

Zuzanna Jakubanis Content manager Bulldogjob.pl
Po Data Science Summit 2018
Przypominam II edycję największego polskiego wydarzenia data science oraz dlaczego warto, by każdy, kto chociaż w najmniejszym stopniu interesuje się tą dziedziną w DSS uczestniczył.
DSS 2018 to wydarzenie adresowane do profesjonalistów: analityków, architektów, administratorów, programistów, a także osób zainteresowanych data science. Wydaje mi się, że krąg odbiorców można by znacznie poszerzyć. Eksperci od data science zaprezentowali, co udało im się zrobić lub nad czym akurat pracują, a mogło to zaabsorbować wiele osób dotychczas niespecjalnie śledzących nowinki z branży.
Wyróżnię dwie dziedziny: computer vision i natural language processing (NLP), co - mam nadzieję - zainspiruje do poszerzenia wiedzy, zmotywuje do poznania sylwetek prelegentów i zapisania DSS 2019 w kalendarzu na przyszły rok.
Computer Vision & Deep Learning
FinAi.pl rozwija platformę kredytową, która ma skrócić i ułatwić drogę klienta do uzyskania kredytu. Data scientists Adam Kordeczka i Michał Stolarczyk skupili się na module odpowiedzialnym za automatyczne potwierdzenie tożsamości klienta. Przybliżyli swoje podejście do budowy modelu analizującego żywotność twarzy i drogę, jaką przeszli od jupyter notebooks do wdrożenia modelu na środowisko produkcyjne, wykorzystując MS Azure, Docker, TensorFlow Serving.
Częścią procedury weryfikacyjnej platformy jest analiza selfie zrobionego przez użytkownika. Twórcy modelu musieli zastanowić się nad potencjalnymi próbami obejścia tego etapu - np. poprzez podłożenie zdjęcia twarzy lub ekranu ze zdjęciem twarzy z liczną trójwymiarową strukturą. Zanim zbudowali model musieli zebrać dwie klasy: tzw. „żywą” - czyli nagrania rzeczywistych osób przed aparatem telefonu - i klasę „martwą”, czyli np. pokazywane przed aparatem wydruki. Liczyli różnice między odległościami na dwóch kolejnych klatkach, żeby uchwycić faktyczną zmianę. Założyli, że w przypadku prawdziwego wizerunku użytkownika zmiana ta będzie duża.
Człowiek intensywnie się rusza, gdy nagle widzi swoją twarz z bliskiej odległości i zaczyna się przygotowywać do zrobienia selfie. Stąd Kordeczka i Stolarczyk wybierali dziesięć pierwszych klatek z procesu. Po wdrożeniu nieco się rozczarowali, gdy część osób żywych dostawała bardzo niskie score’y.

Wynika to z tego, że wiele z nich nie rusza się w ogóle - widać tylko krótkie mrugnięcie, które może być niewychwytywalne przy wyborze pięciu klatek z jednej sekundy. Dlatego specjaliści rozważają kilka opcji - np. interakcję z użytkownikiem. Mogą układać ruch jego gałek ocznych dzięki wyświetleniu elementu, który użytkownik będzie śledził, albo wykrywać ruch warg po prośbie o przedstawienie się. Inny scenariusz to przetestowanie innych bibliotek, które dostarczają większą liczbę landmarków.

Identyfikacja punktów charakterystycznych twarzy, czyli landmarków
Testowali różne architektury sieci neuronowych, przy czym najlepsze okazały się sieci bazujące na sieciach rekurencyjnych. Tym, co je wyróżnia są zależności dynamiczne na każdym etapie działania. Zmiana stanu jednego neuronu początkuje zmianę stanu energetycznego całej sieci.
Co dalej?
Wypadałoby teraz coś zrobić, bo celem życia nie jest tylko robienie modeli - czasem warto by je jakoś wykorzystać. Przychodzi CTO i mówi: OK, pokażcie jak to działa - a więc fizyk i matematyk, korzystając ze swoich nieograniczonych zdolności informatycznych, zaczynają tworzyć serwisy, które będą działać na produkcji.
- śmiali się prelegenci i przeszli do opisu wdrożenia. Napisali aplikację we Flasku, która miała w środku model, i opakowali wszystko w Dockera, który umożliwia umieszczenie dowolnej aplikacji razem z jej zależnościami w kontenerze i późniejsze uruchomienie na prawie każdym środowisku unixowym. Ale… zaczęli więcej czytać dokumentację Flaska, a tam pojawiło się kluczowe zdanie: Serwer wbudowany Flaska nie jest dobry na produkcję.
Kordeczka i Stolarczyk bardzo dokładnie opisywali swoją pracę, błędy i usprawnienia. Moduł odpytujący Cognitive Services MS Azure napisali w C# - m.in dlatego, że implementacja na produkcji jest łatwiejsza, niż w Pythonie, a do języka są już gotowe klienty napisane do Cognitive Services, które pozwalają na odpytywanie o landmarki. Po implementacji liczba błędów zmalała z 97 procent do niecałego jednego procenta. Doszli do wniosku, że jeśli coś da się napisać w języku innym niż Python, to trzeba to zrobić.
