

Marcin SzwebsSystem Engineer / DeveloperEricsson
Data Science - buzzword czy prawdziwa rewolucja?
Zobacz, jak wykorzystać Data Science w praktyce. Sprawdź, jak można wykorzystać dane z własnej infrastruktury do rozwoju projektu IT w branży telekomunikacyjnej.
W ostatnich latach pojawia się coraz więcej publikacji związanych z Data Science: książek, artykułów naukowych, wpisów na blogach entuzjastów oraz profesjonalistów zajmujących się zawodowo tą dziedziną. Na forach roztrząsane są dylematy dotyczące wyboru narzędzi (w tym nieśmiertelny wątek „R czy Python”), algorytmów lub hiperparametrów związanych z poszczególnymi algorytmami uczenia maszynowego.
Każda szanująca się platforma e-learningowa ma w katalogu wiele kursów związanych z Data Science, rozumianej jako techniki rozwiązywania zadań/problemów opartych na danych. Doszło do tego, że portal coursera.org oferuje kurs zatytułowany: How to Win a Data Science Competition: Learn from Top Kagglers. Weszliśmy więc na zupełnie nowy poziom: Data Science często nie służy już do rozwiązywania problemu, tylko do wygrywania konkursów, w których dostaje się zbiór danych i kryteria, według których można ocenić, kto najlepiej go przetworzył.
Oczywiście nie ma nic złego w budowaniu kompetencji dzięki rozwiązywaniu wyizolowanych problemów, mało tego, aby zostać ekspertem w jakiejś dziedzinie, trzeba się na niej po prostu skupić. W artykule chciałbym jednak wyjść poza najczęściej spotykane podejście do Data Science i pokazać ją w szerszym kontekście — jako część procesu związanego z realizowaniem celów biznesowych dużej firmy.
Ericsson - biznes oparty na danych
Ericsson dostarcza infrastrukturę telekomunikacyjną, a jego rozwiązania — m.in: sieci radiowe, szkieletowe, platformy z usługami dodanymi, systemy bilingowe, software do zarządzania siecią komórkową — mogą znaleźć zastosowanie w każdym aspekcie działalności operatora. Wszystko to wspiera przesyłanie danych generowanych przez użytkowników końcowych oraz samo generuje dane związane z działaniem infrastruktury i zachowaniem abonentów, którzy z niej korzystają.
Jak nikt inny znamy i rozumiemy nasze systemy, więc oprócz integrowania naszego hardware’u i software’u z siecią komórkową operatora oferujemy także usługi związane np. z optymalizacją sieci radiowych lub zarządzaniem sieciami komórkowymi. Aby dobrze realizować opisaną powyżej działalność, potrzebujemy danych generowanych przez infrastrukturę, którą dostarczamy:
- Nasze produkty działają w bardzo złożonym środowisku, które dodatkowo zmienia się w czasie. Dzięki zebranym danym dostosowujemy tworzone funkcjonalności do rzeczywistych potrzeb operatorów - wiemy, jak zachowują się klienci i ich telefony. Obserwujemy zmieniające się trendy w ich sieciach.
- Dzięki analizie danych wiemy, jaki wpływ na sieć miały wdrożone przez nas zmiany (po stronie hardware’u i software’u).
Podstawowym celem zbierania danych jest więc tworzenie lepszych produktów i zapewnianie klientom ich optymalnego użycia (co przekłada się na większe zyski zarówno dla Ericssona, jak i operatorów).
Dane
Gdy myślimy o pozyskaniu danych gotowych do analizy, często przychodzi nam do głowy „ściągnięcie” plików z surowymi danymi, które trzeba wstępnie przetworzyć, uzupełnić brakującą informację i zapisać w formie gotowej do użycia. Okazuje się, że w wielu przypadkach tak lakonicznie przedstawione zadanie to 90% pracy w projekcie.

