Jak bardzo losowy jest Twój program

Załóżmy, że będziemy chcieli rzucić kostką w programie komputerowym. Bez zbędnego zastanawiania się, wywołajmy wbudowaną funkcję Math.random() w JavaScript (lub odpowiednio dla jakiegokolwiek języka) i użyjmy jej tak, by zwrócić wynik z zakresu, jaki jest nam potrzebny, jaki uznamy za stosowny. Jednak, czy nasza liczba będzie wtedy tak naprawdę losowa?
Słownikowa definicja losowości jest następująca:
“przypadkowy, niezależny od decyzji”
To prawie zupełne przeciwieństwo tego, czego oczekujemy od programów komputerowych. Komputery i programy są naturalnie proceduralne i zaprojektowane z konkretnym zamysłem. Jak zatem program składający się z poleceń może stworzyć coś co jest w pewnym sensie losowe?
MDN dla Math.random() daje nam pewien wgląd w to, co się dzieje za kulisami.
“pseudolosowa liczba w przedziale 0-1 (z 0 włącznie, ale wyłączając 1) z przybliżoną stałą dystrybucją w tym przedziale, którą można dopasować do zakładanego zakresu liczb. Implementacja wybiera początkowe ziarno dla algorytmu generacji losowego numeru; nie może być on wybrany lub zresetowany przez użytkownika”.
Generator Liczby Pseudolosowej
Losowe liczby wygenerowane przy pomocy naszych programów są właściwie liczbą pseudolosową, ponieważ rzeczy generowane przez algorytm są z definicji nielosowe.
Niemniej jednak, te liczby na pierwszy rzut oka są na tyle losowe, żeby większość użytkowników się nie czepiała. Istnieje wiele implementacji generatora liczb pseudolosowych i różnią się one między językami.
Wiele generatorów liczb pseudolosowych wykorzystuje metodę liniowego generatora kongruencjalnego. Oto formuła na to, jak otrzymać następną liczbę losową xn+1 na podstawie poprzedniej xn:
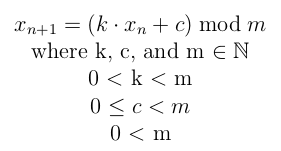
k, c i m to stałe wybrane przez użytkownika do wygenerowania sekwencji. Aby rozpocząć cały proces, wybieramy początkowe ziarno ?₀.
Nie każda implementacja jest taka sama. Na przykład, jeśli wybierzemy k=23, c=51 i m=100 z początkową wartością ziarna ?₀ = 19, zobaczymy jak szybko ta sekwencja zacznie się powtarzać:
function randomNumGenerator(k, c, m, seed, loop) {
let prevNum = seed
let randNums = [seed]
for(let i = 0; i < loop; i++) {
prevNum = (k * prevNum + c) % m
randNums.push(prevNum)
}
console.log(randNums.join())
}
randomNumGenerator(23, 51, 100, 19, 22)
//=>19,88,75,76,99,28,95,36,79,68,15,96,59,8,35,56,39,48,55,16,19,88
20 iteracji wystarczyło, żeby liczba 19 znowu się pojawiła. Ponieważ generujemy liczbę w deterministyczny sposób, sekwencja podwójnych 19 może się pojawić w przewidywalny sposób. Długość tej sub-sekwencji podwójnej liczby określa się mianem okresu. W tym przypadku okres naszej subsekwencji wynosi 20.
Czy mogę być bardziej losowy?
Właściwie to spodziewaliśmy się, że nasza liczba pojawi się ponownie, zwłaszcza że daliśmy jej formułę do generowania liczb. Powinniśmy się raczej zastanawiać nad tym, ile czasu minie zanim dana liczba się powtórzy niż czy stanie się to w ogóle.
Jeżeli zmienimy m na 101, możemy zobaczyć znaczącą zmianę w okresie od 20 do 50.
randomNumGenerator(23, 51, 101, 19, 50)
//=>19,84,64,8,33,2,97,60,17,38,16,15,93,69,22,52,35,48,44,53,58,72,91,23,75,59,95,14,70,45,76,82,18,61,40,62,63,86,9,56,26,43,30,34,25,20,6,88,55,3,19
Jeżeli wybór wartości c i m będzie bardziej zamierzony, możemy zwiększyć długość okresu, dzięki czemu nasze liczby będą na pierwszy rzut oka jeszcze bardziej losowe. Jeśli wybierzemy m do potęgi 2 (na przykład 2³² lub 2⁶⁴) lub jeśli m albo c są liczbami pierwszymi, to wrażenie losowości będzie jeszcze większe.
Odwzorowanie Logistyczne
Możemy dalej zachowywać pozory losowości przez wykorzystanie odwzorowania logistycznego w celu zilustrowania chaosu w prostych, nielinearnych systemach dynamicznych.
