Strings, Unicode i bajty w Pythonie - wszystko, co chcesz wiedzieć

Prawdopodobnie najważniejszymi nowymi funkcjami wprowadzonymi w Pythonie 3 są nowa implementacja str jako Unicode-by-default oraz ścisła separacja tekstu i danych binarnych.
Obie zmiany są bardzo mile widziane. Szczególnie decyzja o Unicode-by-default pomogła usunąć wiele kłopotów z codziennej pracy programistów (kto kojarzy UnicodeError?). Niemniej jednak, nadal istnieje pewne zamieszanie związane z tą zmianą, więc spróbujmy rzucić trochę światła na tę sytuację.
Troszkę historii
TL;DR Komputery konwertują znaki na liczby zgodnie z powszechnie uznawanym mapowaniem zwanym Unicode. Unicode jest supersetem starszego, ale wciąż aktualnego mapowania zwanego ASCII. Numery te są zapisywane w pamięci i w plikach zgodnie z wieloma różnymi standardami zwanymi kodowaniem. Najpopularniejszym i najbardziej popularnym z tych kodowań jest UTF-8.
W Internecie jest mnóstwo ciekawych artykułów na temat przesłanek stojących za ASCII i Unicode. W dawnych czasach zapisywanie tekstu na komputerze było tak proste, jak przekształcanie każdego znaku w liczbę od 0 do 127, czyli siedem bitów przestrzeni. To wystarczyło do przechowywania wszystkich cyfr, liter, znaków interpunkcyjnych i znaków kontrolnych, jakich potrzebował przeciętny angielski pisarz. Mapowanie to było uzgodnionym standardem zwanym tabelą ASCII.
Większość komputerów w tym czasie używała ośmiu bitów na bajt, co oznacza, że było trochę wolnego miejsca na dodatkowy zestaw 128 znaków dodatkowych. Problem polega na tym, że ten zakres powyżej standardu ASCII był dość wolny, więc różne organizacje zaczęły wykorzystywać go do różnych celów. To skończyło się ogromnym bałaganem różnych tabeli znaków, w których te same liczby reprezentowały różne litery w różnych alfabetach. Dzielenie się dokumentami tekstowymi stało się bałaganem, nie wspominając już o azjatyckich alfabetach z tysiącami liter, które nie mogły zmieścić się w tej 256-symbolicznej przestrzeni w ogóle.
Wówczas Unicode przyszedł z pomocą. Monumentalny wysiłek zaczął mapować każdy znany ludzkości znak i symbol w zestaw tzw. punktów kodowych, czyli liczbę szesnastkową reprezentującą ten symbol. Konsorcjum Unicode zdecydowało, że angielska litera "Q" to U+0055, łacińska litera "è" to U+00E8, cyrylica "й" to U+0439, symbol matematyczny "√" to U+221A i tak dalej. Możesz nawet znaleźć glif uroczej kupki. Ze względu na kompatybilność, pierwsze 128 liczb mapuje te same znaki co ASCII.
Teraz, skoro wszyscy zgodziliśmy się na przypisanie niepowtarzalnego numeru każdemu z wymyślonych glifów, a biorąc pod uwagę, że istnieje tysiące takich zmapowanych symboli, w jaki sposób przechowujemy te punkty kodowe w komputerach? Wielki czy mały endian? Ile bajtów na jeden punkt kodowy? Dwa bajty i potencjalny brak miejsca? Cztery bajty i może trochę marnotrastwa? Zmienna liczba bajtów?
Krótko mówiąc, różne kodowania zostały wymyślone w celu konwersji punktów kodowych na bajty, ale jeden z nich jest prawdopodobnie najlepszy i najczęściej używany: UTF-8. Jest to aktualny złoty standard kodowania Unicode. Nie potrzebujesz niczego innego, no chyba że naprawde wiesz, co robisz.
Nie ma łańcucha bez kodowania
Prawdopodobnie już zauważyłeś kluczową kwestię zapisywania i czytania tekstu na komputerze:
Posiadanie łańcucha bez znajomości jego kodowania nie ma żadnego sensu.
Nie możesz po prostu interpretować i dekodować łańcucha, chyba że znasz jego kodowanie. I choć już zdecydowaliśmy, że UTF-8 jest złotym standardem dekodowania Unicode, być może spotkasz inne kodowania w swojej pracy jako programista i będziesz musiał działać zgodnie z tym standardem.
Jeśli kiedykolwiek znalazłeś dziwne znaki w treści wiadomości e-mail lub na stronie internetowej, to dlatego, że ta wiadomość e-mail lub strona internetowa nie deklarowała kodowania, więc Twój klient pocztowy lub przeglądarka próbują odgadnąć kodowanie i nie spełniają tego warunku.
