Null: dlaczego programiści go nienawidzą

Jak społeczność programistów mamy wiele tematów do dyskusji, sporo z nich to tematy zastępcze, takie jak tabulator czy spacja, camelCase czy snake_case, średnik czy też jego brak. Mamy również pewne utarte schematy myślenia oraz odwiecznych wrogów “dobrego” programisty. Jednym z takich wrogów jest Null, jak myślimy o Null, to prawie jakby przerażający potwór chował się za naszymi plecami. Czy jednak jest czego się bać?
Czym jest Null
Null to wskaźnik na pustkę i oznacza brak wartości. Po raz pierwszy wystąpił w językach programowania w latach 60. ubiegłego wieku. Tony Hoare uważany za twórcę Null, stwierdził w swojej prezentacji, że był to błąd warty miliard dolarów. W prezentacji Tony Hoare cytuje swojego kolegę Edsger Dijkstrę:
If you have a null reference, then every bachelor who you represent in your object structure will seem to be married polyamorously to the same person Null
Ten cytat jest znamienny, jak zresztą cała prezentacja Hoare. Otóż wynika z niej dobitnie, że największym problemem Null jest fakt, że może on wystąpić wszędzie i każdy typ danych może wskazywać na Null. Inaczej mówiąc, kiedy deklarujemy wartości typu X, to nasza wartość może być elementem zbioru X lub być Null.
W ten sposób Null staje się ukrytym szpiegiem, agentem udającym każdy typ danych. Programiści w celu zabezpieczenia się przed wskazywaniem na Null musieli pisać bardzo defensywny kod pełen warunków sprawdzających. Najbardziej reprezentatywnym przykładem języka, który miał z tym problem jest Java i jej “Null pointer exception”.
W tym miejscu warto nadmienić, że Null nie występuje tylko pod tą nazwą, różne języki różnie go nazywają. Lisp i Pascal określają go jako nil, Python jako None, natomiast JavaScript ma dwie oddzielne wartości: undefined i null, które są ekwiwalentne i razem tworzą tzw. “nullish”.
Nie taki straszny jak go malują
Null jako element każdego typu danych to ewidentnie pomyłka, co do tego nie ma wątpliwości. Jeśli jednak wiemy, co może być opcjonalnie ustawione, a co jest zawsze ustawione, sytuacja ulega zmianie. C#, TypeScript, Kotlin czy Python MyPy posiadają możliwość definiowania typu danych jako Nullable, co oznacza, że Null nie jest już ukrytym szpiegiem, ale całkowicie jawnie zadeklarowaną możliwością, z jaką zobowiązani jesteśmy sobie radzić.
Dzięki takiemu czytelnemu wskazaniu kompilator jest w stanie wyłapać wszystkie zmienne, które mogą być opcjonalne oraz wymusić sprawdzenie ich przed użyciem. Fakt posiadania tej wiedzy powoduje, że Null jest jawny i reprezentuje opcjonalność wartości.
Do czego używać Null?
Otóż ogromną wadą Null jest brak kontekstu, a to znaczy, że możemy go używać jak każdej innej wartości, w jednym miejscu oznaczać nim błąd a w drugim opcjonalność. Język Java i jego “Null Pointer Exception” utarły w programistach sposób myślenia, według którego, jak widzimy Null, to od razu znaczy, że może coś poszło nie tak, jakby to był swoisty symbol błędu programu.
Null oznacza brak wartości i tak powinien być stosowany. Jeżeli użytkownik może nie mieć wpisanego pola “second name”, to dużo lepiej oznaczyć to pole jako Null niż -1, 0, “” czy też każdą inną arbitralnie wybraną wartością.
Co do obsługi błędów, języki oznaczające brak wartości jako Null mają oddzielny koncept do błędów, a są to wyjątki. Tak więc nie używajmy Null jako reprezentacji błędu, używajmy do tego wyjątków.
Zastępowanie Null innymi wartościami
Języki programowania mają z reguły jedną reprezentację “nicości”, bardzo często jest to właśnie Null. Mimo tego, że to właśnie Null reprezentuje opcjonalność, programiści przez złą sławę tego słowa, starają się go omijać, czasami w kuriozalny sposób.
