

Rahul AgarwalData ScientistWalmart Labs
Popularne metody selekcji cech w Data Science
Poznaj 5 technik selekcji atrybutów, dzięki którym Twoja praca z danymi stanie się łatwiejsza.
Data Science to nauka o algorytmach.
Każdego dnia mam do czynienia z wieloma algorytmami, więc pomyślałem o wymienieniu niektórych z najczęściej używanych algorytmów, by stworzyć nową serię o algorytmach w Data Science.
Ile razy zdarzyło ci się stworzyć wiele atrybutów, a następnie musiałeś wymyślać sposoby, by zmniejszyć ich liczbę?
Czasami używamy korelacji lub metod opartych o drzewa, aby znaleźć ważne atrybuty.
Czy możemy nadać temu procesowi jakąś strukturę?
Ten wpis dotyczy niektórych z bardziej popularnych technik selekcji atrybutów, których można używać podczas pracy z danymi.
Dlaczego selekcja atrybutów?
Zanim przejdziemy dalej, musimy sobie odpowiedzieć na to pytanie. Dlaczego nie pozostawimy wszystkiego algorytmowi ML i nie pozwolimy mu zdecydować, które są najważniejsze?
Cóż istnieją trzy główne powody:
1. Przekleństwo wymiarowości – nadmiernego dopasowania (overfitting)

Jeśli będziemy mieć więcej danych w kolumnach niż wierszy, będziemy mogli idealnie dopasować nasze dane testowe, ale nie przełożymy tego dopasowania na nowe próbki. W ten sposób nie nauczymy się absolutnie niczego.
2. Brzytwa Ockhama
Chcemy, by nasze modele były proste i możliwe do wytłumaczenia. Tracimy możliwość wytłumaczenia czegoś w prosty sposób, gdy mamy za dużo danych.
3. Śmieci na wejściu – śmieci na wyjściu
W większości przypadków będziemy mieć wiele atrybutów, które nie mają znaczenia. Na przykład zmienne Name lub ID. Niska jakość danych wejściowych spowoduje, że dane wyjściowe też będą niskiej jakości.
Tym samym duża ilość atrybutów sprawi, że model będzie nieporęczny, trudniejszy do wdrożenia a jego instalacja na produkcji zajmie dużo czasu.
Co robimy?

Wybieramy tylko przydatne cechy.
Na szczęście Scikit-learn znacznie ułatwia przeprowadzenie procesu selekcji atrybutów. Istnieje wiele sposobów na wybór atrybutów, ale większość z nich można podzielić na trzy główne grupy
- Filtry: Określamy metryki i na ich podstawie filtrujemy atrybuty. Przykładem może być korelacja/chi-kwadrat.
- Metody opakowane: Takie metody traktują selekcję atrybutów jak wyszukiwanie. Na przykład: Rekurencyjna eliminacja cech.
- Metody wbudowane: Metody wbudowane wykorzystują algorytmy, które mają wbudowane metody selekcji cech. Na przykład Lasso i RF mają własne metody, by to osiągnąć.
Wystarczy teorii, czas przedstawić pięć metod selekcji atrybutów, które wybraliśmy.
Spróbujemy to zrobić przy użyciu konkretnego zbioru danych, aby lepiej to zrozumieć.
Użyję bazy danych dotyczącej piłkarzy, aby odkryć, co sprawia, że dobry zawodnik staje się świetnym zawodnikiem.
Nie przejmuj się, jeśli nie znasz terminologii piłkarskiej, postaram się ją ograniczyć do minimum.
Oto kernel Kaggle z kodem do samodzielnego wypróbowania.
Proste przetwarzanie danych
Wstępnie przeprocesowaliśmy dane, usuwając nulle i wykorzystując kodowanie 1 z n. Zmieniliśmy też problem na zagadnienie klasyfikacji za pomocą:y = traindf['Overall']>=87
Użyliśmy wysokiego wyniku “Overall”, aby wytypować świetnych graczy.
Nasza baza danych (x) wygląda następująco, zawiera 223 kolumny.
1. Współczynnik korelacji Pearsona
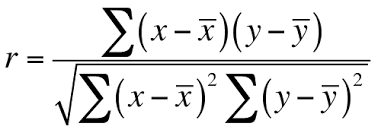
Jest to metoda oparta na filtrach.