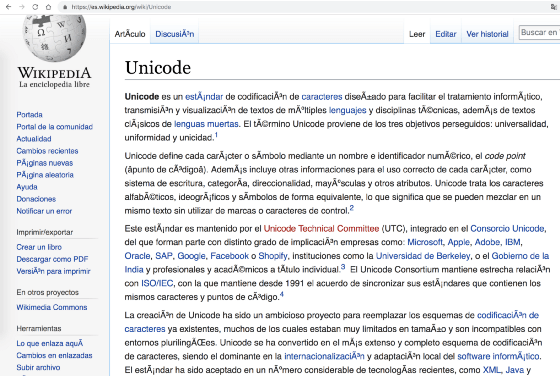
Hiszpańska strona Wikipedii o Unicode załadowana przez Google Chrome z celowo błędnym kodowaniem. Zauważ, że znaki akcentowane są źle dekodowane i renderowane, ponieważ Chrome próbuje dekodować punkty kodowe powyżej 127 w niewłaściwy sposób.
A co z Unicode na Pythonie 3?
Łańcuchy były niezłym bałaganem w Pythonie 2. Domyślnym typem łańcuchów był str, ale był on zapisany jako bytes. Jeśli trzeba było zapisać łańcuchy Unicode w Pythonie 2, trzeba było użyć innego typu, zwanego unicode, zwykle przypinając u do samego łańcucha przy jego tworzeniu. Ta mieszanka bytes i unicode w Pythonie 2 była jeszcze bardziej bolesna, ponieważ Python pozwalał na konwersję typu i niejawne rzutowanie podczas mieszania różnych typów. Było to łatwe do wykonania i najwyraźniej świetne, ale w większości przypadków powodowało ból głowy przy uruchamianiu.
W Pythonie 3 możemy się z tym wszystkim pożegnać. Mamy tu dwa różne i ściśle oddzielone typy:
strodpowiada poprzedniemu typowiunicodew Pythonie 2. Jest on reprezentowany wewnętrznie jako sekwencja punktów kodowych Unicode. Możesz zadeklarować zmiennąstrbez uprzedniego wysyłania łańcucha za pomocąu, ponieważ jest ona teraz domyślna.bytesw przybliżeniu odpowiadają poprzedniemu typowistr(dla częścibytes) w Pythonie 2. Jest to format serializacji binarnej reprezentowany przez ciąg 8-bitowych liczb całkowitych, który nadaje się do przechowywania danych w systemie plików lub przesyłania ich przez Internet. Dlatego też można tworzyć tylkobyteszawierające znaki dosłowne ASCII. Aby zdefiniować zmienną bajtów, po prostu wpiszbdo łańcucha.
Str i bytes mają zupełnie inny zestaw metod. Po prostu nie możesz ich łączyć ani mieszać w żaden sposób:
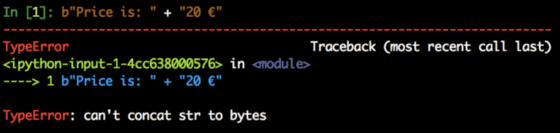
Musisz wszystko oddzielać i to naprawdę dobrze. W Pythonie 3 kod zawiedzie natychmiast, jeśli robisz rzeczy źle, a to oszczędza później wielu sesji debugowania. Niemniej jednak, istnieje bliski związek pomiędzy str i bytes, więc Python pozwala na przełączanie typu za pomocą dwóch dedykowanych metod:
strmoże być zakodowany dobytesprzy użyciu metody encode().bytesmogą być dekodowane dostrza pomocą metody decode().
Obie metody akceptują parametr, którym jest kodowanie używane do kodowania lub dekodowania. Domyślnie dla obu jest to UTF-8.
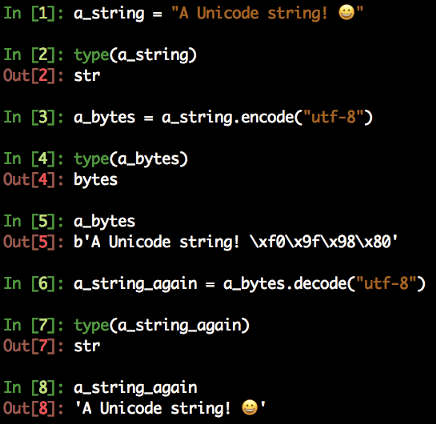
Zauważ, że łańcuchy bytes są poprzedzone znakiem b, gdy są drukowane na interpreterze Pythona.