W ramach podsumowania przedstawili równanie sukcesu, w którym +- to operator zależny od czasu, który ostatecznie dał na szczęście plus:
mikroserwis na śmietnik + matematyk + miesiąc developmentu +- zły CTO = mikroserwis użyteczny
Matematyk i fizyk przyznali, że sporo się nauczyli. Np. tego, że jeśli chodzi o modelowanie - trudno o dostępne rozwiązania opensource’owe, a tych komercyjnych jest bardzo mało i dopiero zaczynają się pojawiać. Natomiast wprowadzenie modeli na produkcję to droga bardzo wyboista.
A co, jeśli się zestarzeję po roku, albo coś mi się stanie z twarzą, wpadnę pod pociąg?
- znalazł się czas na pytania i odpowiedź, która spotkała się ze śmiechem całej sali:
To nie będzie kredytu.
Kordeczka i Stolarczyk potwierdzili, że są już w pewnym stopniu gotowi, by zmierzyć się z tym problemem. Uwzględniają różnicę wieku między zdjęciem z dowodu, a selfie. Przyznają, że tak skrajnych przypadków jest bardzo dużo.
Natural Language Processing (NLP)
Rozpoznawanie emocji w tekście przy użyciu metod głębokiego uczenia to prelekcja o wdrożeniowej pracy magisterskiej, poprowadzona przez Pawła Pollaka z Applica.ai. Anna Wróblewska (MiNI PW, Applica.ai) w ramach wstępu opowiedziała o tym, jak zaproponowała zagadnienie w firmie, a wraz z szefem biznesowym wymyśliła temat. Prace nad projektem przebiegały już po dołączeniu do zespołu Pawła Pollaka.
Pollak wspomniał o problemie z wydźwiękiem w tekście. Z wydźwiękiem płytkim - pozytywnym, neutralnym lub negatywnym - kłopotów nie ma - jak np. w pozytywnym zdaniu:
Nie spodziewałem się, że to będzie takie fajne.
Trudniej jest z wydźwiękiem głębokim, kiedy definiujemy jakie emocje mogą być obecne w tekście. Można spierać się, czy w tekście mamy do czynienia z radością i zaskoczeniem, czy może z optymizmem. Z pomocą przyszły gotowe teorie emocji - Roberta Plutchika i Paula Ekmana.
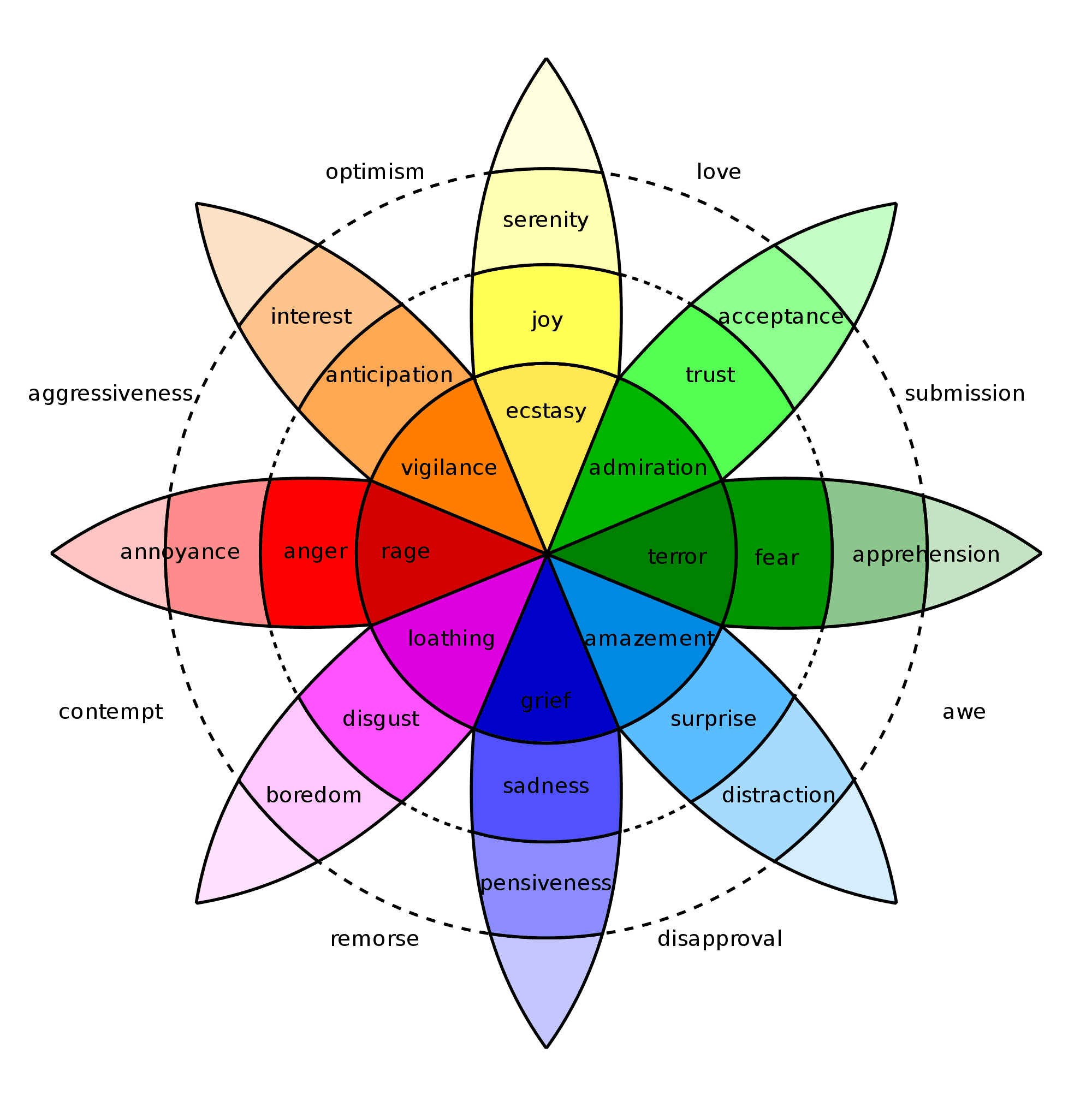
Koło emocji Plutchika opisuje relacje między różnymi emocjami
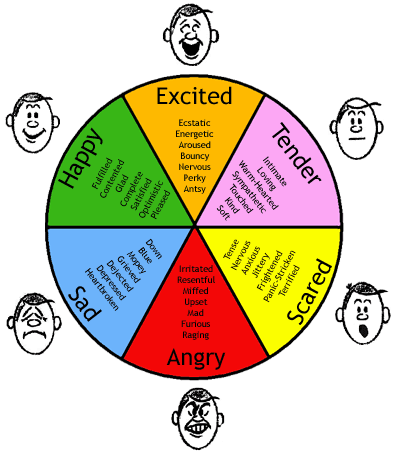
Koło podstawowych emocji i ich mimicznych ekspresji Ekmana