Sprawdzamy wartość bezwzględną korelacji Pearsona między cechami docelowymi i numerycznymi naszej bazy. Otrzymujemy najlepsze n-cech na podstawie tego kryterium.
def cor_selector(X, y,num_feats):
cor_list = []
feature_name = X.columns.tolist()
# calculate the correlation with y for each feature
for i in X.columns.tolist():
cor = np.corrcoef(X[i], y)[0, 1]
cor_list.append(cor)
# replace NaN with 0
cor_list = [0 if np.isnan(i) else i for i in cor_list]
# feature name
cor_feature = X.iloc[:,np.argsort(np.abs(cor_list))[-num_feats:]].columns.tolist()
# feature selection? 0 for not select, 1 for select
cor_support = [True if i in cor_feature else False for i in feature_name]
return cor_support, cor_feature
cor_support, cor_feature = cor_selector(X, y,num_feats)
print(str(len(cor_feature)), 'selected features')2. Chi-kwadrat
Jest to kolejna metoda oparta na filtrach.
W tej metodzie obliczamy metrykę chi-kwadrat między wartością docelową a zmienną numeryczną i wybieramy tylko zmienną o maksymalnych wartościach chi-kwadrat.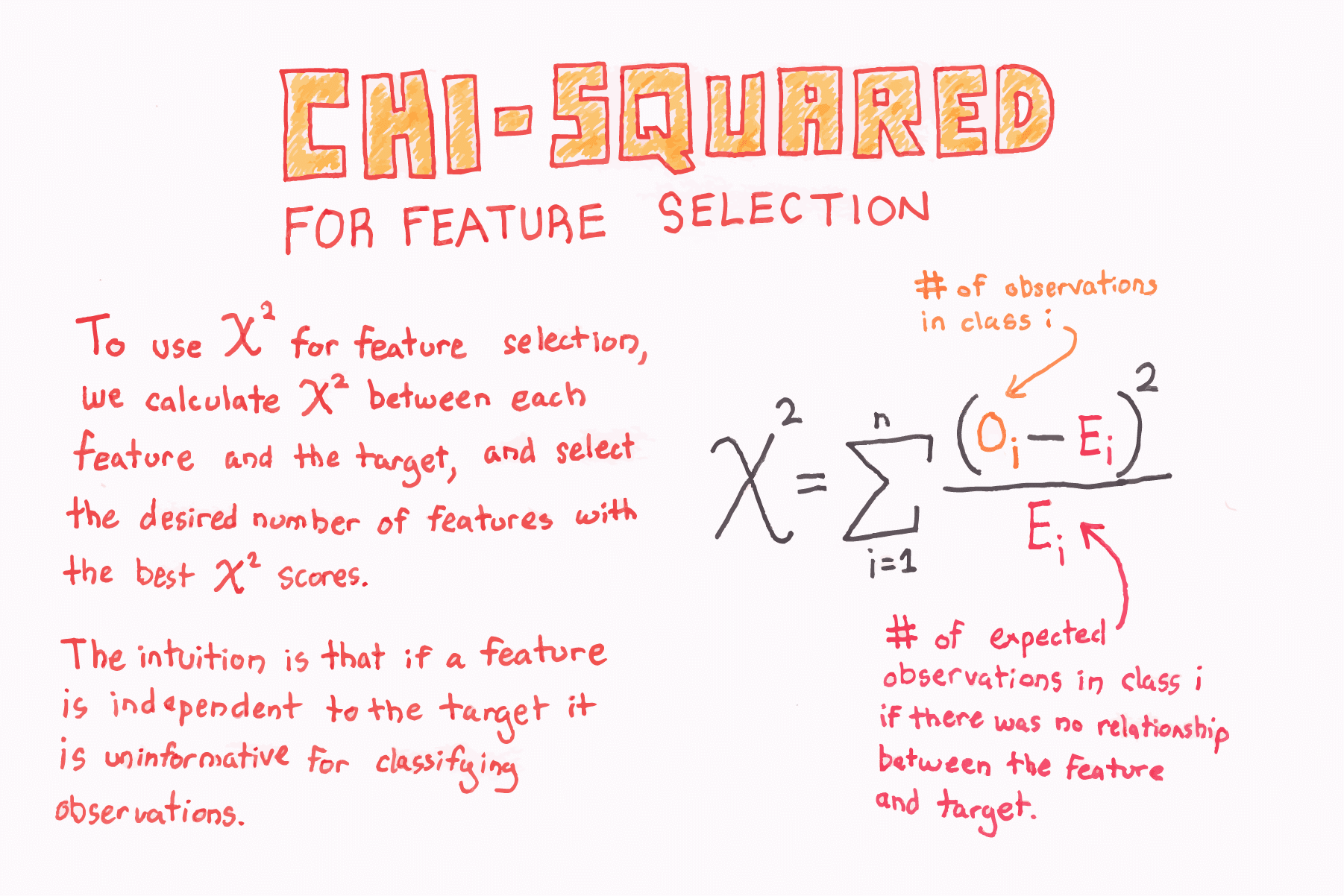
Stwórzmy przykład obliczania statystyki chi-kwadrat dla próbki.