Obraz jest wart tysiąc słów, więc...:
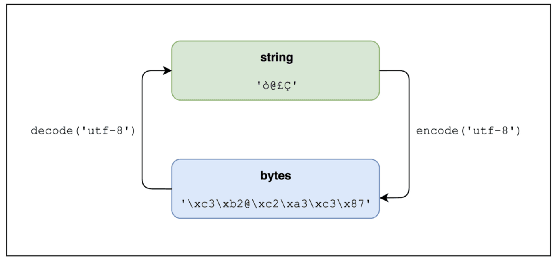
Typ bytes nie ma nieodłącznego kodowania, więc musisz znać kodowanie, jeśli chcesz spróbować i zdekodować, jak widzieliśmy kilka akapitów powyżej. Ponownie: nie możesz udawać, że coś dekodujesz, chyba że znasz jego kodowanie.
Ponadto, nie ma sposobu, aby wnioskować, jakie kodowanie ma bytes. Jest to coś, co musisz wziąć pod uwagę podczas pracy z danymi przychodzącymi do Ciebie z Internetu lub z pliku, którego nie stworzyłeś. Rzeczywiście, dziwne rzeczy zdarzają się, gdy dekodujesz bytes z kodowaniem, które różni się od tego, którego używałeś do kodowania z str, tak jak widzieliśmy to na hiszpańskiej stronie Wikipedii:
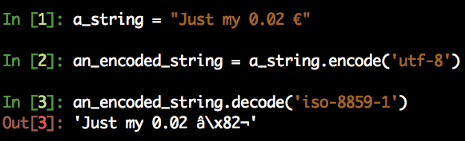
Symbol € zakodowany w UTF-8 jest błędnie konwertowany z powrotem, jeśli dekodujesz za pomocą innego kodowania.
Dostęp do plików w Pythonie 3
Jak można sobie wyobrazić, ma to ogromne konsekwencje dla procesu pisania do i czytania z plików (lub innych form wprowadzania danych) w Pythonie 3.
W Pythonie 3 odczyt plików w trybie r oznacza dekodowanie danych do Unicode i uzyskanie obiektu str. Odczytywanie plików w trybie rb oznacza odczytywanie danych w stanie, w jakim są, bez dekodowania domyślnego i zapisywanie ich jako bytes.
Z tego samego powodu interfejs metody open() zmienił się od czasów Pythona 2 i teraz akceptuje parametr kodowania. Jeśli uważnie przeczytasz, zrozumiesz, że ten parametr jest warty zachodu tylko wtedy, gdy używasz trybu r, gdzie Python dekoduje dane do Unicode i że jest bezużyteczny w rb.
Ważne jest, aby zrozumieć, że Python nie próbuje odgadnąć kodowania. Wykorzystuje raczej kodowanie zwrócone z locale.getpreferredencoding(). Jeśli nie podasz parametru i po prostu polegasz na domyślnych ustawieniach i znajdziesz dziwne rzeczy, jest szansa, że metoda ta zwraca niewłaściwe kodowanie Twoich danych. Znowu: nie ma kodowania, nie ma imprezy.
Najlepsze praktyki i rozwiązywanie problemów z Unicode na Pythonie3
Kanapka z Unicode
Wielki Ned Batchhelder wygłosił wspaniałą prezentację/artykuł, którą z całego serca polecam, jeśli często pracujesz z łańcuchami w Pythonie 3. W tej prezentacji zarzucił terminem Unicode Sandwich, by nazwać doskonałą praktykę do pracy z łańcuchami tekstowymi w Pythonie. Posługując się jego słowami, sugerowane podejście to:
"Bajty na zewnątrz, unicode wewnątrz, kodowanie/dekodowanie na krawędziach".
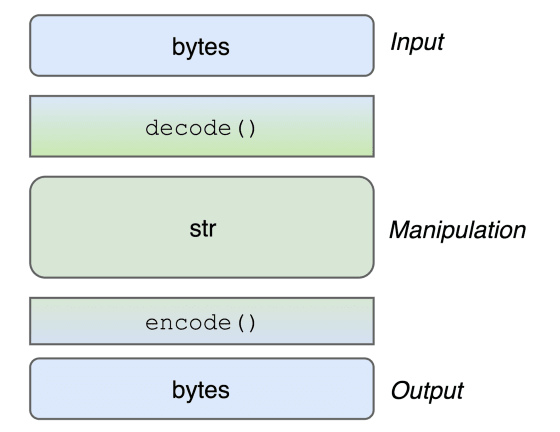
Ideą jest wykorzystanie obiektu str podczas przetwarzania tekstu, a tym samym uzyskanie dostępu do szerokiej gamy metod, które Python udostępnia do przetwarzania łańuchów. Ale kiedy masz do czynienia z zewnętrznymi rzeczami, takimi jak API, to użyj bytes. To podejście jest tak doskonałe, że niektóre biblioteki mogą nawet wyabstrahować cały proces za Ciebie i pozwolić na wejście/wyjście Unicode, przekształcając to wszystko w str wewnętrznie.
