Przewidywanie z użyciem regresji liniowej z TensorFlow.js

Znowu pada deszcz. Minęły 3 tygodnie od czasu, gdy ostatni raz widziałeś słońce. Męczy Cię to zimno i nieprzyjemne uczucie samotności i melancholii. Głos w Twojej głowie staje się coraz głośniejszy.
- "WEŹ SIĘ PRZEPROWADŹ".
W porządku, jesteś gotów to zrobić. Tylko dokąd? Pamiętaj, że jesteś prawie spłukany.
Twój przyjaciel opowiadał Ci o tym mieście Ames w stanie Iowa i utknęło Ci to w głowie. Po szybkim wyszukiwaniu okazało się, że pogoda jest tam przyjemna przez cały rok. Jest trochę deszczu, ale naprawdę niewiele. Super!
Na szczęście, znasz taki zestaw danych na Kaggle, który może pomóc Ci dowiedzieć się, ile może kosztować Twój wymarzony dom. Zajmijmy się tym!
Uruchom pełny kod źródłowy tego samouczka w swojej przeglądarce:
Dane dotyczące cen domów
Nasze dane pochodzą z Ceny domów: Wyzwanie związane z zaawansowanymi technikami regresji od Kaggle.
Z 79 zmiennymi objaśniającymi opisującymi (prawie) każdy aspekt domów mieszkalnych w Ames, to zadanie stawia przed Tobą wyzwanie przewidzenia ostatecznej ceny każdego domu. Oto podzbiór danych, które wykorzystamy w naszym modelu:
OverallQual- ocenia jakość materiałów i wykończenia domu (0 - 10).GrLivArea- Powierzchnia mieszkalna (bez piwnicy) w stopach kwadratowychGarageCars- liczba samochodów, która zmieści się w garażuTotalBsmtSF- Powierzchnia piwnicy w stopach kwadratowychFullBath- W pełni wyposażone łazienki na powierzchni mieszkalnejYearBuilt- Data budowySalePrice- cena sprzedaży nieruchomości w dolarach (staramy się to przewidzieć)
Użyjmy Papa Parse do załadowania danych treningowych:
const prepareData = async () => {
const csv = await Papa.parsePromise(
"https://raw.githubusercontent.com/curiousily/Linear-Regression-with-TensorFlow-js/master/src/data/housing.csv"
);
return csv.data;
};const data = await prepareData();Poszukiwania
Spróbujmy lepiej zrozumieć nasze dane. Po pierwsze - ocena jakości każdego domu:
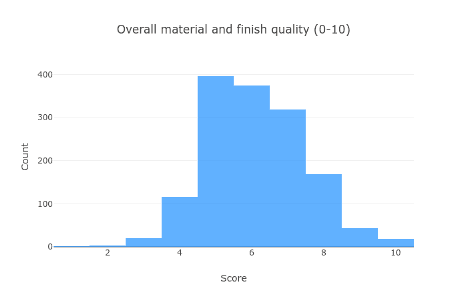
Większość domów jest średniej jakości, ale jest wśród nich więcej "dobrych" niż "złych".
Zobaczmy, jakich są rozmiarów:
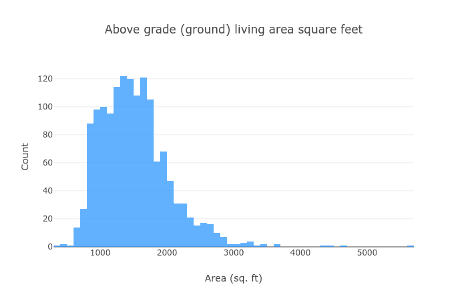
Większość domów mieści się w przedziale 1.000-2.000 (90-180 m2), a niektóre z nich są większe.
Spójrzmy na rok, w którym zostały zbudowane:
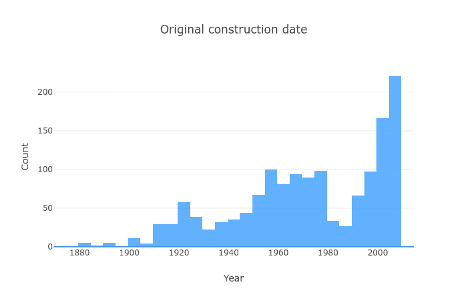
Mimo, że jest wiele domów, które zostały zbudowane niedawno, mamy znacznie bardziej rozciągniętą dystrybucję.
Jak bardzo cena jest powiązana z rokiem?