Załóżmy, że w naszej bazie danych znajduje się 75 prawoskrzydłowych i 25 nie piłkarzy, którzy nie są prawoskrzydłowi. Zauważmy, że 40 prawoskrzydłowych jest dobrych, a 35 nie. Czy to oznacza, że prawoskrzydłowy ma wpływ na całość rozgrywki?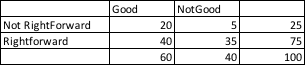
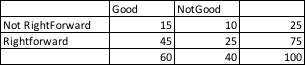
Obserwowane i oczekiwane liczby
Obliczamy wartość chi-kwadrat:
Aby to zrobić, najpierw przyjmujemy wartość, której byśmy się spodziewali w każdym segmencie, gdyby faktycznie nie istniała zależność między dwiema kategoriami zmiennych. To proste. Mnożymy sumę wierszy i sumę kolumn dla każdej komórki i dzielimy ją przez liczbę całkowitą.
Toteż Oczekiwana wartość Dobrych i Nie prawoskrzydłowych = 25(suma wierszy) * 60 (suma kolumn) / 100 (suma obserwacji)
Dlaczego tego oczekujemy? Skoro w bazie danych 25% to zawodnicy niebędący prawoskrzydłowymi, oczekujemy, że 25% z 60 dobrych graczy zaobserwowaliśmy w tej komórce. Oznacza to 15 graczy.
Następnie możemy użyć poniższej formuły do zsumowania wszystkich 4 komórek: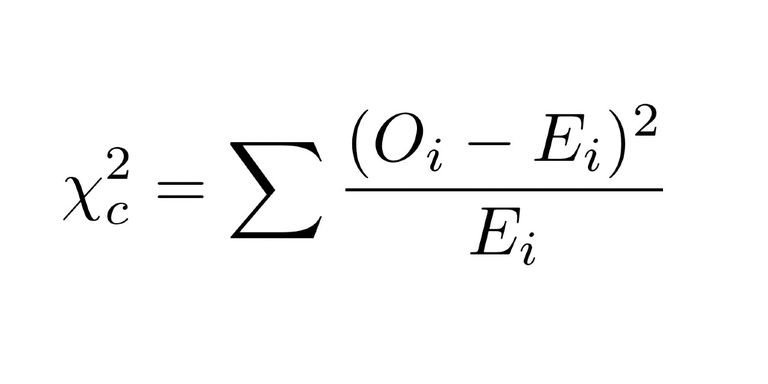
Nie będę tego pokazywać tutaj, ale statystyka chi-kwadrat działa również na zmienne losowe o rozkładzie normalnym.
Możemy uzyskać chi-kwadrat atrybutów z naszych danych jako:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import MinMaxScaler
X_norm = MinMaxScaler().fit_transform(X)
chi_selector = SelectKBest(chi2, k=num_feats)
chi_selector.fit(X_norm, y)
chi_support = chi_selector.get_support()
chi_feature = X.loc[:,chi_support].columns.tolist()
print(str(len(chi_feature)), 'selected features')3. Rekurencyjna eliminacja cech

Jest to metoda opakowana. Jak już wspomniałem wcześniej, metody opakowane traktują selekcję atrybutów jak wyszukiwanie.
Z dokumentacji sklearn:
Celem rekurencyjnej eliminacji cech (RFE) jest selekcja poprzez rekurencyjne uwzględnianie coraz mniejszych zestawów atrybutów. Najpierw estymator jest szkolony na początkowym zestawie atrybutów, a znaczenie każdego z nich uzyskiwane jest albo przez atrybut coef_ lub poprzez atrybut feature_importance_. Następnie, najmniej ważne atrybuty są usuwane z bieżącego zestawu. Tę procedurę powtarza się rekurencyjnie, aż w końcu zostanie osiągnięta potrzebna nam ilość atrybutów do wyboru.