Pollak wspomniał, że słowosieć ma w sobie komponent dotyczący emocji. Są one podporządkowane do zdań, które funkcjonują jako przykłady do jednostek leksykalnych. Komponent zawiera też ponad 30 tysięcy zdań obiektywnych, bez emocji, typowo słownikowych, informacyjnych. Rozkład nie jest szczególnie zrównoważony, a szczególnie mało jest zdań z oczekiwaniem i zaskoczeniem, co nieco odbija się na wynikach. Z wyciągnięciem przykładów słowosieci były trudności- są w xmlu, ale mają w środku dziwne tagi. Pollak podkreślił, że zdania bywają trochę sztuczne i nieżyciowe, choć poprawne pod względem języka, dlatego przydatne. Przykład:
Nie wiem jak wytrzymać z tym abnegatem. Mydło i dezodorant są jego największymi wrogami.

Bardziej życiowym zbiorem były głównie komentarze, ale też artykuły z polskich serwisów informacyjnych.
Podsumowaliśmy Internet, szczególnie polski. Specyfika zbioru to dużo złości i wstrętu.
- mówił Pollak. Teksty zostały zebrane przez zespół lingwistów Applica, którzy wybierali zbiór i oceniali jakie emocje i w jakim stopniu w nim występują. Znów przydatna okazała się teoria Plutchika i widoczne w niej stopniowanie, bo daną emocję można było przyporządkować do konkretnych liczb od zera do trzech, a później wykorzystać wartość binarną. Dobra instrukcja była tu podstawą. O wiele częściej korzysta się z gotowych zbiorów lub pomiarów, niż dokonuje własnych.
Później Pollak opisał metody reprezentacji tekstu, który jest gotowy do przekazania sieci: metodę niskopoziomową i word embeddings, znane po polsku coraz częściej jako zanurzenia słów. Zespół wykorzystał sieci konwolucyjne, co jest przeniesieniem pomysłu z analizy obrazów. Okazało się to najlepszym rozwiązaniem.
Rozpoznawanie emocji dotyczyło dłuższych tekstów, które mają już około 20 słów. Zdefiniowanie emocji na poziomie pojedynczego słowa byłoby trudne. Znaczenie może być bardzo różne, jak np. w przypadku słowa ,,dobra”, które często niesłusznie podnosi score dla radości - tłumaczył Pollak. Przyznał, że najtrudniejsze w całym procesie było ustalenie sposobu zbierania zbioru przez lingwistów i uzyskanie ich zgodności, która ostatecznie, na poziomie jednej emocji, wynosiła 80 procent. Mówił też możliwości usprawnienia projektu.
Na koniec padło pytanie i odpowiedź, która nakreśliła plany na przyszłość. Co z szerszym kontekstem? Zdanie może być przecież efektem większej wypowiedzi i nabierać np. negatywnego charakteru, w odróżnieniu od wyizolowanego zdania. Z racji tego, że emocje i analiza tekstu są bardzo kontekstowe, jest to bardzo dobra ścieżka rozwoju.
Więcej informacji o DSS 2018 oraz pełna lista wystąpień w ramach wszystkich ścieżek: https://dssconf.pl/