Domena, w której generowane są dane, oraz domena, gdzie dane są przetwarzane, są często rozdzielone ze względów bezpieczeństwa, logistycznych i prawnych. Prawdziwym wyzwaniem staje się już zestawienie ciągłego strumienia danych pomiędzy nimi.
Opiszę poniżej ten mechanizm na bazie dwóch rozdzielnych domen: infrastruktury należącej do operatorów oraz infrastruktury Ericssona.
Domena operatora
Największym źródłem danych są stacje bazowe. Kojarzone zwykle z masztami i antenami, to przede wszystkim złożone urządzenia (hardware/software), które zawierają logikę związaną z zestawieniem i utrzymaniem połączenia, zarządzaniem zasobami sieci radiowej itp. Każdy operator używa tzw. Operation Support System (OSS) - platformy do zarządzania siecią. Jest ona źródłem danych o jej konfiguracji.
Oczywiście dane o zachowaniu użytkowników i wykorzystaniu przez nich zasobów radiowych nie powstawałyby, gdyby nie sami użytkownicy i ich urządzenia końcowe (smartfony, tablety, itp.). To ich zachowanie w sieci sprawia, że sieć żyje - jest dynamicznie zmieniającym się systemem, który można obserwować i próbować nad nim zapanować.
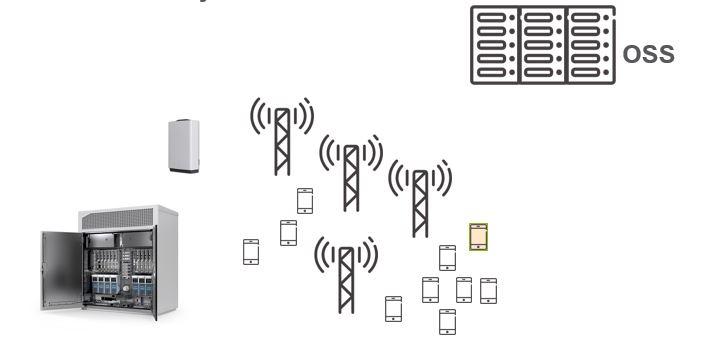
Jakiego rodzaju są to dane? Przede wszystkim mnóstwo statystyk. Każda stacja bazowa (a także inne elementy infrastruktury) generuje co 15 minut informacje o wszystkim, co zdarzyło się w kontrolowanej przez nią sieci radiowej (składającej się zazwyczaj z od 3 do 12 komórek - ang. cells). Pliki z takimi danymi nie zajmują zazwyczaj więcej niż 1MB. Trzeba jednak pamiętać, że stacji bazowych może być w sieci np. 30 tysięcy, plików jest dziennie 96, a dane mogą być zbierane np. przez rok. Do tego dochodzą informacje diagnostyczne o stanie infrastruktury, logi, dodatkowe trace’y związane z analizą wykorzystania zasobów radiowych w czasie na poziomie poszczególnych połączeń. To wszystko może być zapisywane (i nadpisywane) na dysku stacji bazowej albo na zewnętrznych serwerach operatora. Może też być częścią strumienia danych zestawionego pomiędzy operatorem, a Ericssonem.
Domena Ericssona
Zanim rozpocznie się proces transferu danych do domeny Ericssona, muszą zostać uwzględnione ważne kwestie organizacyjne i prawne. Gdy wszystko zostanie już uzgodnione, do rozwiązania pozostają ważne kwestie techniczne:
- jak zapewnić transfer danych, które mają być analizowane pomiędzy operatorem a Ericssonem?
- jak te dane przechowywać? Potrzebna jest cała infrastruktura, będąca całkowicie pod kontrolą Ericssona.
- jak z surowych plików z danymi (o bardzo różnych formatach: od plików xml po częściowo ustrukturyzowane trace’y i logi) wyciągać informacje niemal w czasie rzeczywistym? W jakiej formie ją przechowywać — tak, aby była łatwo i szybko dostępna do analizy?
