CPython - wykonanie kodu bajtowego

Python jako język programowania z czasem zyskuje coraz większą popularność. Szeroki wachlarz modułów pozwala na stosowanie go w tak wielu obszarach branży IT, że właściwie szybciej byłoby wymienić obszary, w których jeszcze go nie ma, niż te, w których już jest. Poza modularnością, aspekty takie jak multiplatformowość czy garbage collector z całą pewnością przyczyniają się do szybkości tworzenia rozwiązań skrojonych na miarę naszych potrzeb.
Po uruchomieniu skryptu, jego tekstowa forma kompilowana jest do postaci kodu bajtowego, który następnie wykonywany jest przez maszynę wirtualną. W tym artykule przyjrzymy się nieco dokładniej temu procesowi. W pierwszej kolejności powiemy sobie o tym, jak właściwie maszyna wirtualna przetwarza kod bajtowy, a następnie omówimy obiekty kodu Pythona. Nieco mimochodem opowiemy sobie również o synchronizacji wątków za pomocą GIL. Artykuł opiera się o implementację CPython, ilekroć więc będziemy mówić o Pythonie, należy utożsamiać go właśnie z CPythonem.
Na Pythona możemy spojrzeć jak na program, w naszym wypadku napisany w języku C, którego rolą jest wykonywanie programów napisanych w innym języku, niezależnie między innymi od systemu operacyjnego, na którym jest uruchomiony. Jeżeli kiedykolwiek mieliście okazję pisać w C, być może pisaliście bardzo prosty program imitujący kalkulator: taki program na wejście mógłby przyjmować kod operacji, na przykład 0 jako kod dodawania, 1 jako odejmowania, 2 mnożenia i tak dalej, oraz jego parametry.
Trzymając się tego przykładu, ciąg “0 1 2” wprowadzony na wejście generowałby na konsoli “3” jako wynik dodawania. Aby móc wykonywać kilka operacji, nasz program musiałby obsługiwać kod zakończenia działania, na przykład -1. Pomijając detale implementacyjne, mógłby on wyglądać mniej więcej tak:
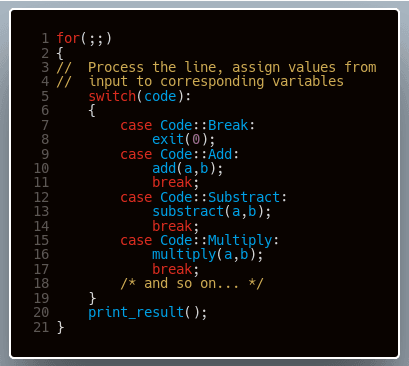
Nie oszukujmy się, nie jest to najpiękniejsze rozwiązanie świata, ale obrazuje pewną ideę. Na ten nasz prymitywny program możemy bowiem spojrzeć nieco inaczej - definiuje on oraz przetwarza pewien zestaw komend, identyfikując je po ich identyfikatorach, oraz zarządza ich realizacją poprzez wywołanie handlera odpowiedniego dla komendy wraz z jej parametrami. Nasz system komend możemy rozszerzać, dodając kolejne funkcjonalności. Moglibyśmy np. chcieć dodać możliwość zapisania wartości pod konkretną nazwą oraz odczytanie wartości spod konkretnej nazwy - w tym celu zaimplementowalibyśmy komendy store(name, value) oraz load(name).
Jeżeli w ten sposób zaczniemy rozszerzać nasz system komend, dodamy stos, z którego będziemy odczytywać parametry (zamiast przekazywać je przez parametry wywołania funkcji) oraz na który będziemy zapisywać wyniki obliczeń, okaże się, że małymi kroczkami zaczniemy zbliżać się w kierunku czegoś, co przypominać będzie maszynę wirtualną zaimplementowaną wewnątrz interpretera Pythona.
Za przetwarzanie rozkazów kodu bajtowego odpowiedzialna jest funkcja PyEval_EvalFrameEx (która w efekcie wywoła _PyEval_EvalFrameDefault zdefiniowaną nieco niżej), stanowiąca serce maszyny wirtualnej. W gruncie rzeczy jest to pętla po wszystkich instrukcjach kodu bajtowego, w której środku znajduje się ogromny switch-case, odpowiedzialny za przetwarzanie kolejnych rozkazów maszyny.