Można się domyślić, że w tej metodzie można użyć dowolnego estymatora. W tym przypadku używamy regresji logistycznej LogisticRegression, a RFE obserwuje atrybut coef_obiektu LogisticRegression.
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
rfe_selector = RFE(estimator=LogisticRegression(), n_features_to_select=num_feats, step=10, verbose=5)
rfe_selector.fit(X_norm, y)
rfe_support = rfe_selector.get_support()
rfe_feature = X.loc[:,rfe_support].columns.tolist()
print(str(len(rfe_feature)), 'selected features')4. Lasso: SelectFromModel

Jest to metoda wbudowana. Jak już wspomniałem wcześniej, metody wbudowane wykorzystują algorytmy, które mają wbudowane metody selekcji cech.
Na przykład Lasso i RF mają własne metody, by to osiągnąć. Lasso Regularizer sprawia, że waga wielu atrybutów zmniejsza się do zera.
Tutaj używamy Lasso do wybierania zmiennych.
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
embeded_lr_selector = SelectFromModel(LogisticRegression(penalty="l1"), max_features=num_feats)
embeded_lr_selector.fit(X_norm, y)
embeded_lr_support = embeded_lr_selector.get_support()
embeded_lr_feature = X.loc[:,embeded_lr_support].columns.tolist()
print(str(len(embeded_lr_feature)), 'selected features')5. Oparte na drzewie: SelectFromModel

Jest to metoda wbudowana. Jak już wspomniałem wcześniej, metody wbudowane wykorzystują algorytmy, które mają wbudowane metody selekcji cech.
Możemy również użyć RandomForest do wybierania atrybutów na podstawie ich ważności.
Ważność każdego atrybutu obliczamy, używając miary nieczystości dla węzłów w drzewie decyzyjnym. W RandomForest ostateczna ważność atrybutu jest średnią ważności wszystkich atrybutów drzewa decyzyjnego.
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
embeded_rf_selector = SelectFromModel(RandomForestClassifier(n_estimators=100), max_features=num_feats)
embeded_rf_selector.fit(X, y)
embeded_rf_support = embeded_rf_selector.get_support()
embeded_rf_feature = X.loc[:,embeded_rf_support].columns.tolist()
print(str(len(embeded_rf_feature)), 'selected features')
Mogliśmy również użyć LightGBM lub obiektu XGBoost o ile posiada atrybut feature_importance_.
from sklearn.feature_selection import SelectFromModel
from lightgbm import LGBMClassifier
lgbc=LGBMClassifier(n_estimators=500, learning_rate=0.05, num_leaves=32, colsample_bytree=0.2,
reg_alpha=3, reg_lambda=1, min_split_gain=0.01, min_child_weight=40)
embeded_lgb_selector = SelectFromModel(lgbc, max_features=num_feats)
embeded_lgb_selector.fit(X, y)
embeded_lgb_support = embeded_lgb_selector.get_support()
embeded_lgb_feature = X.loc[:,embeded_lgb_support].columns.tolist()
print(str(len(embeded_lgb_feature)), 'selected features')Bonus

Dlaczego wybieramy jedną opcję, kiedy możemy wybrać wszystkie?
Odpowiedzią jest fakt, iż przy dużej ilości danych i ograniczeniu czasowym nie będzie to możliwe.
Ale skoro się da, to czemu nie?
