Co, gdy Jądro Linux jest zbyt wolne?

Zastanawialiście się kiedyś, jak szybkie jest Jądro Linux? Jak szybko potrafi przetwarzać dane i jakie ma ograniczenia? Prawdopodobnie niewielu programistów staje przed takimi problemami w codziennej pracy.
Okazuje się jednak, że są branże, gdzie takie rozważania są - jeśli nie na porządku dziennym - to z całą pewnością bardzo częste. Jednym z takich obszarów jest telekomunikacja, gdzie powszechnie wykorzystuje się systemy bazujące na Jądrze Linux.
Ograniczenia
W obliczu wymagań, jakie przynosi rozwój technologii 5G, okazuje się, że systemy te, a zwłaszcza ich sieciowa część, mają dość istotne ograniczenia. Aby je pokazać, przeprowadźmy proste obliczenia.
Załóżmy, że mamy interfejs 10 Gb. Taki interfejs jest dość często spotykany w rozwiązaniach serwerowych. Zakładamy prędkość danych w kierunku do sieci, dla technologii 5G. Jak szybkie musi być oprogramowanie, aby obsłużyć taki interfejs? Policzmy.
Zakładamy, że mamy małe pakiety, z jakimi często spotykamy się w sieciach radiowych, a więc 64 bajty. Dla 10 Gb interfejsu daje to w przybliżeniu 14,9 miliona pakietów na sekundę. Zobaczmy zatem, jaki mamy budżet czasowy na przetworzenie pojedynczego pakietu.
Zakładając taktowanie procesora na 2 GHz, dowiadujemy się, że jeden cykl trwa 0,5 ns. Dla tej ilości pakietów czas na przetworzenie jednego, to zaledwie ~67.5 ns, a to daje nam 135 cykli procesora. Czy stos sieciowy Linuxa jest na tyle szybki, aby podołać temu wyzwaniu? Zobaczmy, jak w dużym uproszczeniu wygląda droga pakietu w Linuxie.
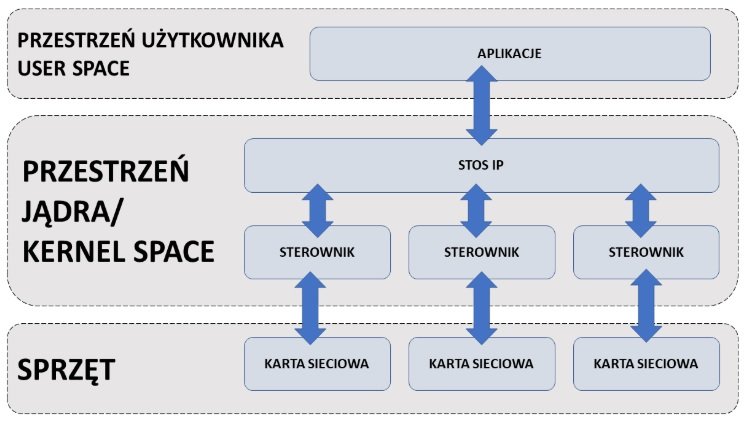
źródło: Ericsson
Jak widać na schemacie, pakiet przechodzi z aplikacji w przestrzeni użytkownika do przestrzeni jądra. Jest to operacja bardzo kosztowna. W dostępnych źródłach można się spotkać wartościami rzędu setek nanosekund.
Kolejne problemy związane są z koniecznością kopiowania pakietu pomiędzy przestrzeniami użytkownika i jądra, a także obsługą wywołań systemowych. Mówimy tu o czasach rzędu 100 ns na kopiowanie i drugie tyle na system call. Powoduje to, że sprostanie złożonemu ograniczeniu czasowemu wydaje się mało realne.
Istotnie - jak pokazują badania - wydajność stosu sieciowego Linuxa, zwłaszcza w liczbie pakietów przetworzonych na sekundę, nie jest imponująca. Jest to poważne ograniczenie zwłaszcza w przypadku projektowania i tworzenia oprogramowania dla urządzeń sieciowych czy telekomunikacyjnych.