Jeżeli do tej pory ktoś interesował się tym, jak właściwie działa Python, pewnie prędzej czy później natrafił na moduł deassemblera kodu bajtowego - moduł dis. Jednak dla tych z Was, którym jest on obcy, pokażemy jego działanie. Weźmy przykładową funkcję foo:
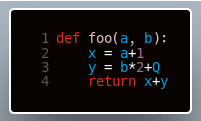
Wynik działania wywołania dis.dis(foo) możemy zobaczyć poniżej:
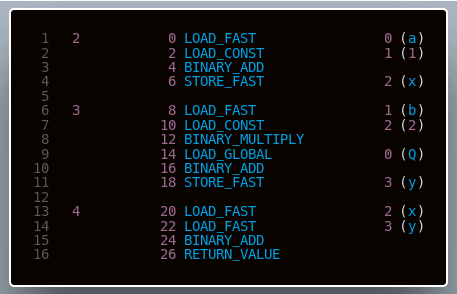
Być może teraz nasza analogia z identyfikatorami komend oraz ich obsługą jest nieco bardziej widoczna. Każdy rozkaz pokazany powyżej możemy przyrównać do naszej komendy. W pliku ./Include/opcode.h zdefiniowane są kody instrukcji kodu bajtowego - na moment, w którym piszę ten artykuł jest ich 165. Rozkaz kodu bajtowego jest dwubajtowy, składa się on z identyfikatora - opcode - oraz argumentu - oparg. Jak widać powyżej, argument jest opcjonalny - rozkaz BINARY_ADD nie przyjmuje żadnych argumentów, pobiera on dwie wartości ze stosu, a wynik operacji umieszcza na jego szczycie.
Kod bajtowy Pythona jest częścią struktury PyCodeObject, która przechowuje inne, dodatkowe informacje wykorzystywane przez maszynę wirtualną podczas jego wykonania. Obiekty kodu (ang. code objects) są wynikiem kompilacji bloków kodu Pythona. Według dokumentacji, blokiem kodu jest: Moduł, funkcja, definicja klasy, komendy wpisywane w trybie interaktywnym interpretera lub za pomocą przełącznika “-c”, a także skrypt przekazany do interpretera na standardowe wejście lub przez parametr wywołania.
Powiedzieliśmy sobie, że Python jest napisany w języku C. Przyjrzyjmy się więc reprezentacji tych obiektów wewnątrz maszyny wirtualnej.
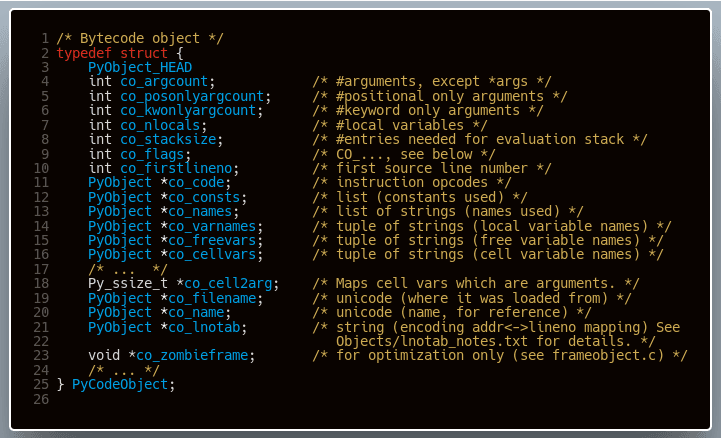
Powyższy fragment struktury PyCodeObject pokazuje nam co właściwie one reprezentują. Omówimy krótko kilka pól tej struktury:
- co_argcount- ilość argumentów przekazanych do bloku kodu reprezentowanego przez obiekt
- co_code- sekwencja instrukcji przetwarzana przez maszynę wirtualną
- co_const- lista stałych wykorzystywanych w bloku kodu
- co_names- nazwy obiektów zdefiniowanych poza blokiem
- co_varnames- nazwy obiektów zdefiniowanych lokalnie wewnątrz bloku
- co_stacksize- rozmiar stosu wymagany przez wymagany do wykonania kodu