Pusty ciąg znaków, jako informacja, że nie ma błędu
Error: String = ‘’ // identyczny zapis w Kotlin i TypeScript
Taki właśnie kod ostatnio miałem przyjemność czytać. Co mi mówi taki kod? Tyle że nasz błąd reprezentowany jest, jako ciąg znaków, oraz że prawdopodobnie jego brak jest oznaczany, jako pusty ciąg znaków. Używanie pustego ciągu znaków ma sens w kwestii bycia elementem neutralnym.
Otóż wszystkie operacje na ciągach znaków z pustego znaku zrobią dalej pusty znak. Innymi słowy - pusty znak poprawnie przejdzie wszystkie operacje na ciągach znaków, bez konieczności dodawania rozgałęzień logicznych. To się zgadza, ale w przypadku naszego kodu, tak naprawdę celem jest powiedzenie, że błąd nie występuje, mamy do czynienia z jego brakiem.
Pusty ciąg znaków wygląda w tym użyciu karykaturalnie, trochę tak jakbyśmy bali się wstawić Null, a zamiast tego wzięli pierwszą opcję, która była pod ręką.
Error: String | null = null // TypeScript
Error: String? = null // Kotlin
Ustawiamy nasz błąd w stan braku - Null. Jeśli widzimy, że error ma wartość Null, to jasne jest, że oznacza to brak błędu. Poprzez zapis String | Null oznaczamy error jako Nullable i kompilator będzie w stanie nam powiedzieć, że wartość może wskazywać na Null, obroni nas również przed używaniem tej wartości bez sprawdzenia.
Pusty obiekt jako brak użytkownika
user = {} // JavaScript
Znowu zamiast Null używamy arbitralnie wybranej wartości. W tym wypadku jest to pusty obiekt, a dlatego, że docelowy użytkownik jest reprezentowany jako obiekt, a użycie metody na pustym obiekcie nie zwróci nam błędu (przynajmniej jest tak w JavaScript).
Wciąż jest to defensywne, bo oznacza, że wolimy schować problem pod dywan i udawać, że użytkownik zawsze jest ustawiony. Często idzie się jeszcze dalej i robi się obiekty, które mają wypełnione pola, jest to tzw. Null Object Pattern. Jeśli użytkownik może nie być ustawiony, to znaczy, że powinniśmy mu przypisać wartość oznaczającą brak wartości.
user: User | null = null // TypeScript
Teraz wszystko jest jasne, nie ma użytkownika. Można się przyczepić, że kod teraz wymaga dodatkowych warunków. Tak, wymaga, ale lepiej dodać warunek niż liczyć na domniemane zachowanie kodu, który potrafi pracować z użytkownikiem, a nie do końca z jego wydmuszką.
Znajdź indeks
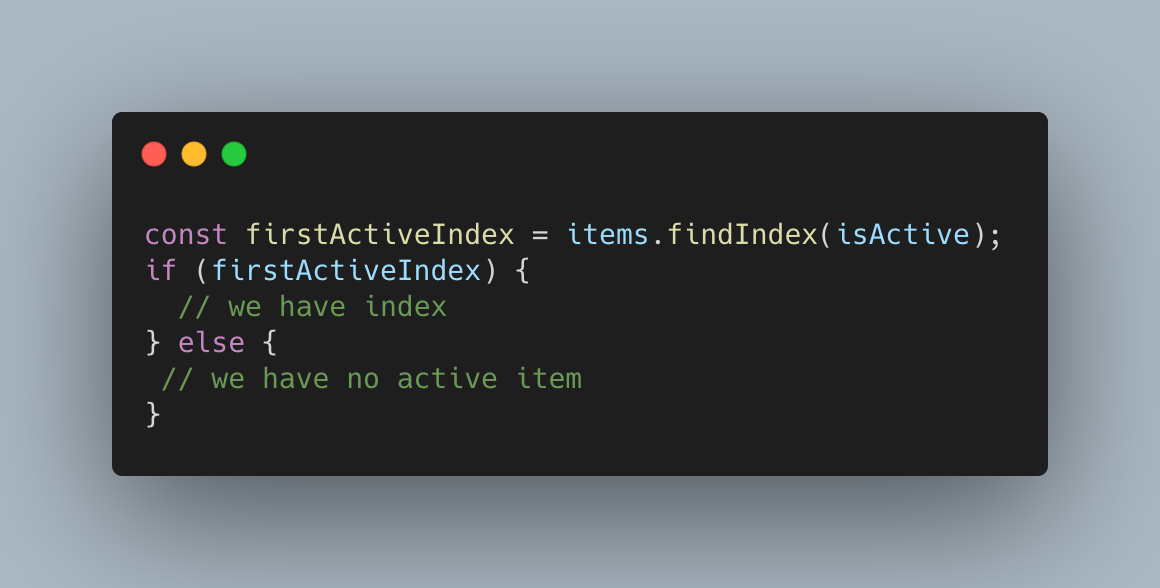
W języku JavaScript istnieje funkcja w obiekcie tablicy - findIndex. Funkcja ta w przypadku braku znalezienia wyniku zwraca -1. Jest to ponownie sytuacja, kiedy brak oznaczamy inną wartością.
