Data Locality w JavaScript

Już za niecały miesiąc, 7 grudnia w Warszawie, startuje konferencja ConFrontJS 2019, której jesteśmy patronem medialnym. Jednym z prelegentów będzie Jonathan Kra. Dziś publikujemy jego artykuł, który może zachęci Cię do udziału w konferencji, aby dowiedzieć się więcej na temat, który prezentuje.
JavaScript jest językiem bardzo wysokopoziomowym. W związku z tym większość programistów nie myśli dużo o tym, jak zmienne są reprezentowane w pamięci. W tym artykule omówię, jak wpływają na procesor i pamięć oraz w jaki sposób sposób dystrybucji i dostępu do danych w JS wpływa na wydajność.
Romantyczny trójkąt
Gdy komputer musi wykonać obliczenia, jednostka obliczeniowa (CPU) potrzebuje danych do przetworzenia. Tak więc, zgodnie z zadaniem, wysyła żądanie pobrania danych z pamięci za pośrednictwem magistrali. Wygląda to tak:
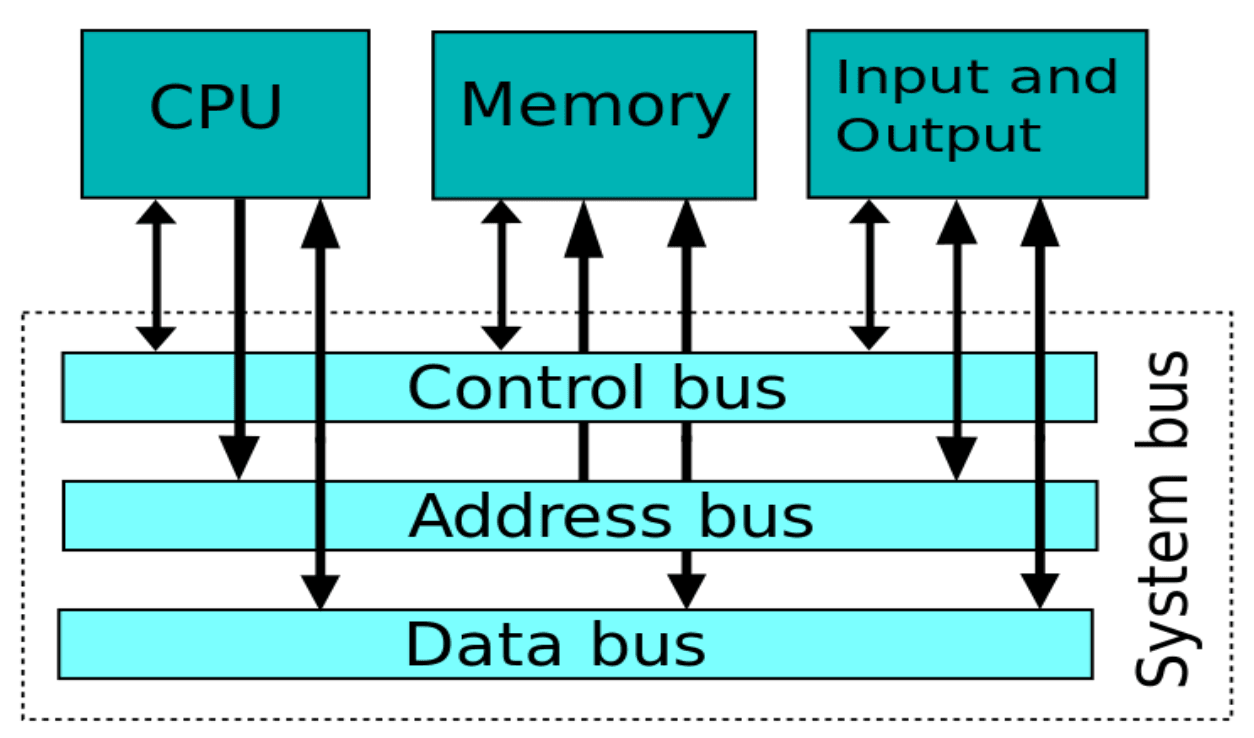
CPU -> BUS -> Memory
Utrzymanie zdrowego związku w trio jest trudne...