Spróbujmy przyjrzeć się temu na przykładzie. Możemy odwołać się do obiektu kodu funkcji poprzez pole __code__. Wypiszmy na konsolę interesujące nas atrybuty obiektu kodu funkcji, którą zdefiniowaliśmy wyżej:
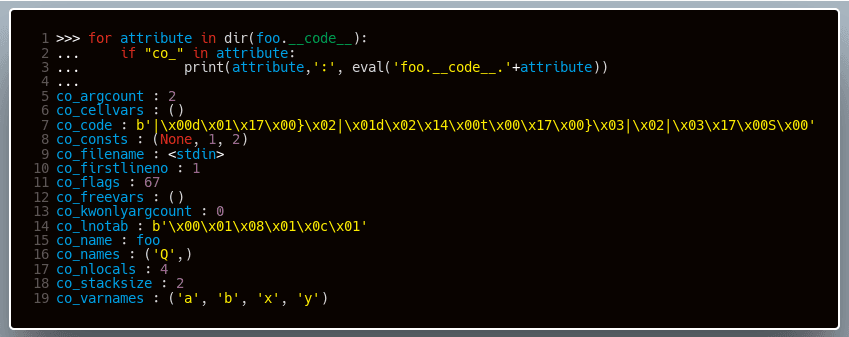
Obiekty kodu nie posiadają jednak informacji o kontekście, w jakim się wykonują. W tym celu w Pythonie istnieją obiekty ramek (ang. frame objects) reprezentowane przez strukturę PyFrameObject. Zanim możliwe będzie wykonanie obiektu kodu, musi istnieć obiekt ramki dostarczający niezbędne do tego celu informacje. Poniższy jej fragment pokazuje nam najbardziej interesujące w tej chwili jej pola.
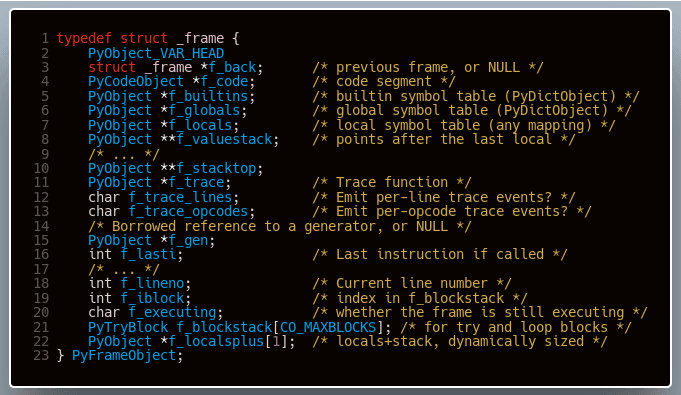
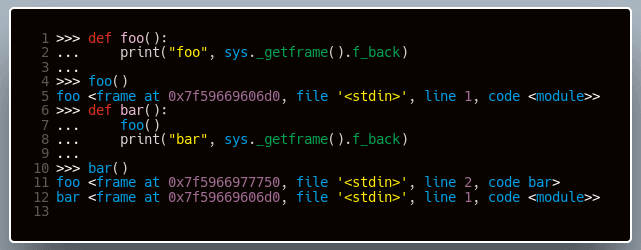
Pierwszym polem jest wskaźnik na poprzednio wykonywany obiekt ramki, aż do pierwszego obiektu ramki, którego wartość w tym polu jest równa NULL. W ten sposób formuje się stos wywołań, co możemy zobaczyć na poniższym przykładzie:
Dodatkowo obiekt ramki przechowuje takie informacje jak:
- f_code- wykonywany obiekt kodu
- f_builtins- przestrzeń nazw builtins, przechowująca takie wpisy jak funkcja print
- f_globals- globalna przestrzeń nazw danej ramki. To tutaj znajdzie się wartość zmiennej Q z naszego przykładowego obiektu kodu omówionego wyżej
- f_locals- lokalna przestrzeń nazw ramki
- f_valuestack- stos wykorzystywany w trakcie wykonywania
- f_stacktop- aktualny wierzchołek stosu
Podobnie jak w przypadku obiektów kodu, z poziomu interpretera Pythona możemy podejrzeć zawartość obiektów ramek. Funkcja sys._getframe() pozwala na pobranie obiektu ramki ze stosu wywołań. Dokładniejszą analizę ramek pozostawimy zainteresowanemu Czytelnikowi :)
Drugim bardzo istotnym, a tymczasowo pominiętym, zadaniem pętli głównej jest obsługa GIL (ang. Global Interpreter Lock). Bez wnikania w szczegóły implementacji wątków w Pythonie, powiemy więc kilka słów na temat synchronizacji wątków za pomocą tego mechanizmu. Do momentu uruchomienia innych wątków niż główny wątek interpretera, GIL jest wyłączony - zostanie on aktywowany w chwili powołania nowych wątków do życia. W chwili stworzenia nowego wątku wywoływana jest funkcja PyEval_InitThreads, której zadaniem jest włącznie mechanizmu GIL oraz jego zajęcie przez wątek główny.