Te zagadnienia - raz zaimplementowane - muszą być cały czas rozwijane tak, aby odpowiadały zmieniającym się potrzebom i warunkom, w jakich projekt się rozwija. Dochodzą kwestie związane z administrowaniem złożoną infrastrukturą (która obsługuje operatorów z różnych stron świata). Oprócz inżynierów Big Data i specjalistów od domeny IT potrzebni są także inżynierowie telekomunikacyjni znający od podszewki sieci komórkowe i specyfikę domeny operatora - na przykład, aby ocenić jakość i kompletność danych, które zostaną później wykorzystane podczas analizy.
Analiza
Opisałem etap pozyskiwania danych i przygotowywania ich do formy, która jest gotowa do użycia. Okazuje się, że w dużych projektach ten etap może zaangażować np. 80% środków przeznaczonych na projekt (jeśli chodzi o kwestie roboczogodzin, uwzględniając koszt infrastruktury i jej utrzymania ten współczynnik może być znacznie wyższy).
W końcu czekają na nas dane gotowe do analizy. Teraz należy postawić zespołowi zajmującemu się analizą/ML cele ważne z technicznego i biznesowego punktu widzenia. Trzeba też uwzględnić czynnik ludzki — czyli tych, którzy będą korzystać z efektów tej pracy.
Przedstawię to wraz z opisem zespołu analitycznego, bazując na pracy zespołu Data Science, który jest częścią oddziału R&D Ericsson, zajmującego się rozwojem sieci radiowych.
Cele
Mamy więc dostęp do danych. Dzięki opisanym powyżej etapom czekają na nas w formie gotowej do użycia. To dobry początek do analizy, ale ktoś musi nadać jej użyteczny cel. Dla specjalistów od machine learning nie jest to moment na planowanie swojej pracy. Ilość i różnorodność danych prowokuje do naprawdę ciekawych analiz i wykorzystania zaawansowanych technik. Wiele rezultatów może wyglądać bardzo atrakcyjnie, ale z technicznego i biznesowego punktu widzenia nie wnosić zbyt wiele. Czasami trudno jest to ocenić bez dogłębnej znajomości potrzeb operatora (na poziomie organizacyjnym i biznesowym) albo sieci komórkowej (jako, z technicznego punktu widzenia, złożonego, dynamicznego systemu). Zespół tworzący analizy i wspierający je software współpracuje ze specjalistami od testu i integracji, planowania sieci i tzw. Customer Unitu (czyli oddziału niezajmującego się kwestiami R&D, ale będącego pierwszą linią w kontaktach z klientami Ericssona).
Obie współpracujące strony uczą się od siebie, odpowiadając na dwa pytania: co jest potrzebne i co jest możliwe do zrobienia?
Zespół
Ciągle rozwijamy nasz zespół, a żeby realizować stawiane nam cele, potrzebujemy interdyscyplinarnego miksu kompetencji. Są wśród nas doświadczeni programiści, statystycy, specjaliści od ML/AI i specjaliści od sieci radiowych, jak na przykład ja. Uczymy się od siebie nawzajem, a do puli wnosimy doświadczenia i umiejętności, tworząc rozwiązania wykorzystywane w działaniach operacyjnych Ericsson. Wykorzystujemy różnorodne techniki: od znanych w statystyce od lat metod po najnowsze algorytmy ML. Dowolność rozwiązań może być jednak ograniczona czynnikiem ludzkim.
Human first
Prezes Kaggle Jeremy Howard w artykule pod znamiennym tytułem "Specialist Knowledge is Useless and Unhelpful" napisał słowa do ekspertów z różnych dziedzin:
(...) Dekady waszej specjalistycznej wiedzy są nie tylko mało przydatne - one są w istocie bezużyteczne. Wasze wyrafinowane techniki są gorsze niż ogólne metody. (...) Trudno jest się z tym pogodzić ludziom, którzy przywykli do nauki starego typu (...)