# put all selection together
feature_selection_df = pd.DataFrame({'Feature':feature_name, 'Pearson':cor_support, 'Chi-2':chi_support, 'RFE':rfe_support, 'Logistics':embeded_lr_support,
'Random Forest':embeded_rf_support, 'LightGBM':embeded_lgb_support})
# count the selected times for each feature
feature_selection_df['Total'] = np.sum(feature_selection_df, axis=1)
# display the top 100
feature_selection_df = feature_selection_df.sort_values(['Total','Feature'] , ascending=False)
feature_selection_df.index = range(1, len(feature_selection_df)+1)
feature_selection_df.head(num_feats)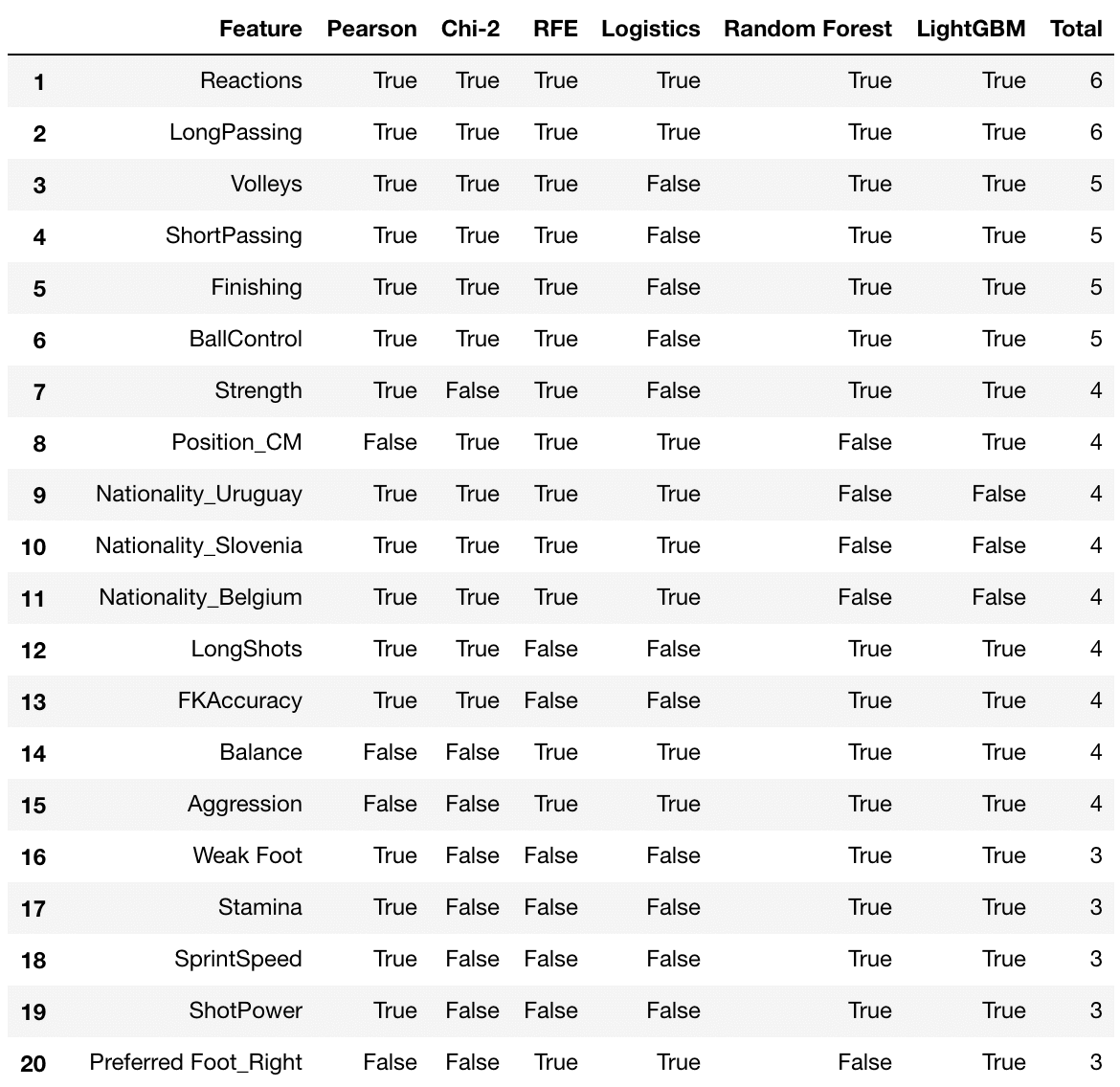
Sprawdzamy, czy otrzymamy atrybuty na podstawie wszystkich metod. W tym przypadku, jak widzimy Reaction i LongPassing są najważniejszymi cechami, które powinien posiadać wysoko oceniany zawodnik. A także zgodnie z oczekiwaniami Ballcontrol i Finishingzajmują najwyższe miejsca.
Podsumowanie
Właściwa selekcja cech jest kluczowym elementem każdego uczenia maszynowego. W naszych modelach dążymy do dokładności, czego nie osiągniemy bez odpowiednich atrybutów.
W tym artykule starałem się wyjaśnić niektóre z najczęściej używanych technik selekcji cech, a także sposób, w jaki ja wybieram dane atrybuty.
Próbowałem także sprawić, by te metody stały się intuicyjnym wyborem, lecz musisz spróbować sam, dowiedzieć się więcej i wypróbować te metody we własnej pracy.