Ponownie wartość ta jest tego samego typu, a że findIndex zwraca liczbę, to i brak jest liczbą. Problem z tym jest o tyle większy, że liczba ujemna nie jest falsy (wartość, która sprowadzona do wartości logicznej daje False). A oznacza to, że poniższy kod jest błędny
Jest błędny, ponieważ wszystkie możliwe wyniki funkcji findIndex wejdą nam do pierwszego bloku warunkowego. Gdyby findIndex zwracało Null w przypadku, gdy indeks nie jest znaleziony, kod byłby poprawny.
Wartość -1 jest w wielu językach programowania pewnym standardem dla funkcji wyszukującej indeks. Tak więc wybranie jej w przypadku findIndex jest uzasadnione. Nie zmienia to faktu, że w mojej ocenie ten standard jest błędny.
Może Maybe
Wielu programistów ma bardzo negatywne zdanie o Null i zamiast niego wybierają strukturę Maybe/Optional. Struktura ta oparta jest na oznaczonej unii/sumie, która posiada dwie składowe - Just X oraz Nothing. X w tym zapisie oznacza parametryzowanie, jest to dowolny typ danych. Tak, więc mamy jasny zapis, albo coś jest - Just, albo tego nie ma, Nothing.
Część języków posiada koncept Maybe, jako idiomatyczny sposób obsługi braku wartości i nie posiadają równocześnie Null. Są to języki jak Elm, OCaml, Rust czy Haskell. Można powiedzieć, że koncept Maybe ma przewagę w kwestii kontekstu. Otóż w jasny sposób informuje, że powinien być używany do reprezentacji opcjonalności. Popatrzmy na ten piękny kod w OCaml:
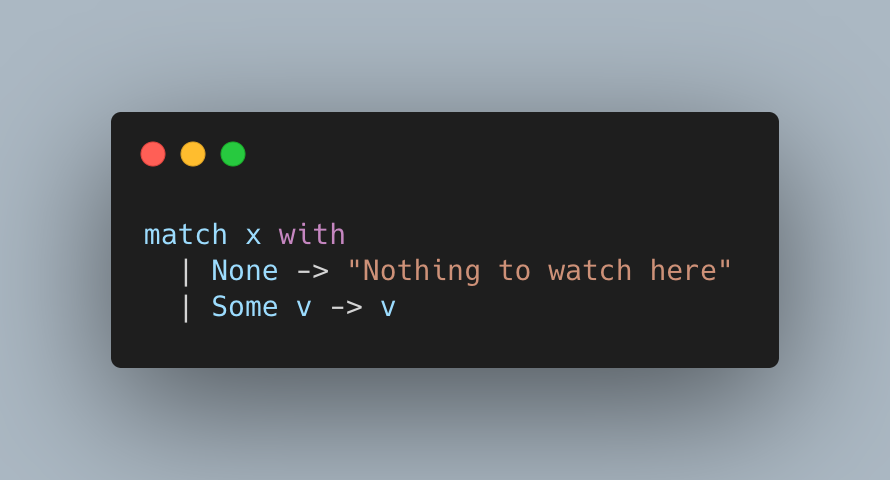
Nie ma tu za dużo do zastanowienia, wszystko jest jasne, wiemy, co się stanie, jak wartość jest i co dzieje się, jeśli jej nie ma.
Maybe uważane jest za coś lepszego niż Nullable, ale obiektywnie rzecz ujmując głównie dlatego, że słowo Null powoduje u nas alergię. Oczywiście muszę być sprawiedliwy i powiedzieć, że w językach posiadających Maybe, a są to głównie języki rodziny ML, dostajemy również dodatkowo właściwości Funktora czy Monady. Niestety tych właściwości nie możemy mieć z Nullable z powodów wykraczających poza ten artykuł.