Można dyskutować, czy ta kontrowersyjna wypowiedź nie jest po prostu jeszcze jednym zuchwałym manifestem CEO z Doliny Krzemowej, gdzie bardzo często spotyka się opinie, że świat da się uzdrowić za pomocą appek. Niemniej zauważalne są pewne trendy wskazujące na to, że w telekomunikacji pewną część zadań zarezerwowanych dla ekspertów przejmuje software. Np. optymalne skonfigurowanie relacji pomiędzy zasobami radiowymi sąsiednich stacji bazowych już nie musi opierać się na człowieku. Taka funkcjonalność jest częścią większej koncepcji nazywanej Self Organized Networks (SON). Z drugiej strony potrzebni są też specjaliści, którzy będą administrować SON i integrować ją z resztą sieci (więc częściowo zajmą oni miejsce zastępowanych przez software inżynierów).
Obecnie ostatnie słowo należy jednak do człowieka, a ten fakt musi uwzględniać też Data Science. Oczekuje się, że wykorzystane metody będą dawały wartościowe rezultaty, a jednocześnie (na tyle, na ile to możliwe) będą przejrzyste, jeśli chodzi o sposób, w jaki je osiągnęły.
Praca zespołu Data Science może być wykorzystywana w wielu obszarach, np. :
planowanie i optymalizacja sieci
planowanie nowych funkcjonalności sieci
ocena wpływu nowego software’u lub zmiany konfiguracji na działanie sieci
Inżynierowie wykorzystują rezultaty (oraz narzędzia) stworzone przez nasz team jako wsparcie w swojej pracy. Nikt nie lubi black boxa, który ukrywa reguły wnioskowania i za nic nie bierze odpowiedzialności — szczególnie tam, gdzie konsekwencje pomyłki wiążą się z wymiernymi stratami finansowymi lub wizerunkowymi. Specjaliści Data Science muszą brać to pod uwagę.
Problem ten znany jest też np. w bankowości inwestycyjnej, gdzie algorytmy bez nadzoru człowieka potrafiły doprowadzić inwestorów do dużych strat — zanim ktoś wyłączył możliwość realizowania przez nie transakcji. Na inne niebezpieczeństwo zwraca uwagę Cathy O’Neil, matematyczka zajmująca się Data Science, niegdyś pracownica funduszu hedgingowego, a obecnie gorąca orędowniczka ograniczenia wpływu algorytmów na nasze życie.
W swojej książce „Broń matematycznej zagłady” (wiele mówiący tytuł polskiego tłumaczenia) wskazuje na przykłady algorytmów, które w negatywny sposób wpływają całe grupy zawodowe lub społeczności w USA. Automatyczne systemy eksperckie analizują duże ilości danych i wspierają urzędników w podejmowaniu ważnych ze społecznego punktu widzenia decyzji. Czasami wręcz, aby wykluczyć uznaniowość, rezultat zwracany przez taki system jest wiążący dla urzędnika. Złożone reguły wnioskowania i algorytmy software’u nie są znane użytkownikom i nie ma od nich odwołania. Czasami dotyczy to niesłusznie źle ocenionych nauczycieli, a czasami słabszych grup społecznych, które skazuje się na dodatkowe wykluczenie i brak szansy na poprawę swojego losu. Dzieli nas cienka granica pomiędzy aplikacjami, które będą nam pomagać w pracy, a światem opisywanym w serialu “Black Mirror”. Tu wykraczamy już jednak poza temat analizy danych w sieciach komórkowych.
Na zakończenie
Data Science jako dziedzina nauki i techniki nie powstała sama dla siebie. Już od początku oparte na niej inicjatywy były częścią bardziej złożonych procesów. Z jednej strony wspiera je, z drugiej sama potrzebuje ich wsparcia. Pokazałem to na przykładzie mojej firmy, ale każda inna organizacja, która swój model biznesowy opiera na danych, ma swoją podobną historię. Ważne, aby mieć tego świadomość i nie zamykać się w „swojej działce”.