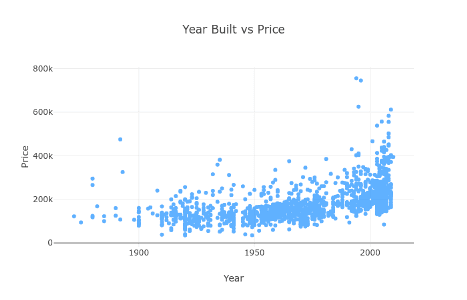
Wygląda na to, że nowsze domy są droższe. Czyżby nikt nie lubił starych ale dobrze wykonanych?
Oh ok, ale wyższa jakość powinna być równa wyższej cenie, prawda?
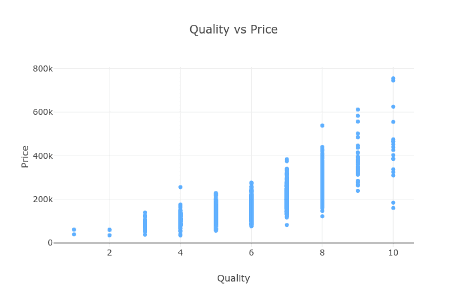
Ogólnie tak, ale spójrz na jakość 10. Niektóre z nich są stosunkowo tanie. Jakieś pomysły, dlaczego tak jest?
Czy większy dom jest równy wyższej cenie?
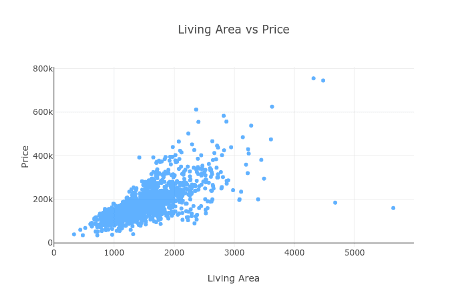
Wygląda na to, że możemy zacząć budować nasz model przewidywania cen przy użyciu powierzchni mieszkalnej!
Regresja liniowa
Modele regresji liniowej zakładają, że istnieje relacja liniowa (może być modelowana przy użyciu linii prostej) pomiędzy zależną zmienną ciągłą Y i jedną lub więcej zmiennych objaśniających (niezależnych) X.
W naszym przypadku, będziemy używać takich cech jak living area (X), aby przewidzieć sale price (Y) domu.
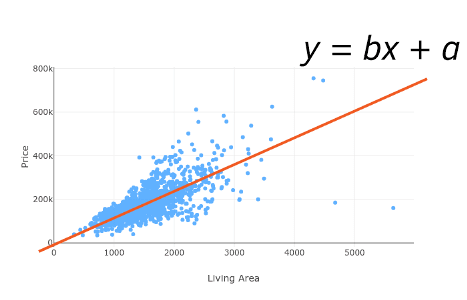
Prosta regresja liniowa
Prosta regresja liniowa jest modelem, który posiada jedną niezależną zmienną X. Jest zdefiniowana jako:
![]()
Gdzie a i b są parametrami, poznanymi podczas szkolenia naszego modelu. X to dane, których będziemy używać do treningu naszego modelu, b kontroluje nachylenie i a punkt przecięcia z osią y.
Wielokrotna regresja liniowa
Naturalnym przedłużeniem modelu prostej regresji liniowej jest model wielowymiarowy. Definiowana jest jako:
![]()
gdzie x1, x2, ...., xn to cechy z naszego zbioru danych, a w1, w2, ...., wn to parametry poznane.
Funkcja straty
Zamierzamy użyć średniej kwadratowej błędów (RSME), aby zmierzyć, jak daleko od rzeczywistych cen domów są nasze przewidywania. To jest dane przez:
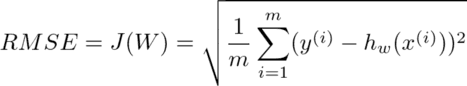
gdzie hipoteza/prognoza hw jest zdefiniowana jako:
![]()
Przetwarzanie wstępne danych
Obecnie nasze dane znajdują się w tablicy obiektów JS. Musimy przekształcić je w tensorsy i użyć ich do treningu naszego modelu (modeli). Oto kod:
const createDataSets = (data, features, categoricalFeatures, testSize) => {
const X = data.map(r =>
features.flatMap(f => {
if (categoricalFeatures.has(f)) {
return oneHot(!r[f] ? 0 : r[f], VARIABLE_CATEGORY_COUNT[f]);
}
return !r[f] ? 0 : r[f];
})
);
const X_t = normalize(tf.tensor2d(X));
const y = tf.tensor(data.map(r => (!r.SalePrice ? 0 : r.SalePrice)));
const splitIdx = parseInt((1 - testSize) * data.length, 10);
const [xTrain, xTest] = tf.split(X_t, [splitIdx, data.length - splitIdx]);
const [yTrain, yTest] = tf.split(y, [splitIdx, data.length - splitIdx]);
return [xTrain, xTest, yTrain, yTest];
};
Przechowujemy nasze cechy w X, a etykiety w y. Następnie przekształcamy dane na tensory i dzielimy je na zestawy danych szkoleniowych i testowych.
