, umożliwiając niezmienny przepływ gradientów przez sieć. Sieci LSTM mogą jednak nadal padać ofiarą eksplodujących gradientów, czyli efektu odwrotnego do zamierzonego.
Sieci GRU
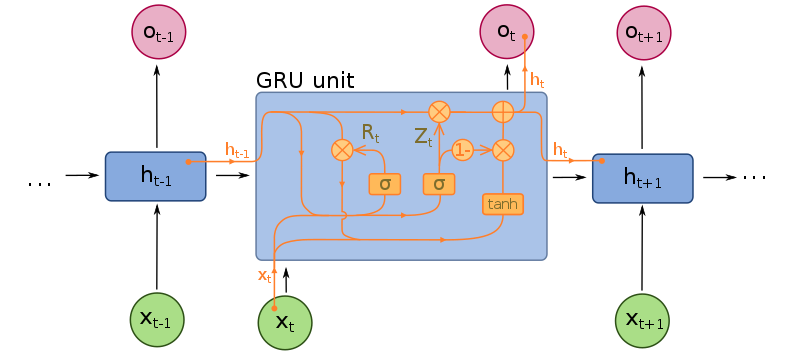
Podobnie jak w przypadku sieci LSTM, bramkowane jednostki rekurencyjne (GRU) również odnoszą się do typu komórki. Różnica między komórką GRU a komórką LSTM polega na tym, że komórki GRU nie posiadają bramki wyjściowej.
Zmniejsza to złożoność szkolenia sieci GRU. Warstwa GRU ma trzykrotnie większą liczbę parametrów niż zwykła RNN, w porównaniu z warstwą sieci LSTM, która ma czterokrotnie większą liczbę parametrów.
Sieci GRU wykazały podobną wydajność jak sieci LSTM na większości danych seryjnych, a w szczególności na danych audio i językowych. Wykazano jednak, że sieci GRU sprawdzają się lepiej w przypadku mniejszych zbiorów danych, w których niektóre klasyfikacje występują z mniejszą częstotliwością.
Python i implementacje sieci RNN, LSTM i GRU
Możemy wykorzystać Keras w TensorFlow, aby łatwo stworzyć modele RNN, LSTM i GRU. Pamiętajmy, że główną różnicą między sieciami RNN, LSTM i GRU jest typ komórki. Mówiąc trochę naiwnie każda sieć neuronowa z warstwą rekurencyjną jest siecią RNN, a każda sieć neuronowa z komórkami LSTM lub GRU jest odpowiednio tymi rodzajami modeli.
Tworzenie sieci neuronowych w Keras jest bardzo proste. To, co musimy zrobić to jedynie zainicjalizować typ modelu i dodać warstwy. W naszym przypadku tworzymy modele sekwencyjne. W trzech poniższych przykładach utworzymy trójwarstwowe sieci neuronowe dla każdego typu RNN. Zauważysz w nich również, że kod jest prawie taki sam, a to dlatego, że jedyną rzeczą, którą zmieniamy to typ komórki.
Zauważ też, że możemy dowolnie zmieniać kształt pierwszej warstwy. Powodem, dla którego używamy 28x28, jest to, że za chwilę będziemy je szkolić na zbiorze danych cyfr MNIST.
RNN w Keras
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential()
model.add(layers.SimpleRNN(64, input_shape=(28, 28)))
model.add(layers.BatchNormalization())
model.add(layers.Dense(10))
print(model.summary())LSTM w Keras
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential()
model.add(layers.LSTM(64, input_shape=(28, 28)))
model.add(layers.BatchNormalization())
model.add(layers.Dense(10))
print(model.summary())GRU w Keras
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential()
model.add(layers.GRU(64, input_shape=(28, 28)))
model.add(layers.BatchNormalization())
model.add(layers.Dense(10))
print(model.summary())Porównanie sieci RNN, LSTM i GRU na zbiorze danych cyfr MNIST
Możemy wyszkolić powyższe sieci neuronowe na zbiorze danych cyfr MNIST, dołączając następujący blok kodu:
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train/255.0, x_test/255.0
x_validate, y_validate = x_test[:-10], y_test[:-10]
x_test, y_test = x_test[-10:], y_test[-10:]
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), optimizer="sgd", metrics=["accuracy"],)
model.fit(x_train, y_train, validation_data=(x_validate, y_validate), batch_size=64, epochs=10)Wyniki szkolenia tych sieci neuronowych na zbiorze danych cyfr MNIST są następujące.