Duża część języków nie posiada wbudowanego konceptu Maybe, natomiast możemy go symulować. Symulacja niestety nie jest do końca świetnym pomysłem z tego powodu, że język ciągle będzie posiadał Null, a Maybe będzie alternatywą, która w jakiś sposób z oryginalnym Null będzie musiała współpracować. Nie oznacza to, że jest to niemożliwe, natomiast płacimy za to pewną cenę.
Nullable i dodatkowa składnia
Języki posiadające Nullable dodają również składnię, która wspiera ten koncept. Poniżej całkowicie poprawny kod Kotlin i równocześnie JavaScript:
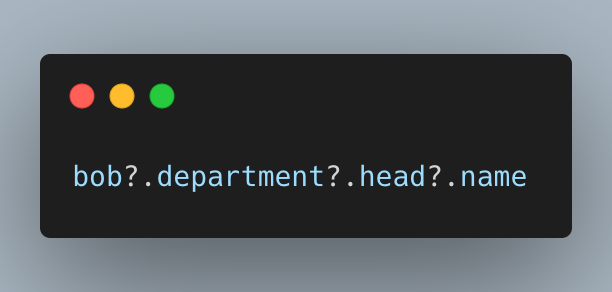
Tzw. Elvis operator albo optional chaining operator pozwalają na dojście do dowolnie zagnieżdżonego elementu struktury bez jawnego pisania warunku.
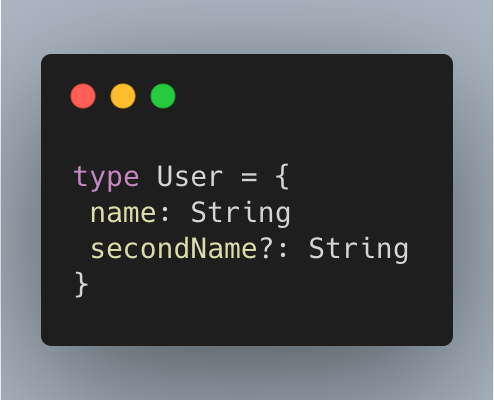
TypeScript umożliwia zapis pól opcjonalnych poprzez znak zapytania. W powyższym przypadku jest to skrócony zapis typu String | undefined, a tak jak wspomniałem, undefined i null są ekwiwalentne w TS/JS. W przypadku zrezygnowania z Null, od razu rezygnujemy z części składni języka. Jest to ewidentnie koszt.
Za dużo opcjonalności
Często zdarza się tak, że nasz model danych ma wiele opcjonalnych pól, drugorzędne w tym przypadku jest, czy nasz język będzie reprezentował opcjonalność jako Maybe, czy Nullable. W obu przypadkach taka sytuacja jest niekorzystna. Popatrzmy na ten kod:

Oba pola w interfejsie Response są opcjonalne, ale czy odpowiedź serwera może zawierać i dane wynikowe i błąd, oraz czy może nic nie zawierać? Nasz model danych pozwala na za dużo elastyczności, która z perspektywy logiki aplikacji nie powinna się zdarzyć. Spróbujmy więc zmienić model.

Drugi model nie posiada pól opcjonalnych. Zamiast tego definiuje, że odpowiedź serwera będzie albo sukcesem i będzie zawierała pole data, albo będzie porażką z polem error. Jak widać w tym przypadku, byliśmy w stanie stworzyć taki model stanu, który prawidłowo reprezentuje wszystkie możliwości. W tym przypadku nie jest istotne, jak reprezentowaliśmy opcjonalność, gdyż ją całkowicie wyeliminowaliśmy.
Przestań kopać się z koniem
Język, którego używasz ma Null? To znaczy, że właśnie Null reprezentuje opcjonalność. Nie ma sensu uciekać od Null poprzez wartości alternatywne. Jeśli coś jest puste, podstaw pod to Null, a nie jakąś liczbę ujemną czy pusty ciąg znaków. Oczywiście możesz zaimplementować Maybe i omijać Null, ale powodem jest bardziej preferencja niż realna różnica.
Największym błędem przy stworzeniu tego konceptu nie był Null per se, ale fakt, że wszystko nim mogło zostać. Nowsze języki programowania, wprowadzając Nullable całkowicie likwidują tę drogą pomyłkę. Tak, więc programisto, opcjonalne dane to nasz dzień powszedni, a Null to wartość, która je reprezentuje.