Potem następuje stworzenie nowego wątku, który wykonując funkcję PyEval_AcquireThread próbuje zająć GIL poprzez wywołanie take_gil. W tej sytuacji GIL jest zajęty przez wątek główny, więc nowy wątek przechodzi w stan oczekiwania na jego zwolnienie na okres zdefiniowany na poziomie interpretera (sys.{get,set}switchinterval()). Synchronizacja wątków za pomocą GIL opisana jest krok po kroku w pliku ./Python/ceval_gil.h:
- Pętla główna wątku zajmującego GIL (funkcja
PyEval_EvalFrameEx) musi być w stanie zwolnić go na żądanie innego wątku. W związku z tym, przed każdym wykonaniem rozkazu przez maszynę wirtualną, sprawdzane jest żądanie dostępu do GIL przez inne wątki. Ściślej mówiąc, w każdej iteracji pętli głównej sprawdzany jest stan zmiennejgil_drop_request. - Wątek chcący uzyskać dostęp do GIL, po odczekaniu odpowiedniego okresu czasu, ustawia żądanie dostępu do blokady.
- Po wykryciu żądania, wątek wykonujący kod bajtowy zwalnia GIL oraz oczekuje na zmiennej warunkowej (
switch_cond) upewniając się, że inny wątek niż on sam jest obecnie właścicielem GIL (wartość zmiennejlast_holderjest różna od wartości jego własnego wskaźnika na strukturę stanu wątku, co wskazuje, że inny wątek był w stanie zająć blokadę). Oczekiwanie na zmianę stanu zmiennejlast_holdergwarantuje zajęcie blokady przez inny wątek na wielordzeniowych procesorach. - Wątek, który właśnie zajął blokadę rozpoczyna wykonywanie kodu bajtowego, a wątek, który go zwolnił przechodzi w stan oczekiwania. Po odczekaniu odpowiedniego okresu czasu żąda dostępu do GIL i proces rozpoczyna się od nowa.
Opisany powyżej proces synchronizacji wątków sprawia, że jednocześnie dostęp do maszyny wirtualnej, a więc do czasu procesora, ma tylko jeden wątek. Warto zwrócić uwagę na fakt, że GIL nie jest działaniem zamierzonym - taki mechanizm synchronizacji wątków wynika z trudności zarządzania wielowątkowością w języku C i właściwie należy traktować go jako detal implementacyjny charakterystyczny dla CPythona.
Podsumowanie
Mam nadzieję, że lektura artykułu pozwoliła Ci na lepsze zrozumienie tego, co właściwie dzieje się w chwili, kiedy uruchamiamy interpreter w celu wykonania obliczeń. W artykule pominięto niestety wiele zagadnień związanych z optymalizacją - ich omówienie w tym miejscu zajęłoby jednocześnie zbyt dużo miejsca i niepotrzebnie skomplikowałoby obraz.
Oczywiście znajomość tego typu zagadnień nie jest niezbędna aby programować w Pythonie, jednak może pomóc w pisaniu bardziej wydajnego kodu, a także gdy ktoś zechce spróbować swoich sił w pisaniu własnych modułów do Pythona właśnie w języku C.