Procesor jest znacznie szybszy niż pamięć. Tak więc proces CPU -> BUS -> pamięć -> BUS -> CPU, „marnuje” czas obliczeń. Podczas przeszukiwania pamięci procesor pozostaje bezczynny i nie może nic więcej robić.
Aby zapobiec bezczynności, do systemu dodano pamięć podręczną. Nie będę jej tu szczegółowo omawiać, ani też jej typów. Wystarczy powiedzieć, że pamięć podręczna jest pamięcią wewnętrzną procesora.
Kiedy CPU otrzymuje polecenie do wykonania, najpierw przeszukuje pamięć podręczną, a jeśli danych tam nie ma, wysyła żądanie przez magistralę.
Magistrala z kolei dostarcza żądane dane oraz część pamięci, która je zawiera i zapisuje je w pamięci podręcznej w celu szybkiego odniesienia.
W ten sposób procesor nie będzie miał problemów z tym, że pamięć jest powolna.
Kłótnie są częścią każdego związku
Problemem, który może się pojawić - zwłaszcza gdy mamy do czynienia z przetwarzaniem ogromnych ilości danych - jest nietrafienie pamięci podręcznej, a po angielsku "cache miss".
Brak pamięci podręcznej oznacza, że podczas obliczeń procesor dowiaduje się, że nie ma niezbędnych danych w pamięci podręcznej i musi zażądać jej za pośrednictwem zwykłych kanałów (wolniejszych).
Ok - ale jestem programistą JavaScript, dlaczego mam się tym przejmować?
Dobre pytanie. W większości przypadków nie musisz. Dziś jednak, gdy coraz więcej danych jest przewarzanych na serwerach Node.js, masz większą szansę natrafić na problem z nietrafieniem pamięci podręcznej w czasie iteracji dużych zestawów danych.
Uwierzę, jak zobaczę!!!
Słusznie. Spójrzmy na przykład. Tu mamy klasę o nazwie Boom.
class Boom {
constructor(id) {
this.id = id;
}
setPosition(x, y) {
this.x = x;
this.y = y;
}
}
Ma ona trzy właściwości - id, x and y.
Teraz stwórzmy metodę, która wypełnia x i y.
Skonfigurujmy to:
const ROWS = 1000;
const COLS = 1000;
const repeats = 100;
const arr = new Array(ROWS * COLS).fill(0).map((a, i) => new Boom(i));
Teraz użyjemy tej konfiguracji w metodzie:
function localAccess() {
for (let i = 0; i < ROWS; i++) {
for (let j = 0; j < COLS; j++) {
arr[i * ROWS + j].x = 0;
}
}
}
Dostęp lokalny przechodzi liniowo przez tablicę i ustawia x na 0.
Jeśli powtórzymy tę funkcję 100 razy (spójrz na stałą powtórzeń powyżej), możemy zmierzyć, ile czasu zajmuje wykonanie:
function repeat(cb, type) {
console.log(`%c Started data ${type}`, 'color: red');
const start = performance.now();
for (let i = 0; i < repeats; i++) {
cb();
}
const end = performance.now();
console.log('Finished data locality test run in ', ((end - start) / 1000).toFixed(4), ' seconds');
return end - start;
}
repeat(localAccess, 'Local');
W konsoli zostanie wypisane:

Teraz, zgodnie z tym, czego się dowiedzieliśmy powyżej, możemy powodować błędy w pamięci podręcznej, jeśli przetwarzamy dane, które są daleko w iteracji. Dane, które są daleko, oznaczają dane, których nie ma w sąsiednim indeksie. Oto odpowiednia funkcja:
function farAccess(array) {
let data = arr;
if (array) {
data = array;
}
for (let i = 0; i < COLS; i++) {
for (let j = 0; j < ROWS; j++) {
data[j * ROWS + i].x = 0;
}
}
}
Dodajmy to do naszego testu prędkości:
repeat(localAccess, 'Local');
setTimeout(() => {
repeat(farAccess, 'Non Local');
}, 2000);
A oto wynik końcowy:

Nielokalna iteracja była około 4 razy wolniejsza. Różnica ta będzie rosła wraz z wielkością danych..