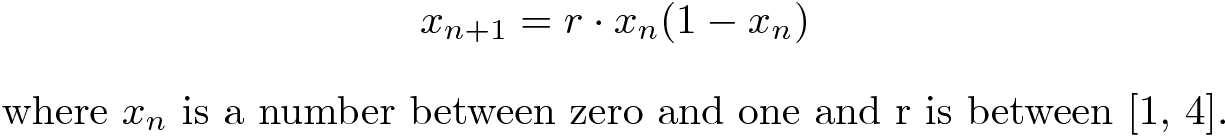
Zaczynając z wartością ziarna między 0 i 1, sekwencja wartości zacznie skakać między 0 a 1 wewnątrz subinterwału [a, b]. Możemy to zmienić za pomocą poniższego:
![]()
Zachowuje się to jednak chaotycznie tylko dla niektórych wartości r, a szczególnie dla ? > 3.56995.
Diagram pajęczyny odwzorowania logistycznego ukazujący chaotyczne zachowanie dla większości wartości r > 3.57 (źródło: Wikipedia)
Pomimo, że systemy są deterministyczne, mała zmiana w początkowej wartości może znacząco zmienić końcowy wynik. To dlatego nigdy nie będzie perfekcyjnej prognozy pogody.
Nawet jeśli jesteśmy nadzwyczaj precyzyjni i opracowujemy w miarę perfekcyjne prognozy pogody, efekt motyla może nagle zmienić kierunek wiatru w taki sposób, że jeszcze trochę poczekamy na słoneczne dni.
Sprawia to, że przewidywanie pewnych wartości jest niemożliwe i pozornie jeszcze bardziej losowe. Powinniśmy jednak jeszcze dokładniej przyjrzeć się chaotycznym schematom.
"Chaos: kiedy teraźniejszość warunkuje przyszłość, ale przybliżona teraźniejszość nie warunkuje w przybliżeniu przyszłości."
Jeżeli nie chcesz w kółko słuchać tej samej piosenki w swojej apce muzycznej, możesz sobie pozwolić na odrobinę chaosu i wprowadzić małe zmiany w losowości, według własnego upodobania.
Nadal nie wierzysz w swój język programowania?
Twój komputer jest właściwie całkiem dobry w generowaniu losowych liczb. Nie mówię tutaj o języku programowania, lecz o samym komputerze. Istnieją liczby, które pojawiają się bardzo losowo, a to dzięki sprzętowym generatorom liczb losowych.
Te liczby są generowane w wyniku fizycznych procesów, a nie algorytmów. Twój system operacyjny ma o wiele większy zasób danych, takich jak temperatura procesora, liczba sekund od ostatniego kliknięcia lub liczba pikseli od ostatniego poruszenia myszką. Takie przypadki są w większości nieprzewidywalne, więc są bliższe losowości.
Skąd mam wiedzieć, że jestem wystarczająco losowy?
Tak po ludzku, jeśli nie rozpoznajemy danego schematu, to coś jest dla nas losowe. Spójrzmy na poniższe ciągi.
string1 = "abcabcabcabcabcabcabcabcabcabc"
string2 = "31832jdksnckjanlml201lakcnqwli"
Z łatwością możemy rozpoznać schemat string1 powtarzający abc, ale ciężko jest zauważyć schemat w string2. W tym przypadku, string2 jest bardziej złożony od string1.
Teoria Chatlina i Kołomogorova pomaga nam zmierzyć ten typ złożoności. Teoria ta zakłada bowiem mierzenie złożoności skończonych sekwencji z punktu widzenia długości najkrótszego programu, który ją wygeneruje.
function generateString1() {
return "abc".repeat(10)
}
function generateString2() {
return "31832jdksnckjanlml201lakcnqwli"
}
W powyższych funkcjach możemy zobaczyć, że generateString1 ma mniej znaków niż generateString2, ale generują one tę samą długość ciągów. Złożoność Kolmogorova ciągu string2 jest większa niż ciągu string1.
Zobaczymy jeszcze więcej jak rozciągniemy długość obu ciągów do 60. Długość generateString1 miałaby tę samą liczbę znaków, ale generateString2 rozciągnęłaby zwracane wyrażenie o dodatkowe 30 znaków.
function generateString1() {
return "abc".repeat(20)
}
//=>abcabcabcabcabcabcabcabcabcabcabcabcabcabcabcabcabcabcabcabc
function generateString2() {
return "31832jdksnckjanlml201lakgcnqwli92jsksmz01pq26hsunx81lz01me92"
}
//=>31832jdksnckjanlml201lakgcnqwli92jsksmz01pq26hsunx81lz01me92
Innymi słowy, według definicji losowości Kolmogorova, losowe ciągi są niewytłumaczalne. Nie możemy wygenerować string2 przez program, który jest krótszy od długości ciągu. Losowość Kolmogorova definiuje ciąg jako coś przypadkowego, jeśli i tylko jeśli jest on krótszy od jakiegokolwiek programu komputerowego, który może ten ciąg stworzyć.