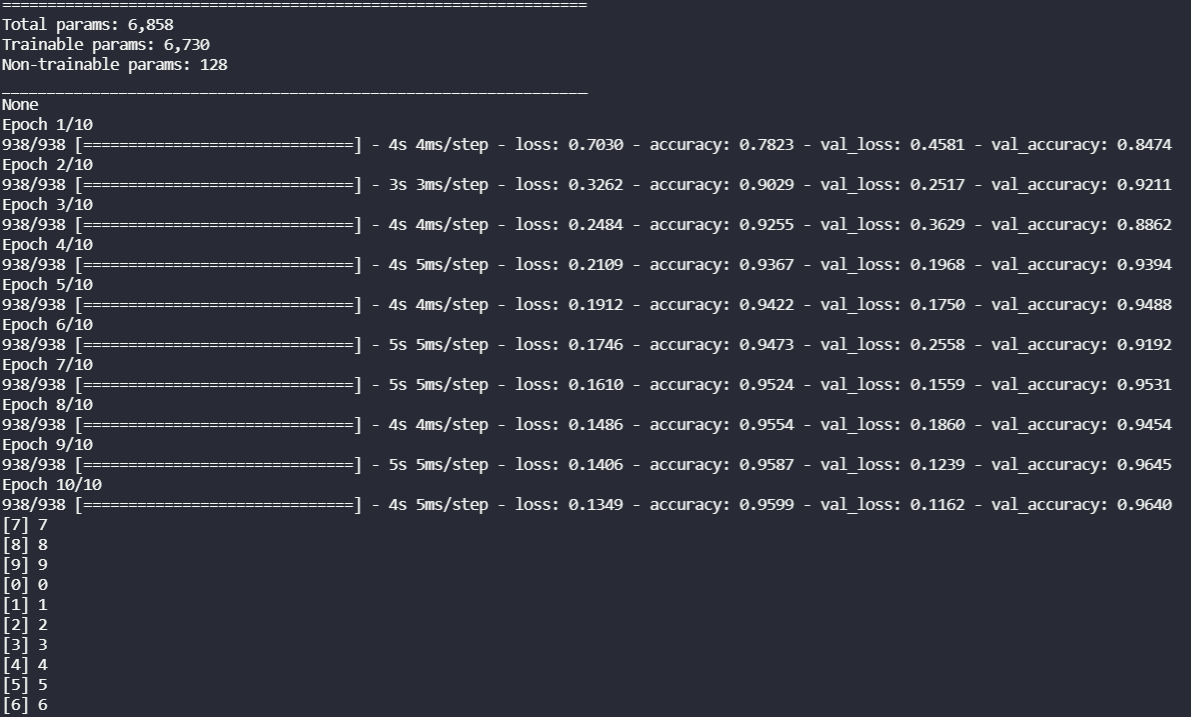
RNN w 10 epokach.
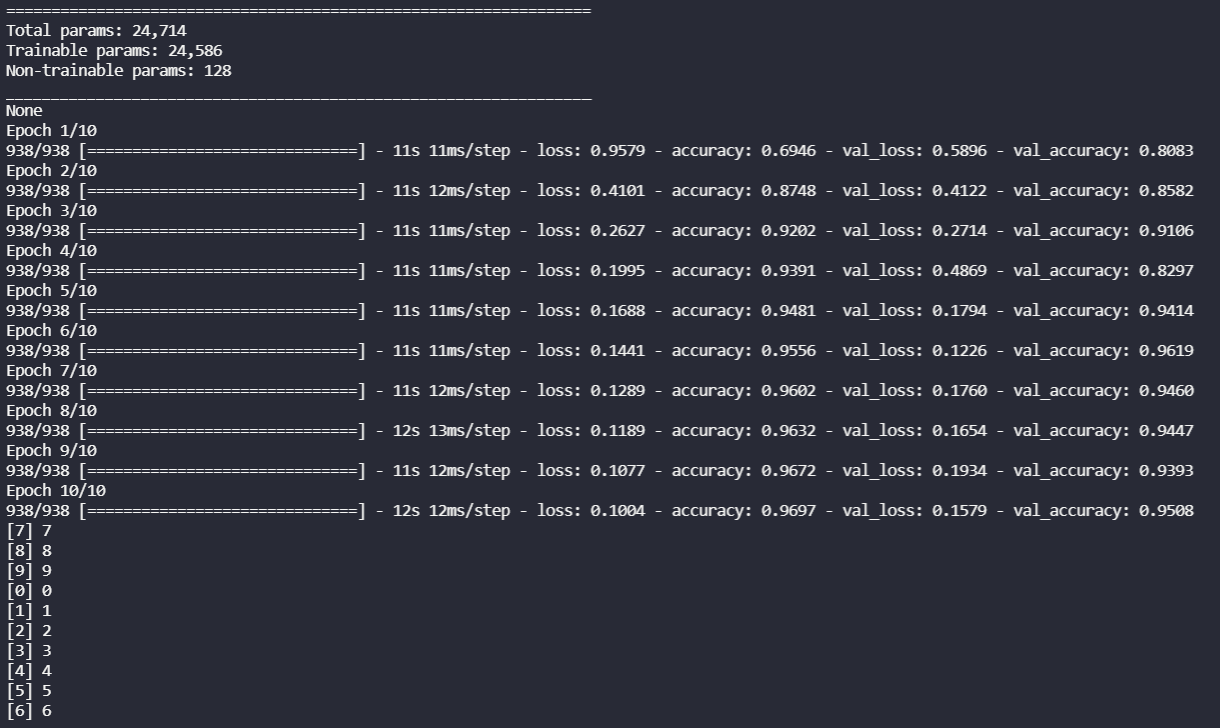
LSTM w 10 epokach.