Ok, przysięgam, że nigdy tego nie zrobię
Możesz tak nie myśleć, ale ... są przypadki, w których będziesz chciał uzyskać dostęp do tablicy z jakąś konkretną logiką.
Np. otrzymujesz dane z serwera z wierszami i kolumnami, ale musisz je przetworzyć jako kolumny i wiersze. Możesz odwrócić pętlę, jak w przypadku farAccess, ale już wiesz jak to się kończy i jak wpływa na wydajność i może przełożyć się na Twoją aplikację.
O nie! Wszystko stracone!
Istnieją różne rozwiązania tego problemu, ale teraz, gdy już znasz przyczynę tego spadku wydajności, możesz wymyślić rozwiązanie. Musisz zapewnić przetwarzanie danych, które bądą blisko siebie w pamięci.
Kontynuujmy nasz przykład tutaj. Załóżmy, że w naszej aplikacji najczęstszym procesem jest przegląd danych z logiką pokazaną w funkcji farAccess. Chcielibyśmy zoptymalizować dane, aby działały szybko w najbardziej “kosztownym” przypadku pętli.
Zmieńmy trochę nasz kod. Zorganizujemy te same dane w taki sposób:
const diffArr = new Array(ROWS * COLS).fill(0);
for (let col = 0; col < COLS; col++) {
for (let row = 0; row < ROWS; row++) {
diffArr[row * ROWS + col] = arr[col * COLS + row];
}
}
Zatem teraz w diffArr zamiast [0,1,2, ...] wygląda to tak [0,1000,2000, ..., 1, 1001, 2001, ..., 2, 1002, 2002 , ...].
Zmienimy nieco naszą funkcję farAccess, aby uzyskać niestandardową tablicę:
function farAccess(array) {
let data = arr;
if (array) {
data = array;
}
for (let i = 0; i < COLS; i++) {
for (let j = 0; j < ROWS; j++) {
data[j * ROWS + i].x = 0;
}
}
}
A teraz dodajmy scenariusz do naszego testu:
repeat(localAccess, 'Local');
setTimeout(() => {
repeat(farAccess, 'Non Local')
setTimeout(() => {
repeat(() => farAccess(diffArr), 'Non Local Sorted')
}, 2000);
}, 2000);
Teraz wszystkie nasze testy są uruchamiane jeden po drugim z 2-sekundowym opóźnieniem. Uruchomimy to i otrzymamy:

I tak oto zoptymalizowaliśmy nasze dane, by pasowały bardziej do sposobu ich przetwarzania.
Podsumowanie
W tym artykule zademonstrowałem wzorzec projektowy Data Locality. Dowiedzieliśmy się, że za dostęp do struktury danych w sposób, który nie jest zoptymalizowany, możemy zapłacić wydajnością. Następnie zoptymalizowaliśmy dane, aby pasowały do naszego sposobu ich przetwarzania, co znacznie poprawiło wydajność.
Wzorzec Data Locality był kiedyś domeną twórców gier, którzy musieli radzić sobie z wieloma encjami, które są wielokrotnie iterowane. Widząc powyższe wyniki, widzimy, że przetwarzanie danych możliwie lokalnych ma znaczenie nawet w językach wysokopoziomowych, takich jak JavaScript - i to nie tylko w grach.
Dzisiaj, przy tak dużej ilości danych przesyłanych między serwerami lub nawet “wpychanych” do przeglądarek, twórcy aplikacji powinni wziąć pod uwagę wzorce projektowe, które kiedyś były codziennością przy tworzeniu gier - zarówno po stronie serwera, jak i klienta.