Szczególnie w przypadku infrastruktury telekomunikacyjnej, istotnym problemem staje się przetwarzanie ogromnych ilości relatywnie niewielkich pakietów. Dotychczas pewnym standardem w branży było wykorzystywanie wysoce wyspecjalizowanych w przetwarzaniu pakietów, tzw. network processorów, co wymuszało stosowanie określonych architektur i powodowało pewne trudności w budowie urządzeń oraz tworzeniu oprogramowania, które często było mocno powiązane z daną platformą. Jednak rozwój technologiczny i pojawienie się nowych trendów - zwłaszcza w obszarach wirtualizacji i przepustowości łączy - zaowocował nowym podejściem do budowy infrastruktury telekomunikacyjnej.
Jeśli przyjrzeć się ogólnie dostępnym specyfikacjom 3GPP (konsorcjum określające standardy dla sieci mobilnych) oraz dokumentacji dla 5G, udostępnianym przez producentów infrastruktury, np. Ericsson, możemy zaobserwować pojawienie się rozwiązań opartych na chmurze i wirtualizacji infrastruktury. Powoduje to, że część przetwarzania pakietów odbywać się będzie w aplikacjach pracujących w wirtualnym środowisku, którym to aplikacjom należy dostarczyć pakiety, zachowując przy tym odpowiednią wydajność i szybkość przetwarzania.
Rozwiązania
Podobne problemy pojawiły się w obszarach związanych z rozwojem samej wirtualizacji, np. sieciach wirtualnych. Powodowało to konieczność znalezienia rozwiązania problemu ograniczonej przepustowości jądra, które okazało się wąskim gardłem. Pojawiło się kilka rozwiązań tego problemu, które stosowały różne filozofie. Jedna to „zero copy”, druga to „Kernel bypass”. Wspólnie zyskały one nazwę Data Plane library.
To, co je charakteryzuje :
- programowanie “w Linuxie”
- zazwyczaj brak protokołów
- własne implementacje protokołów (obecnie są już gotowe frameworki)
- nowe sterowniki dla urządzeń
- zazwyczaj specjalne zarządzanie pamięcią
- własne struktury
Przykłady to biblioteki open source data plane:
- DPDK Data Plane Development Kit
- ODP Open Data Plane
- VPP Vector Packet Processing
W Ericsson, zespół, w którym pracuję, znalazł się w obszarze sieci 5G i musiał zmierzyć się tym problemem dla nowego projektu aplikacji do symulowania i testowania wydajności sieci 5G. Po poszukiwaniach i analizie dostępnych ówcześnie rozwiązań wybraliśmy DPDK - Data Plane Development Kit.
Czym jest DPDK?
W skrócie DPDK to zestaw bibliotek działających głównie w przestrzeni użytkownika, na szerokiej gamie procesorów x86, ARM, PowerPC oraz sterowników dla kart sieciowych. Biblioteki te zapewniają szybkie przetwarzanie pakietów, dając możliwość pełnego wykorzystania możliwości, jakie dają nowoczesne karty sieciowe 10 Gb i 40 Gb oraz w środowisku wirtualnym, korzystając ze sterowników dla interfejsów wirtualnych.
Tak dokładniej, to utworzony przez Intela projekt obecnie jest pod opieką Linux Foundation. W pakiecie dostajemy zestaw bibliotek dla określonych środowisk. Tworzą one Environment Abstraction Layer (EAL), czyli warstwę abstrakcji środowiska, która ukrywa specyficzne elementy danego środowiska. Warstwa ta tworzona jest podczas instalacji lub konfiguracji dla danego środowiska i linkowana do aplikacji podczas budowania.
EAL zapewnia również dodatkowe usługi:
- time reference -zapewnia usługi związane z timerami, co pozwala obsługę asynchronicznych callbacków
- general bus access- zapewnia dostęp interfejsu do przestrzeni adresowej PCI
- funkcję dla śledzenia (trace) i debugowania aplikacji
Dodatkowo biblioteki dostarczane z DPDK zapewniają struktury pamięci i zarządzanie pamięcią:
- Memory Manager
- Queue Manager
- Buffer Manager
Mamy również bardzo istotne pool mode drivers (PMD), zaprojektowane do pracy asynchronicznej, co ma wyeliminować narzut związany z przerwaniami. W DPDK znajdziemy też oczywiście zestaw skryptów i narzędzi, a także bogatą kolekcję przykładowych aplikacji.
Jak działa DPDK?