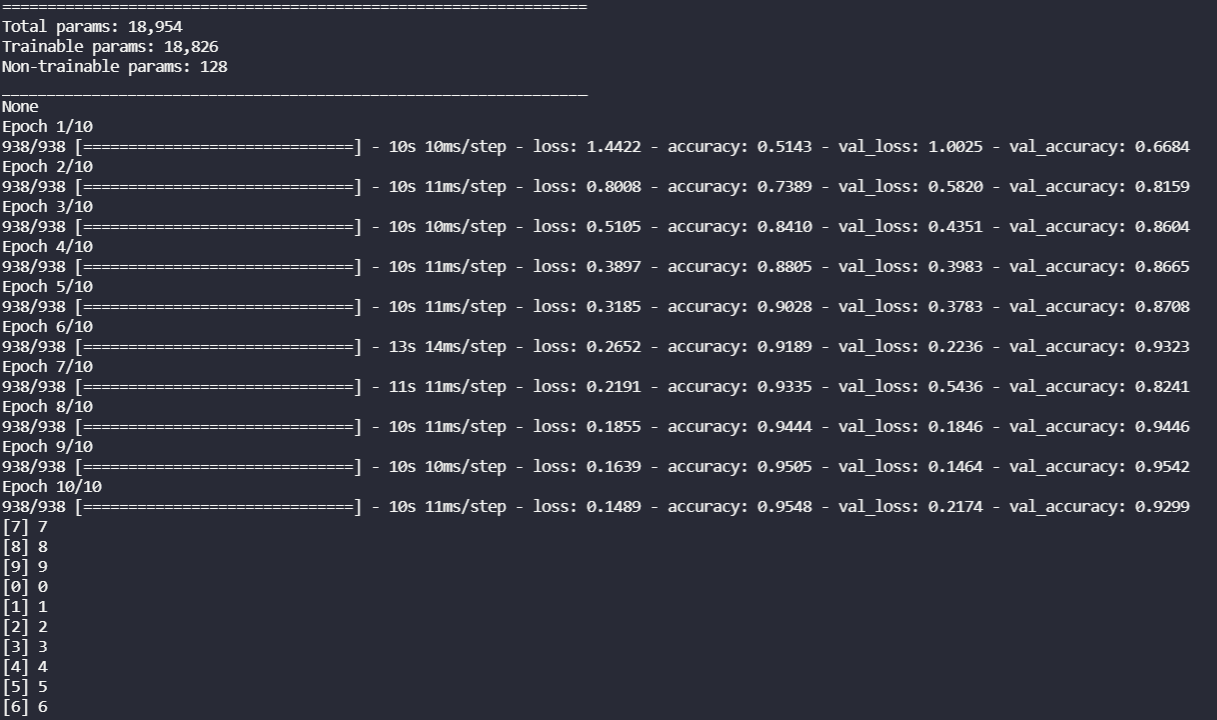
GRU w 10 epokach.
Podsumowanie sieci RNN, LSTM i GRU
W tym artykule dowiedzieliśmy się czegoś o sieciach RNN, LSTM i GRU. Przedstawiliśmy krótką historię każdej z nich, zaczynając od sieci RNN w latach 80. ubiegłego wieku, przechodząc do sieci LSTM w latach 90. i GRU w latach 2010.
Następnie przyjrzeliśmy się implementacji każdej z nich w Pythonie za pomocą Keras i biblioteki TensorFlow. A na koniec porównaliśmy je sobie na zbiorze danych cyfr MNIST. Bardziej dogłębną analizę znajdziesz tutaj: porównanie sieci RNN, LSTM i GRU.
Oryginał tekstu w języku angielskim przeczytasz tutaj.