Cechy kategoryczne
Niektóre cechy naszego zbioru danych są kategoryczne/wyliczeniowe. Na przykład GarageCars może być w zakresie 0-5.
Pozostawienie kategorii reprezentowanych jako liczby całkowite w naszym zbiorze danych może wprowadzić ukrytą zależność od kolejności. Coś, co nie istnieje w przypadku zmiennych kategorycznych.
Będziemy używać kodowania typu 1 z n z TensorFlow, aby utworzyć wektor liczb całkowitych dla każdej wartości w celu przerwania kolejności. Po pierwsze, określmy, ile różnych wartości ma każda kategoria:
const VARIABLE_CATEGORY_COUNT = {
OverallQual: 10,
GarageCars: 5,
FullBath: 4
};
Użyjemy tf.oneHot() do konwersji wartości indywidualnych na reprezentację one-hot:
const oneHot = (val, categoryCount) =>
Array.from(tf.oneHot(val, categoryCount).dataSync());
Zauważ, że funkcja createDataSets() akceptuje parametr zwany categoricalFeatures, który powinien być zestawem (set). Użyjemy tego, aby sprawdzić, czy powinniśmy przetwarzać tę cechę jako kategoryczną.
Skalowanie cech
Skalowanie cech służy do przekształcenia wartości cech w (podobny) zakres. Skalowanie cech pomoże naszemu modelowi (modelom) szybciej się uczyć, ponieważ do jego treningu używamy metody gradientu prostego.
Wykorzystajmy jedną z najprostszych metod skalowania cech - normalizację min-max:
const normalize = tensor =>
tf.div(
tf.sub(tensor, tf.min(tensor)),
tf.sub(tf.max(tensor), tf.min(tensor))
);
Metoda ta przeskalowuje zakres wartości w zakresie [0, 1].
Przewidywanie cen domów
Teraz, gdy wiemy o modelu (modelach) regresji liniowej, możemy spróbować przewidzieć ceny domów w oparciu o posiadane dane. Zacznijmy od prostego:
Budowa modelu prostej regresji liniowej
Zapakujemy proces szkolenia w funkcję, którą będziemy mogli ponownie wykorzystać w naszym przyszłym modelu (modelach):
const trainLinearModel = async (xTrain, yTrain) => {
...
}trainLinearModel przyjmuje cechy i etykiety dla naszego modelu. Zdefiniujmy model regresji liniowej przy użyciu TensorFlow:
const model = tf.sequential();
model.add(
tf.layers.dense({
inputShape: [xTrain.shape[1]],
units: xTrain.shape[1]
})
);
model.add(tf.layers.dense({ units: 1 }));
Ponieważ TensorFlow.js nie oferuje funkcji straty RMSE, użyjemy MSE i wyciągniemy z niego pierwiastek kwadratowy. Będziemy również śledzić średni błąd bezwzględny (MAE) pomiędzy prognozami a rzeczywistymi cenami:
model.compile({
optimizer: tf.train.sgd(0.001),
loss: "meanSquaredError",
metrics: [tf.metrics.meanAbsoluteError]
});
Oto proces szkolenia:
const trainLogs = [];
const lossContainer = document.getElementById("loss-cont");
const accContainer = document.getElementById("acc-cont");
await model.fit(xTrain, yTrain, {
batchSize: 32,
epochs: 100,
shuffle: true,
validationSplit: 0.1,
callbacks: {
onEpochEnd: async (epoch, logs) => {
trainLogs.push({
rmse: Math.sqrt(logs.loss),
val_rmse: Math.sqrt(logs.val_loss),
mae: logs.meanAbsoluteError,
val_mae: logs.val_meanAbsoluteError
});
tfvis.show.history(lossContainer, trainLogs, ["rmse", "val_rmse"]);
tfvis.show.history(accContainer, trainLogs, ["mae", "val_mae"]);
}
}
});
Szkolimy się na 100 epok, wcześniej przetasowujemy dane i wykorzystujemy 10% z nich do walidacji. RMSE i MAE są wizualizowane po każdej epoce.