Schemat wygląda w uproszczeniu tak:
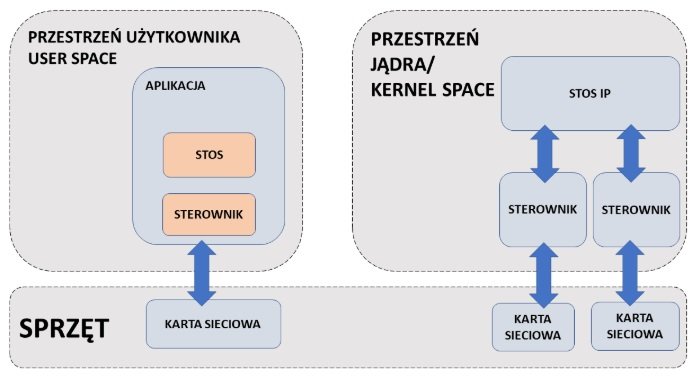
źródło: Ericsson
Ideą działania jest ominięcie stosu i jądra w celu wyeliminowania zmiany kontekstu user space/kernel space, która jest niezwykle kosztowna. Dodatkowo kopiowanie pakietów bezpośrednio z pamięci urządzenia do pamięci w przestrzeni użytkownika eliminuje dodatkowe kopiowanie danych między przestrzeniami. Zyskujemy na tym:
- brak narzutu na kopiowanie danych
- brak przerwań i narzutu związanego z ich obsługą
Niestety rozwiązanie to ma także kilka niedogodności. Interfejsy, które korzystają ze sterowników DPDK, nie są widoczne dla jądra systemu, a więc nie możemy nimi zarządzać przy pomocy standardowych narzędzi systemowych ifconfig, itp.
Kolejna niedogodność to konieczność własnej implementacji stosu protokołów. Obecnie są już gotowe frameworki. Niedogodność ta dla pewnych zastosowań jest zaletą i tak było w naszym przypadku. Aplikacja, którą tworzymy, symuluje pewne elementy sieci 5G i jest wykorzystywana do testowania urządzeń lub zwirtualizowanych funkcji sieci. Testy, które są wykonywane przy pomocy tej aplikacji, to testy wydajnościowe, więc aplikacja musi pracować z przepustowościami takimi, jak testowane systemy lub większymi, jeśli chcemy je przeciążyć.
Zastosowanie własnej implementacji pozwala na pewne uproszczenia w stosie protokołów, co przekłada się na większą wydajność i daje większą kontrolę nad tym, co wysyłamy.
Gdzie można stosować DPDK?
Aktualnie DPDK znajduje zastosowanie w aplikacjach i frameworkach do tworzenia aplikacji przetwarzających duże ilości pakietów oraz w oprogramowaniu urządzeń sieciowych i telekomunikacyjnych, a także przy obsłudze wirtualizacji.
Przykładowe projekty korzystające z DPDK:
- ANS – Accelerated Network Stack
- BESS – Berkeley Extensible Software Switch
- Butterfly – Connects Virtual Machines
- DPVS – Layer-4 Load Balancer
- FD.io/VPP – Fast Data Project
- FastClick – Highspeed Dataplane
- Lagopus – Software OpenFlow 1.3 Switch
- MoonGen – Packet Generator
- mTCP – User-Level TCP Stack
- OPNFV – Open Platform for NFV
- OpenDataPlane
- Open vSwitch – Multilayer Open Virtual Switch
- TRex – Stateful Traffic Generator
- WARP17 – Stateful Traffic Generator
- YANFF – NFF-Go -Network Function Framework for GO (former YANFF)
Podsumowanie
Jak na razie DPDK to głównie rozwiązania niskopoziomowe, ale można założyć, że jak tylko technologia 5G zostanie wprowadzona na większą skalę, pojawią się nowe możliwości dostępne dla użytkowników. Powstanie wtedy zapotrzebowanie na aplikacje wykorzystujące nowe możliwości. Wydaje się, że DPDK dobrze odpowiada na to zapotrzebowanie i znajomość tej technologii może okazać bardzo przydatna w przyszłości.
O autorze:
Marek Jurczyk to Senior Software Developer w Test Tools. Pracuje nad symulacją Data Plane (warstwa przesyłu danych użytkownika) dla sieci 4G/5G. W Ericsson od ponad 7 lat. Poza pracą interesuje sieę turystyką górską, historią techniki a ostatnio również szybownictwem.