2 * 3 = sześć
Istnieje jeszcze dużo kodu w Pythonie 2, a niektóre biblioteki nadal obsługują zarówno Py2 jak i Py3 w inny sposób, nawet w tej samej wersji.
Benjamin Peterson opracował doskonałą bibliotekę kompatybilności zwaną sixthat, która opakowuje różnice między dwiema głównymi wersjami Pythona. Jak można sobie wyobrazić, ma też mnóstwo narzędzi do zarządzania łańcuchami. Warto to sprawdzić i zobaczyć, w jaki sposób może Ci pomóc w stworzeniu kompatybilnego kodu.
Nie mieszaj str i bytes
Większość błędów pojawiających się podczas pracy z łańcuchami jest spowodowana próbą wymieszania str i bytes. Zapewne jest to dla Ciebie bardziej typowe, jeśli masz spore doświadczenie z Pythonem w świecie 2.x, gdzie granice między tymi dwoma typami są znacznie bardziej rozmyte. Jeśli nadal występują błędy, takie jak:
TypeError: a bytes-like object is required, not 'str'
i tym podobne, sprawdź, czy używasz właściwej metody na właściwym obiekcie. Sprawdź również, czy plik został otwarty prawidłowo, zgodnie z Twoimi potrzebami. Łatwo jest nie zdać testu ograniczającego, który przez lata zdawałeś na Pythonie 2:
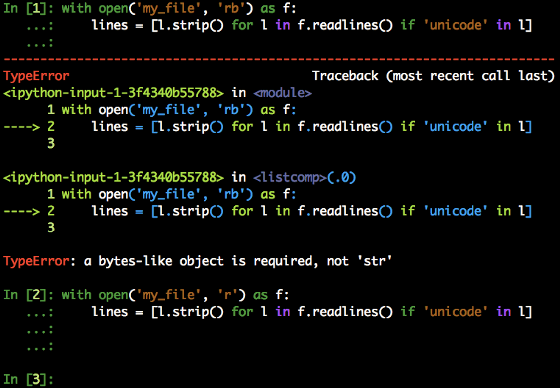
Warunek if <string> in <object> na linii jeden nie powiedzie się, ponieważ otworzyliśmy plik w trybie binarnym, a następnie poprosiliśmy Pythona, aby skonfrontował łańcuch z obiektem bytes. Otwarcie pliku w trybie odczytu, a nawet dekodowanie bytes do str zrobi swoje.
Znaj swoje kodowanie
Pozwól mi jeszcze raz podkreślić tę koncepcję: nie możesz udawać, że dekodujesz bytes, jeśli nie znasz kodowania. Te informacje nie mogą być wiarygodnie wywnioskowane z samych bytes i musisz je otrzymać lub udostępnić, jeśli robisz I/O z plikami lub API, nad którymi nie masz kontroli. Jak widzieliśmy wcześniej, jest szansa, że Python i tak zdekoduje twoje bytes, jeśli przekażesz mu niewłaściwe kodowanie, ale prawdopodobnie wyjdą z tego jakieś śmieci.
Bonusowy akapit: io.stringIO i io.bytesIO
Ściśle związane z głównymi zmianami dotyczącymi łańcuchów, które właśnie widzieliśmy, jest kolejna zmiana obejmująca dawne moduły Python2 StringIO i cStringIO.
Oprócz niewielkich różnic w API i wydajności pomiędzy tymi dwoma modułami, StringIO i cStringIO opierały się na podejściu Py2 do zarządzania łańcuchami, akceptując albo Unicode albo łańcuch bajtów. Ponieważ Py3 ma radykalnie różne podejście, te dwa moduły zostały usunięte i zastąpione przez dwie nowe klasy wewnątrz modułu io. Ich użycie jest dość proste:
io.BytesIO()akceptuje łańcuch bajtów jako argument.io.StringIO()akceptuje łańcuch Unicode i kodowanie jako argumenty.
Tak po prostu. Zwracają one dwa obiekty podobne do plików, które można używać normalnie i zgodnie z modelem kanapki. Więcej na ten temat można przeczytać w oficjalnej dokumentacji.
Oryginał tekstu w języku angielskim przeczytasz tutaj.