Szkolenie
Nasz model prostej regresji liniowej wykorzystuje funkcję GrLivArea:
const [xTrainSimple, xTestSimple, yTrainSimple, yTestIgnored] = createDataSets(
data,
["GrLivArea"],
new Set(),
0.1
);
const simpleLinearModel = await trainLinearModel(xTrainSimple, yTrainSimple);
Nie mamy cech kategorycznych, więc zostawiamy ten zestaw jako pusty. Spójrzmy jak sobie radzimy:
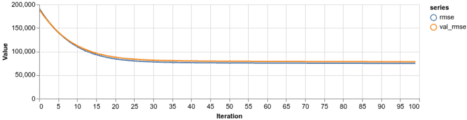
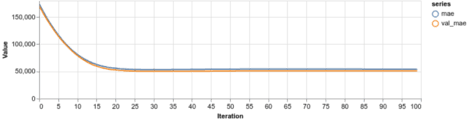
Budowa modelu wielokrotnej regresji liniowej (Multiple Linear Regression)
Mamy dużo więcej danych, których jeszcze nie wykorzystaliśmy. Zobaczmy, czy to pomoże poprawić prognozy:
const features = [
"OverallQual",
"GrLivArea",
"GarageCars",
"TotalBsmtSF",
"FullBath",
"YearBuilt"
];
const categoricalFeatures = new Set(["OverallQual", "GarageCars", "FullBath"]);
const [xTrain, xTest, yTrain, yTest] = createDataSets(
data,
features,
categoricalFeatures,
0.1
);
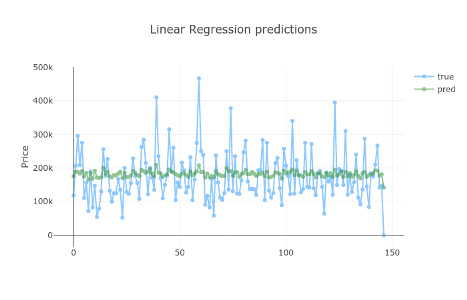
Używamy wszystkich cech w naszym zbiorze danych i przekazujemy zestaw tych, które są kategoryczne. Poszło lepiej?
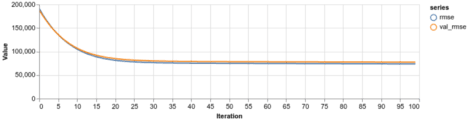
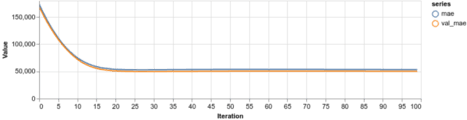
Ogólnie rzecz biorąc, oba modele działają na mniej więcej tym samym poziomie. Tym razem zwiększenie złożoności modelu nie dało nam większej dokładności.
Ocena
Innym sposobem oceny naszych modeli jest sprawdzenie ich przewidywań w odniesieniu do danych testowych. Zacznijmy od prostej regresji liniowej:
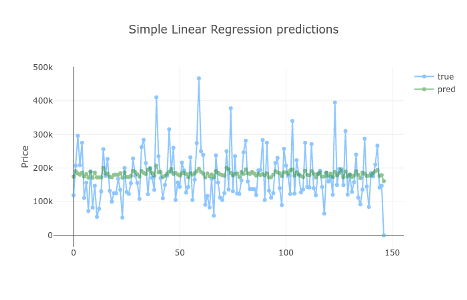
W jaki sposób dodanie większej ilości danych poprawiło prognozy?
Cóż, nie poprawiło. Ponownie, posiadanie bardziej złożonego modelu przeszkolonego z większą ilością danych nie zapewniło lepszej wydajności.
Podsumowanie
Udało Ci się! Zbudowałeś dwa modele regresji liniowej, które przewidują cenę domu w oparciu o zestaw cech. Zrobiłeś również:
- Skalowanie cech dla szybszego treningu modeli,
- Przekształcanie zmiennych kategorycznych w reprezentacje typu 1 z n,
- Implementację RMSE (w oparciu o MSE) w celu oceny dokładności.
Odnośniki
Obsługa danych kategorii w modelach uczenia maszynowego
Informacje na temat skalowania i normalizacji cech
RMSE: Błąd Root_Mean_Square_Error.
Oryginał tekstu w języku angielskim przeczytasz tutaj.